 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Multi-sensor Fusion Perception for Embodied AI: Background, Methods, Challenges and Prospects
Jun 24, 2025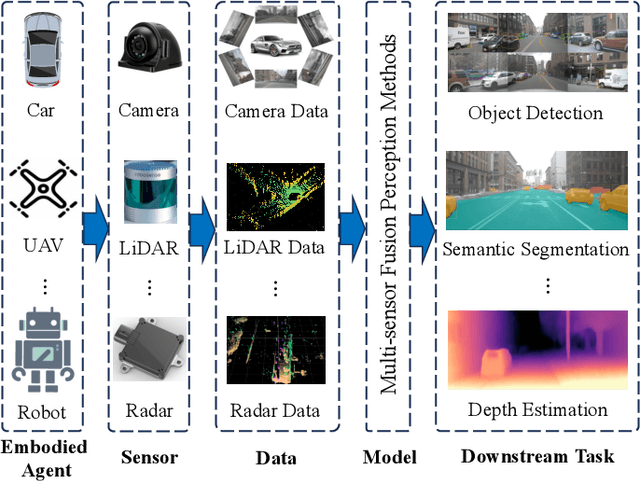
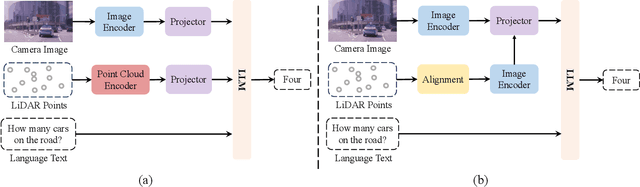
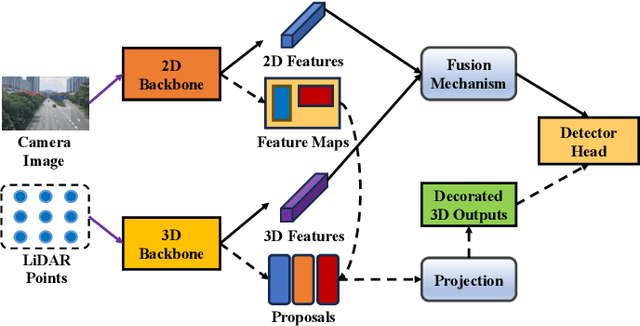
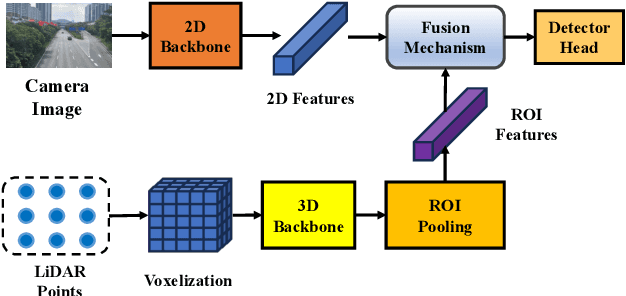
Multi-sensor fusion perception (MSFP) is a key technology for embodied AI, which can serve a variety of downstream tasks (e.g., 3D object detection and semantic segmentation) and application scenarios (e.g., autonomous driving and swarm robotics). Recently, impressive achievements on AI-based MSFP methods have been reviewed in relevant surveys. However, we observe that the existing surveys have some limitations after a rigorous and detailed investigation. For one thing, most surveys are oriented to a single task or research field, such as 3D object detection or autonomous driving. Therefore, researchers in other related tasks often find it difficult to benefit directly. For another, most surveys only introduce MSFP from a single perspective of multi-modal fusion, while lacking consideration of the diversity of MSFP methods, such as multi-view fusion and time-series fusion. To this end, in this paper, we hope to organize MSFP research from a task-agnostic perspective, where methods are reported from various technical views. Specifically, we first introduce the background of MSFP. Next, we review multi-modal and multi-agent fusion methods. A step further, time-series fusion methods are analyzed. In the era of LLM, we also investigate multimodal LLM fusion methods. Finally, we discuss open challenges and future directions for MSFP. We hope this survey can help researchers understand the important progress in MSFP and provide possible insights for future research.
MVP-CBM:Multi-layer Visual Preference-enhanced Concept Bottleneck Model for Explainable Medical Image Classification
Jun 14, 2025The concept bottleneck model (CBM), as a technique improving interpretability via linking predictions to human-understandable concepts, makes high-risk and life-critical medical image classification credible. Typically, existing CBM methods associate the final layer of visual encoders with concepts to explain the model's predictions. However, we empirically discover the phenomenon of concept preference variation, that is, the concepts are preferably associated with the features at different layers than those only at the final layer; yet a blind last-layer-based association neglects such a preference variation and thus weakens the accurate correspondences between features and concepts, impairing model interpretability. To address this issue, we propose a novel Multi-layer Visual Preference-enhanced Concept Bottleneck Model (MVP-CBM), which comprises two key novel modules: (1) intra-layer concept preference modeling, which captures the preferred association of different concepts with features at various visual layers, and (2) multi-layer concept sparse activation fusion, which sparsely aggregates concept activations from multiple layers to enhance performance. Thus, by explicitly modeling concept preferences, MVP-CBM can comprehensively leverage multi-layer visual information to provide a more nuanced and accurate explanation of model decisions. Extensive experiments on several public medical classification benchmarks demonstrate that MVP-CBM achieves state-of-the-art accuracy and interoperability, verifying its superiority. Code is available at https://github.com/wcj6/MVP-CBM.
* 7 pages, 6 figures,
Learning Efficient and Generalizable Graph Retriever for Knowledge-Graph Question Answering
Jun 11, 2025Large Language Models (LLMs) have shown strong inductive reasoning ability across various domains, but their reliability is hindered by the outdated knowledge and hallucinations. Retrieval-Augmented Generation mitigates these issues by grounding LLMs with external knowledge; however, most existing RAG pipelines rely on unstructured text, limiting interpretability and structured reasoning. Knowledge graphs, which represent facts as relational triples, offer a more structured and compact alternative. Recent studies have explored integrating knowledge graphs with LLMs for knowledge graph question answering (KGQA), with a significant proportion adopting the retrieve-then-reasoning paradigm. In this framework, graph-based retrievers have demonstrated strong empirical performance, yet they still face challenges in generalization ability. In this work, we propose RAPL, a novel framework for efficient and effective graph retrieval in KGQA. RAPL addresses these limitations through three aspects: (1) a two-stage labeling strategy that combines heuristic signals with parametric models to provide causally grounded supervision; (2) a model-agnostic graph transformation approach to capture both intra- and inter-triple interactions, thereby enhancing representational capacity; and (3) a path-based reasoning strategy that facilitates learning from the injected rational knowledge, and supports downstream reasoner through structured inputs. Empirically, RAPL outperforms state-of-the-art methods by $2.66\%-20.34\%$, and significantly reduces the performance gap between smaller and more powerful LLM-based reasoners, as well as the gap under cross-dataset settings, highlighting its superior retrieval capability and generalizability. Codes are available at: https://github.com/tianyao-aka/RAPL.
A Sample Efficient Conditional Independence Test in the Presence of Discretization
Jun 10, 2025In many real-world scenarios, interested variables are often represented as discretized values due to measurement limitations. Applying Conditional Independence (CI) tests directly to such discretized data, however, can lead to incorrect conclusions. To address this, recent advancements have sought to infer the correct CI relationship between the latent variables through binarizing observed data. However, this process inevitably results in a loss of information, which degrades the test's performance. Motivated by this, this paper introduces a sample-efficient CI test that does not rely on the binarization process. We find that the independence relationships of latent continuous variables can be established by addressing an over-identifying restriction problem with Generalized Method of Moments (GMM). Based on this insight, we derive an appropriate test statistic and establish its asymptotic distribution correctly reflecting CI by leveraging nodewise regression. Theoretical findings and Empirical results across various datasets demonstrate that the superiority and effectiveness of our proposed test. Our code implementation is provided in https://github.com/boyangaaaaa/DCT
MoRE: A Mixture of Low-Rank Experts for Adaptive Multi-Task Learning
May 28, 2025



With the rapid development of Large Language Models (LLMs), Parameter-Efficient Fine-Tuning (PEFT) methods have gained significant attention, which aims to achieve efficient fine-tuning of LLMs with fewer parameters. As a representative PEFT method, Low-Rank Adaptation (LoRA) introduces low-rank matrices to approximate the incremental tuning parameters and achieves impressive performance over multiple scenarios. After that, plenty of improvements have been proposed for further improvement. However, these methods either focus on single-task scenarios or separately train multiple LoRA modules for multi-task scenarios, limiting the efficiency and effectiveness of LoRA in multi-task scenarios. To better adapt to multi-task fine-tuning, in this paper, we propose a novel Mixture of Low-Rank Experts (MoRE) for multi-task PEFT. Specifically, instead of using an individual LoRA for each task, we align different ranks of LoRA module with different tasks, which we named low-rank experts. Moreover, we design a novel adaptive rank selector to select the appropriate expert for each task. By jointly training low-rank experts, MoRE can enhance the adaptability and efficiency of LoRA in multi-task scenarios. Finally, we conduct extensive experiments over multiple multi-task benchmarks along with different LLMs to verify model performance. Experimental results demonstrate that compared to traditional LoRA and its variants, MoRE significantly improves the performance of LLMs in multi-task scenarios and incurs no additional inference cost. We also release the model and code to facilitate the community.
Position: Mechanistic Interpretability Should Prioritize Feature Consistency in SAEs
May 26, 2025Sparse Autoencoders (SAEs) are a prominent tool in mechanistic interpretability (MI) for decomposing neural network activations into interpretable features. However, the aspiration to identify a canonical set of features is challenged by the observed inconsistency of learned SAE features across different training runs, undermining the reliability and efficiency of MI research. This position paper argues that mechanistic interpretability should prioritize feature consistency in SAEs -- the reliable convergence to equivalent feature sets across independent runs. We propose using the Pairwise Dictionary Mean Correlation Coefficient (PW-MCC) as a practical metric to operationalize consistency and demonstrate that high levels are achievable (0.80 for TopK SAEs on LLM activations) with appropriate architectural choices. Our contributions include detailing the benefits of prioritizing consistency; providing theoretical grounding and synthetic validation using a model organism, which verifies PW-MCC as a reliable proxy for ground-truth recovery; and extending these findings to real-world LLM data, where high feature consistency strongly correlates with the semantic similarity of learned feature explanations. We call for a community-wide shift towards systematically measuring feature consistency to foster robust cumulative progress in MI.
A General Knowledge Injection Framework for ICD Coding
May 24, 2025
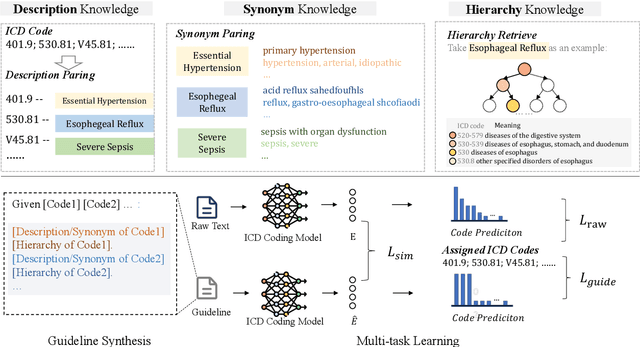
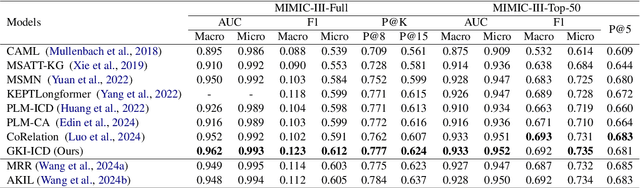
ICD Coding aims to assign a wide range of medical codes to a medical text document, which is a popular and challenging task in the healthcare domain. To alleviate the problems of long-tail distribution and the lack of annotations of code-specific evidence, many previous works have proposed incorporating code knowledge to improve coding performance. However, existing methods often focus on a single type of knowledge and design specialized modules that are complex and incompatible with each other, thereby limiting their scalability and effectiveness. To address this issue, we propose GKI-ICD, a novel, general knowledge injection framework that integrates three key types of knowledge, namely ICD Description, ICD Synonym, and ICD Hierarchy, without specialized design of additional modules. The comprehensive utilization of the above knowledge, which exhibits both differences and complementarity, can effectively enhance the ICD coding performance. Extensive experiments on existing popular ICD coding benchmarks demonstrate the effectiveness of GKI-ICD, which achieves the state-of-the-art performance on most evaluation metrics. Code is available at https://github.com/xuzhang0112/GKI-ICD.
Does Representation Intervention Really Identify Desired Concepts and Elicit Alignment?
May 24, 2025Representation intervention aims to locate and modify the representations that encode the underlying concepts in Large Language Models (LLMs) to elicit the aligned and expected behaviors. Despite the empirical success, it has never been examined whether one could locate the faithful concepts for intervention. In this work, we explore the question in safety alignment. If the interventions are faithful, the intervened LLMs should erase the harmful concepts and be robust to both in-distribution adversarial prompts and the out-of-distribution (OOD) jailbreaks. While it is feasible to erase harmful concepts without degrading the benign functionalities of LLMs in linear settings, we show that it is infeasible in the general non-linear setting. To tackle the issue, we propose Concept Concentration (COCA). Instead of identifying the faithful locations to intervene, COCA refractors the training data with an explicit reasoning process, which firstly identifies the potential unsafe concepts and then decides the responses. Essentially, COCA simplifies the decision boundary between harmful and benign representations, enabling more effective linear erasure. Extensive experiments with multiple representation intervention methods and model architectures demonstrate that COCA significantly reduces both in-distribution and OOD jailbreak success rates, and meanwhile maintaining strong performance on regular tasks such as math and code generation.
The Third Pillar of Causal Analysis? A Measurement Perspective on Causal Representations
May 23, 2025Causal reasoning and discovery, two fundamental tasks of causal analysis, often face challenges in applications due to the complexity, noisiness, and high-dimensionality of real-world data. Despite recent progress in identifying latent causal structures using causal representation learning (CRL), what makes learned representations useful for causal downstream tasks and how to evaluate them are still not well understood. In this paper, we reinterpret CRL using a measurement model framework, where the learned representations are viewed as proxy measurements of the latent causal variables. Our approach clarifies the conditions under which learned representations support downstream causal reasoning and provides a principled basis for quantitatively assessing the quality of representations using a new Test-based Measurement EXclusivity (T-MEX) score. We validate T-MEX across diverse causal inference scenarios, including numerical simulations and real-world ecological video analysis, demonstrating that the proposed framework and corresponding score effectively assess the identification of learned representations and their usefulness for causal downstream tasks.
On the Thinking-Language Modeling Gap in Large Language Models
May 19, 2025



System 2 reasoning is one of the defining characteristics of intelligence, which requires slow and logical thinking. Human conducts System 2 reasoning via the language of thoughts that organizes the reasoning process as a causal sequence of mental language, or thoughts. Recently, it has been observed that System 2 reasoning can be elicited from Large Language Models (LLMs) pre-trained on large-scale natural languages. However, in this work, we show that there is a significant gap between the modeling of languages and thoughts. As language is primarily a tool for humans to share knowledge and thinking, modeling human language can easily absorb language biases into LLMs deviated from the chain of thoughts in minds. Furthermore, we show that the biases will mislead the eliciting of "thoughts" in LLMs to focus only on a biased part of the premise. To this end, we propose a new prompt technique termed Language-of-Thoughts (LoT) to demonstrate and alleviate this gap. Instead of directly eliciting the chain of thoughts from partial information, LoT instructs LLMs to adjust the order and token used for the expressions of all the relevant information. We show that the simple strategy significantly reduces the language modeling biases in LLMs and improves the performance of LLMs across a variety of reasoning tasks.