 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Stochastic Optimization under a General Variance Condition
Jan 30, 2023Distributed stochastic optimization has drawn great attention recently due to its effectiveness in solving large-scale machine learning problems. However, despite that numerous algorithms have been proposed with empirical successes, their theoretical guarantees are restrictive and rely on certain boundedness conditions on the stochastic gradients, varying from uniform boundedness to the relaxed growth condition. In addition, how to characterize the data heterogeneity among the agents and its impacts on the algorithmic performance remains challenging. In light of such motivations, we revisit the classical FedAvg algorithm for solving the distributed stochastic optimization problem and establish the convergence results under only a mild variance condition on the stochastic gradients for smooth nonconvex objective functions. Almost sure convergence to a stationary point is also established under the condition. Moreover, we discuss a more informative measurement for data heterogeneity as well as its implications.
CEDAS: A Compressed Decentralized Stochastic Gradient Method with Improved Convergence
Jan 14, 2023



In this paper, we consider solving the distributed optimization problem over a multi-agent network under the communication restricted setting. We study a compressed decentralized stochastic gradient method, termed ``compressed exact diffusion with adaptive stepsizes (CEDAS)", and show the method asymptotically achieves comparable convergence rate as centralized SGD for both smooth strongly convex objective functions and smooth nonconvex objective functions under unbiased compression operators. In particular, to our knowledge, CEDAS enjoys so far the shortest transient time (with respect to the graph specifics) for achieving the convergence rate of centralized SGD, which behaves as $\mathcal{O}(nC^3/(1-\lambda_2)^{2})$ under smooth strongly convex objective functions, and $\mathcal{O}(n^3C^6/(1-\lambda_2)^4)$ under smooth nonconvex objective functions, where $(1-\lambda_2)$ denotes the spectral gap of the mixing matrix, and $C>0$ is the compression-related parameter. Numerical experiments further demonstrate the effectiveness of the proposed algorithm.
Think Twice: A Human-like Two-stage Conversational Agent for Emotional Response Generation
Jan 12, 2023Towards human-like dialogue systems, current emotional dialogue approaches jointly model emotion and semantics with a unified neural network. This strategy tends to generate safe responses due to the mutual restriction between emotion and semantics, and requires rare emotion-annotated large-scale dialogue corpus. Inspired by the "think twice" behavior in human dialogue, we propose a two-stage conversational agent for the generation of emotional dialogue. Firstly, a dialogue model trained without the emotion-annotated dialogue corpus generates a prototype response that meets the contextual semantics. Secondly, the first-stage prototype is modified by a controllable emotion refiner with the empathy hypothesis. Experimental results on the DailyDialog and EmpatheticDialogues datasets demonstrate that the proposed conversational outperforms the comparison models in emotion generation and maintains the semantic performance in automatic and human evaluations.
Training Robots to Evaluate Robots: Example-Based Interactive Reward Functions for Policy Learning
Dec 17, 2022



Physical interactions can often help reveal information that is not readily apparent. For example, we may tug at a table leg to evaluate whether it is built well, or turn a water bottle upside down to check that it is watertight. We propose to train robots to acquire such interactive behaviors automatically, for the purpose of evaluating the result of an attempted robotic skill execution. These evaluations in turn serve as "interactive reward functions" (IRFs) for training reinforcement learning policies to perform the target skill, such as screwing the table leg tightly. In addition, even after task policies are fully trained, IRFs can serve as verification mechanisms that improve online task execution. For any given task, our IRFs can be conveniently trained using only examples of successful outcomes, and no further specification is needed to train the task policy thereafter. In our evaluations on door locking and weighted block stacking in simulation, and screw tightening on a real robot, IRFs enable large performance improvements, even outperforming baselines with access to demonstrations or carefully engineered rewards. Project website: https://sites.google.com/view/lirf-corl-2022/
Aligning Recommendation and Conversation via Dual Imitation
Nov 05, 2022



Human conversations of recommendation naturally involve the shift of interests which can align the recommendation actions and conversation process to make accurate recommendations with rich explanations. However, existing conversational recommendation systems (CRS) ignore the advantage of user interest shift in connecting recommendation and conversation, which leads to an ineffective loose coupling structure of CRS. To address this issue, by modeling the recommendation actions as recommendation paths in a knowledge graph (KG), we propose DICR (Dual Imitation for Conversational Recommendation), which designs a dual imitation to explicitly align the recommendation paths and user interest shift paths in a recommendation module and a conversation module, respectively. By exchanging alignment signals, DICR achieves bidirectional promotion between recommendation and conversation modules and generates high-quality responses with accurate recommendations and coherent explanations. Experiments demonstrate that DICR outperforms the state-of-the-art models on recommendation and conversation performance with automatic, human, and novel explainability metrics.
Deep 360$^\circ$ Optical Flow Estimation Based on Multi-Projection Fusion
Jul 27, 2022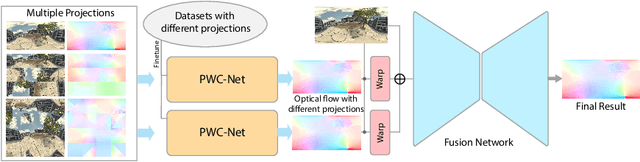


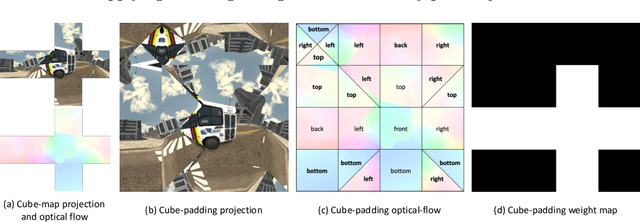
Optical flow computation is essential in the early stages of the video processing pipeline. This paper focuses on a less explored problem in this area, the 360$^\circ$ optical flow estimation using deep neural networks to support increasingly popular VR applications. To address the distortions of panoramic representations when applying convolutional neural networks, we propose a novel multi-projection fusion framework that fuses the optical flow predicted by the models trained using different projection methods. It learns to combine the complementary information in the optical flow results under different projections. We also build the first large-scale panoramic optical flow dataset to support the training of neural networks and the evaluation of panoramic optical flow estimation methods. The experimental results on our dataset demonstrate that our method outperforms the existing methods and other alternative deep networks that were developed for processing 360{\deg} content.
Label Adversarial Learning for Skeleton-level to Pixel-level Adjustable Vessel Segmentation
May 07, 2022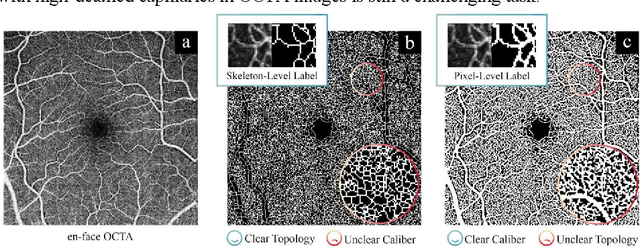
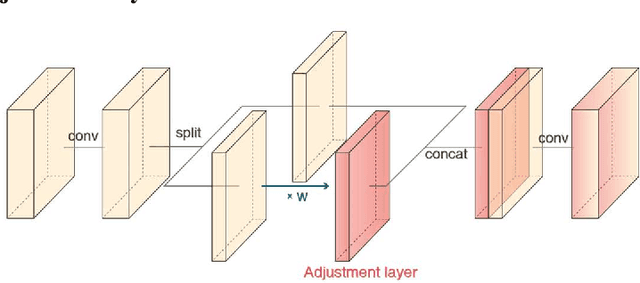

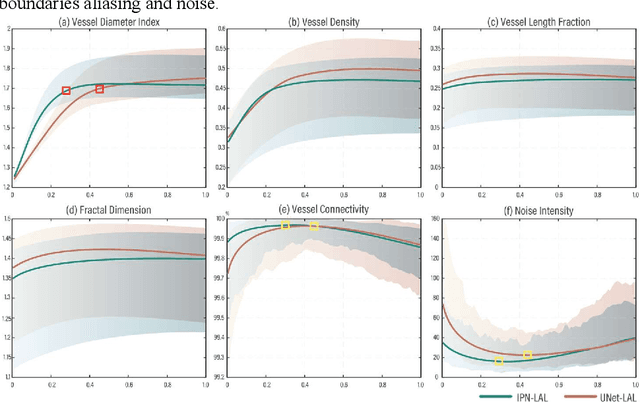
You can have your cake and eat it too. Microvessel segmentation in optical coherence tomography angiography (OCTA) images remains challenging. Skeleton-level segmentation shows clear topology but without diameter information, while pixel-level segmentation shows a clear caliber but low topology. To close this gap, we propose a novel label adversarial learning (LAL) for skeleton-level to pixel-level adjustable vessel segmentation. LAL mainly consists of two designs: a label adversarial loss and an embeddable adjustment layer. The label adversarial loss establishes an adversarial relationship between the two label supervisions, while the adjustment layer adjusts the network parameters to match the different adversarial weights. Such a design can efficiently capture the variation between the two supervisions, making the segmentation continuous and tunable. This continuous process allows us to recommend high-quality vessel segmentation with clear caliber and topology. Experimental results show that our results outperform manual annotations of current public datasets and conventional filtering effects. Furthermore, such a continuous process can also be used to generate an uncertainty map representing weak vessel boundaries and noise.
Accurate calibration of multi-perspective cameras from a generalization of the hand-eye constraint
Feb 08, 2022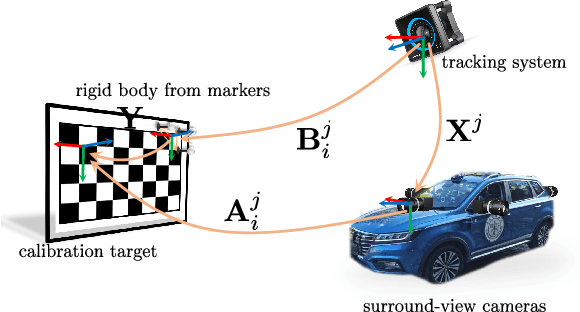
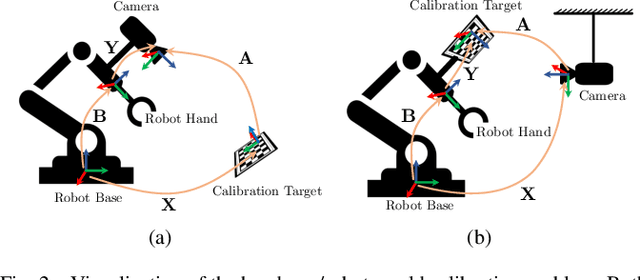
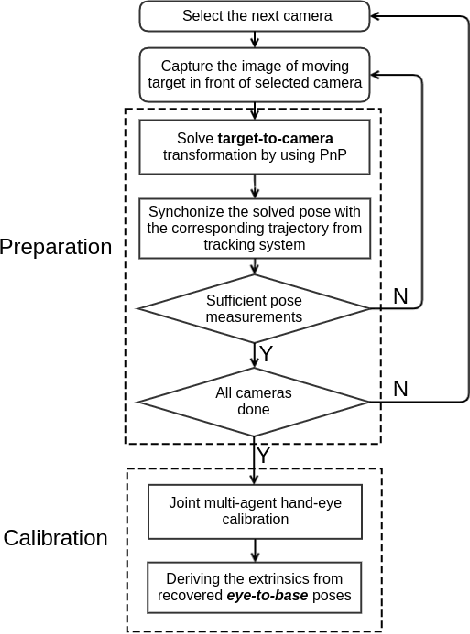
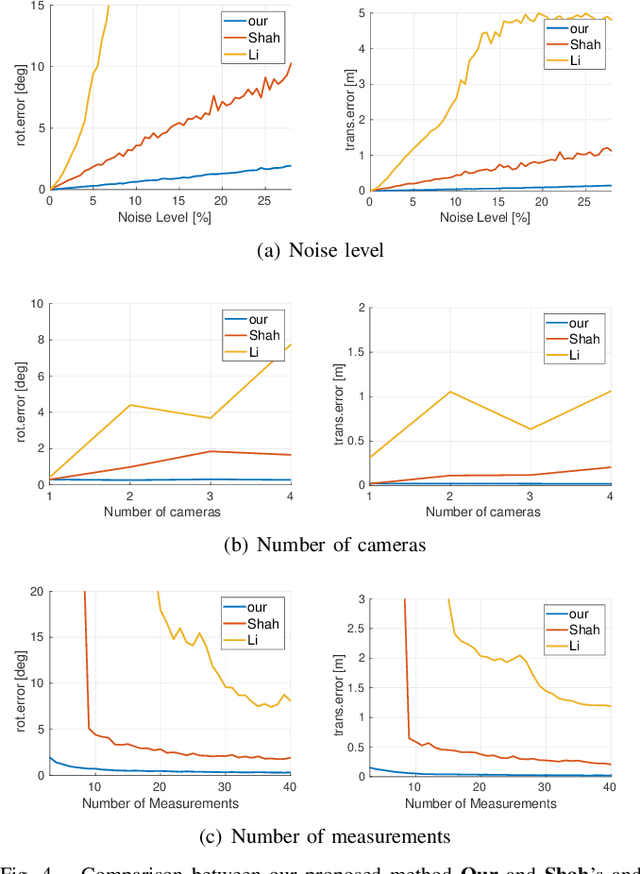
Multi-perspective cameras are quickly gaining importance in many applications such as smart vehicles and virtual or augmented reality. However, a large system size or absence of overlap in neighbouring fields-of-view often complicate their calibration. We present a novel solution which relies on the availability of an external motion capture system. Our core contribution consists of an extension to the hand-eye calibration problem which jointly solves multi-eye-to-base problems in closed form. We furthermore demonstrate its equivalence to the multi-eye-in-hand problem. The practical validity of our approach is supported by our experiments, indicating that the method is highly efficient and accurate, and outperforms existing closed-form alternatives.
Distributed Random Reshuffling over Networks
Jan 09, 2022
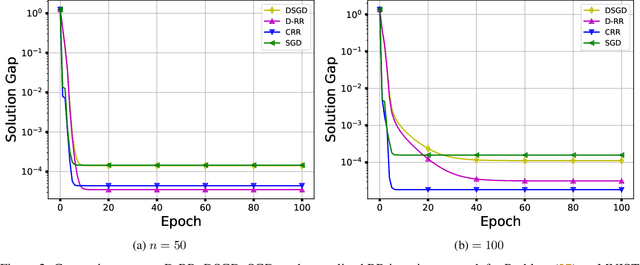
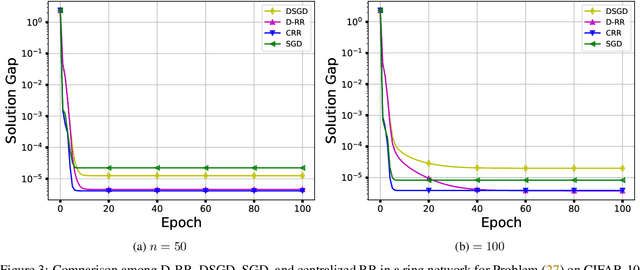
In this paper, we consider the distributed optimization problem where $n$ agents, each possessing a local cost function, collaboratively minimize the average of the local cost functions over a connected network. To solve the problem, we propose a distributed random reshuffling (D-RR) algorithm that combines the classical distributed gradient descent (DGD) method and Random Reshuffling (RR). We show that D-RR inherits the superiority of RR for both smooth strongly convex and smooth nonconvex objective functions. In particular, for smooth strongly convex objective functions, D-RR achieves $\mathcal{O}(1/T^2)$ rate of convergence (here, $T$ counts the total number of iterations) in terms of the squared distance between the iterate and the unique minimizer. When the objective function is assumed to be smooth nonconvex and has Lipschitz continuous component functions, we show that D-RR drives the squared norm of gradient to $0$ at a rate of $\mathcal{O}(1/T^{2/3})$. These convergence results match those of centralized RR (up to constant factors).
Fast Projection onto the Capped Simplex with Applications to Sparse Regression in Bioinformatics
Oct 26, 2021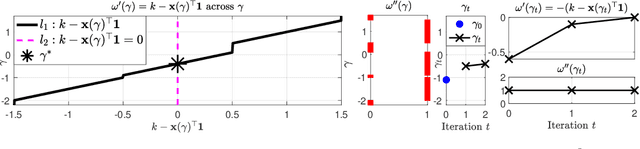
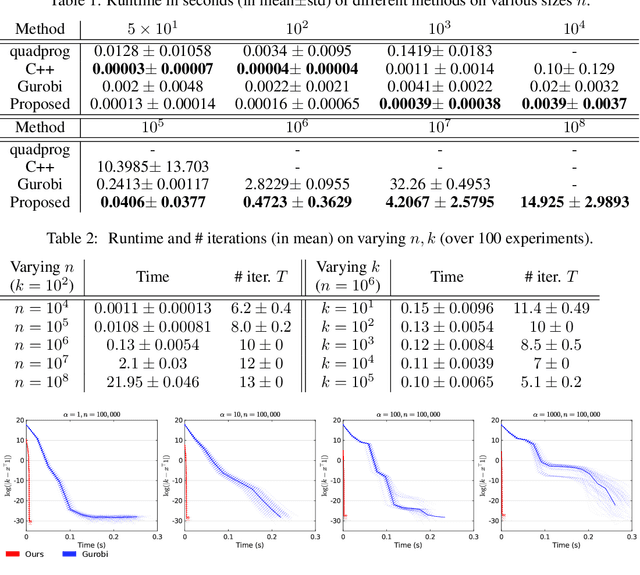
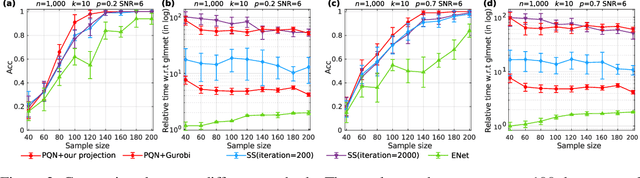
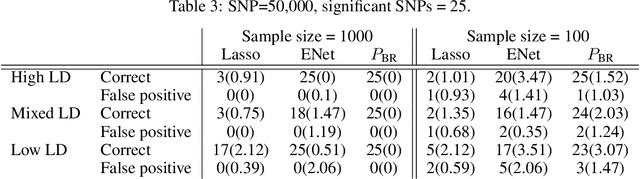
We consider the problem of projecting a vector onto the so-called k-capped simplex, which is a hyper-cube cut by a hyperplane. For an n-dimensional input vector with bounded elements, we found that a simple algorithm based on Newton's method is able to solve the projection problem to high precision with a complexity roughly about O(n), which has a much lower computational cost compared with the existing sorting-based methods proposed in the literature. We provide a theory for partial explanation and justification of the method. We demonstrate that the proposed algorithm can produce a solution of the projection problem with high precision on large scale datasets, and the algorithm is able to significantly outperform the state-of-the-art methods in terms of runtime (about 6-8 times faster than a commercial software with respect to CPU time for input vector with 1 million variables or more). We further illustrate the effectiveness of the proposed algorithm on solving sparse regression in a bioinformatics problem. Empirical results on the GWAS dataset (with 1,500,000 single-nucleotide polymorphisms) show that, when using the proposed method to accelerate the Projected Quasi-Newton (PQN) method, the accelerated PQN algorithm is able to handle huge-scale regression problem and it is more efficient (about 3-6 times faster) than the current state-of-the-art methods.