 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Helpfulness-Harmlessness Alignment with Preference Vectors
Apr 27, 2025



Ensuring that large language models (LLMs) are both helpful and harmless is a critical challenge, as overly strict constraints can lead to excessive refusals, while permissive models risk generating harmful content. Existing approaches, such as reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO), attempt to balance these trade-offs but suffer from performance conflicts, limited controllability, and poor extendability. To address these issues, we propose Preference Vector, a novel framework inspired by task arithmetic. Instead of optimizing multiple preferences within a single objective, we train separate models on individual preferences, extract behavior shifts as preference vectors, and dynamically merge them at test time. This modular approach enables fine-grained, user-controllable preference adjustments and facilitates seamless integration of new preferences without retraining. Experiments show that our proposed Preference Vector framework improves helpfulness without excessive conservatism, allows smooth control over preference trade-offs, and supports scalable multi-preference alignment.
SHA256 at SemEval-2025 Task 4: Selective Amnesia -- Constrained Unlearning for Large Language Models via Knowledge Isolation
Apr 17, 2025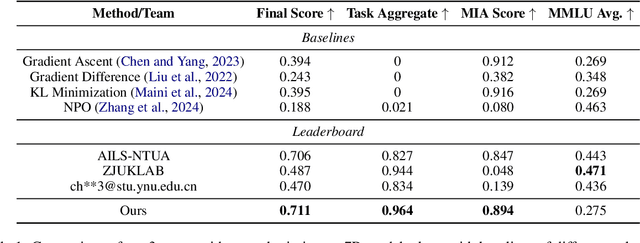
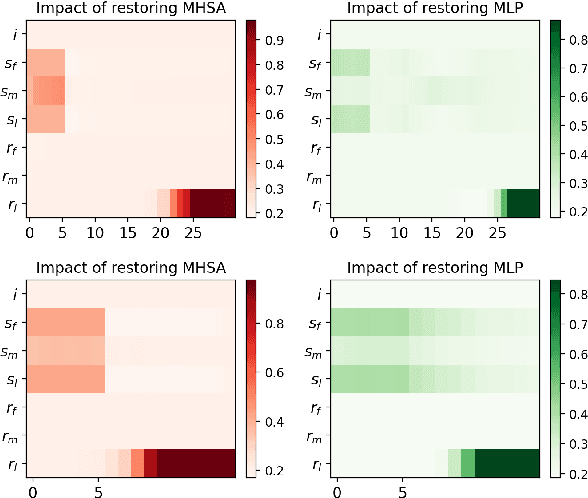
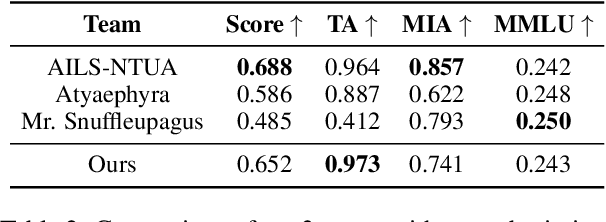
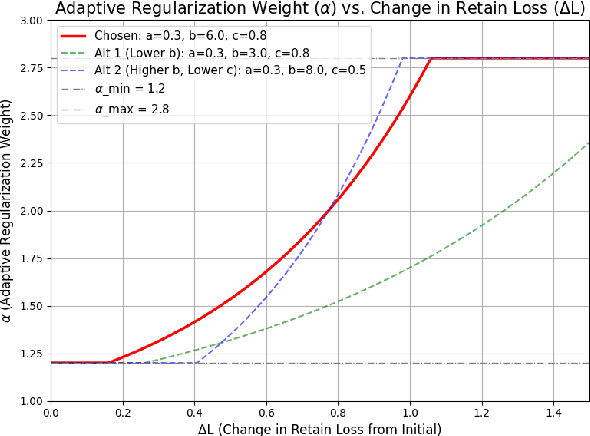
Large language models (LLMs) frequently memorize sensitive information during training, posing risks when deploying publicly accessible models. Current machine unlearning methods struggle to selectively remove specific data associations without degrading overall model capabilities. This paper presents our solution to SemEval-2025 Task 4 on targeted unlearning, which introduces a two-stage methodology that combines causal mediation analysis with layer-specific optimization. Through systematic causal tracing experiments on OLMo architectures (1B and 7B parameters), we identify the critical role of the first few transformer layers (layers 0-5) in storing subject-attribute associations within MLP modules. Building on this insight, we develop a constrained optimization approach that freezes upper layers while applying a novel joint loss function to lower layers-simultaneously maximizing forget set loss via output token cross-entropy penalties and minimizing retain set deviation through adaptive regularization. Our method achieves 2nd place in the 1B model track, demonstrating strong task performance while maintaining 88% of baseline MMLU accuracy. These results establish causal-informed layer optimization as a promising paradigm for efficient, precise unlearning in LLMs, offering a significant step forward in addressing data privacy concerns in AI systems.