 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Training Large Language Models for Long-Horizon Tasks: An Empirical Study of Horizon Length
May 04, 2026Large language models (LLMs) have shown promise as interactive agents that solve tasks through extended sequences of environment interactions. While prior work has primarily focused on system-level optimizations or algorithmic improvements, the role of task horizon length in shaping training dynamics remains poorly understood. In this work, we present a systematic empirical study that examines horizon length through controlled task constructions. Specifically, we construct controlled tasks in which agents face identical decision rules and reasoning structures, but differ only in the length of action sequences required for successful completion. Our results reveal that increasing horizon length alone constitutes a training bottleneck, inducing severe training instability driven by exploration difficulties and credit assignment challenges. We demonstrate that horizon reduction is a key principle to address this limitation, stabilizing training and achieving better performance in long-horizon tasks. Moreover, we find that horizon reduction is related to stronger generalization across horizon lengths: models trained under reduced horizons generalize more effectively to longer-horizon variants at inference time, a phenomenon we refer to as horizon generalization.
ToolHaystack: Stress-Testing Tool-Augmented Language Models in Realistic Long-Term Interactions
May 29, 2025Large language models (LLMs) have demonstrated strong capabilities in using external tools to address user inquiries. However, most existing evaluations assume tool use in short contexts, offering limited insight into model behavior during realistic long-term interactions. To fill this gap, we introduce ToolHaystack, a benchmark for testing the tool use capabilities in long-term interactions. Each test instance in ToolHaystack includes multiple tasks execution contexts and realistic noise within a continuous conversation, enabling assessment of how well models maintain context and handle various disruptions. By applying this benchmark to 14 state-of-the-art LLMs, we find that while current models perform well in standard multi-turn settings, they often significantly struggle in ToolHaystack, highlighting critical gaps in their long-term robustness not revealed by previous tool benchmarks.
LLM Meets Scene Graph: Can Large Language Models Understand and Generate Scene Graphs? A Benchmark and Empirical Study
May 26, 2025



The remarkable reasoning and generalization capabilities of Large Language Models (LLMs) have paved the way for their expanding applications in embodied AI, robotics, and other real-world tasks. To effectively support these applications, grounding in spatial and temporal understanding in multimodal environments is essential. To this end, recent works have leveraged scene graphs, a structured representation that encodes entities, attributes, and their relationships in a scene. However, a comprehensive evaluation of LLMs' ability to utilize scene graphs remains limited. In this work, we introduce Text-Scene Graph (TSG) Bench, a benchmark designed to systematically assess LLMs' ability to (1) understand scene graphs and (2) generate them from textual narratives. With TSG Bench we evaluate 11 LLMs and reveal that, while models perform well on scene graph understanding, they struggle with scene graph generation, particularly for complex narratives. Our analysis indicates that these models fail to effectively decompose discrete scenes from a complex narrative, leading to a bottleneck when generating scene graphs. These findings underscore the need for improved methodologies in scene graph generation and provide valuable insights for future research. The demonstration of our benchmark is available at https://tsg-bench.netlify.app. Additionally, our code and evaluation data are publicly available at https://anonymous.4open.science/r/TSG-Bench.
Embodied Agents Meet Personalization: Exploring Memory Utilization for Personalized Assistance
May 22, 2025Embodied agents empowered by large language models (LLMs) have shown strong performance in household object rearrangement tasks. However, these tasks primarily focus on single-turn interactions with simplified instructions, which do not truly reflect the challenges of providing meaningful assistance to users. To provide personalized assistance, embodied agents must understand the unique semantics that users assign to the physical world (e.g., favorite cup, breakfast routine) by leveraging prior interaction history to interpret dynamic, real-world instructions. Yet, the effectiveness of embodied agents in utilizing memory for personalized assistance remains largely underexplored. To address this gap, we present MEMENTO, a personalized embodied agent evaluation framework designed to comprehensively assess memory utilization capabilities to provide personalized assistance. Our framework consists of a two-stage memory evaluation process design that enables quantifying the impact of memory utilization on task performance. This process enables the evaluation of agents' understanding of personalized knowledge in object rearrangement tasks by focusing on its role in goal interpretation: (1) the ability to identify target objects based on personal meaning (object semantics), and (2) the ability to infer object-location configurations from consistent user patterns, such as routines (user patterns). Our experiments across various LLMs reveal significant limitations in memory utilization, with even frontier models like GPT-4o experiencing a 30.5% performance drop when required to reference multiple memories, particularly in tasks involving user patterns. These findings, along with our detailed analyses and case studies, provide valuable insights for future research in developing more effective personalized embodied agents. Project website: https://connoriginal.github.io/MEMENTO
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025



Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.
Coffee-Gym: An Environment for Evaluating and Improving Natural Language Feedback on Erroneous Code
Sep 29, 2024



This paper presents Coffee-Gym, a comprehensive RL environment for training models that provide feedback on code editing. Coffee-Gym includes two major components: (1) Coffee, a dataset containing humans' code edit traces for coding questions and machine-written feedback for editing erroneous code; (2) CoffeeEval, a reward function that faithfully reflects the helpfulness of feedback by assessing the performance of the revised code in unit tests. With them, Coffee-Gym addresses the unavailability of high-quality datasets for training feedback models with RL, and provides more accurate rewards than the SOTA reward model (i.e., GPT-4). By applying Coffee-Gym, we elicit feedback models that outperform baselines in enhancing open-source code LLMs' code editing, making them comparable with closed-source LLMs. We make the dataset and the model checkpoint publicly available.
Do LLMs Have Distinct and Consistent Personality? TRAIT: Personality Testset designed for LLMs with Psychometrics
Jun 20, 2024



The idea of personality in descriptive psychology, traditionally defined through observable behavior, has now been extended to Large Language Models (LLMs) to better understand their behavior. This raises a question: do LLMs exhibit distinct and consistent personality traits, similar to humans? Existing self-assessment personality tests, while applicable, lack the necessary validity and reliability for precise personality measurements. To address this, we introduce TRAIT, a new tool consisting of 8K multi-choice questions designed to assess the personality of LLMs with validity and reliability. TRAIT is built on the psychometrically validated human questionnaire, Big Five Inventory (BFI) and Short Dark Triad (SD-3), enhanced with the ATOMIC10X knowledge graph for testing personality in a variety of real scenarios. TRAIT overcomes the reliability and validity issues when measuring personality of LLM with self-assessment, showing the highest scores across three metrics: refusal rate, prompt sensitivity, and option order sensitivity. It reveals notable insights into personality of LLM: 1) LLMs exhibit distinct and consistent personality, which is highly influenced by their training data (i.e., data used for alignment tuning), and 2) current prompting techniques have limited effectiveness in eliciting certain traits, such as high psychopathy or low conscientiousness, suggesting the need for further research in this direction.
Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models
Apr 03, 2024



Algorithmic reasoning refers to the ability to understand the complex patterns behind the problem and decompose them into a sequence of reasoning steps towards the solution. Such nature of algorithmic reasoning makes it a challenge for large language models (LLMs), even though they have demonstrated promising performance in other reasoning tasks. Within this context, some recent studies use programming languages (e.g., Python) to express the necessary logic for solving a given instance/question (e.g., Program-of-Thought) as inspired by their strict and precise syntaxes. However, it is non-trivial to write an executable code that expresses the correct logic on the fly within a single inference call. Also, the code generated specifically for an instance cannot be reused for others, even if they are from the same task and might require identical logic to solve. This paper presents Think-and-Execute, a novel framework that decomposes the reasoning process of language models into two steps. (1) In Think, we discover a task-level logic that is shared across all instances for solving a given task and then express the logic with pseudocode; (2) In Execute, we further tailor the generated pseudocode to each instance and simulate the execution of the code. With extensive experiments on seven algorithmic reasoning tasks, we demonstrate the effectiveness of Think-and-Execute. Our approach better improves LMs' reasoning compared to several strong baselines performing instance-specific reasoning (e.g., CoT and PoT), suggesting the helpfulness of discovering task-level logic. Also, we show that compared to natural language, pseudocode can better guide the reasoning of LMs, even though they are trained to follow natural language instructions.
Pearl: A Review-driven Persona-Knowledge Grounded Conversational Recommendation Dataset
Mar 08, 2024



Conversational recommender system is an emerging area that has garnered an increasing interest in the community, especially with the advancements in large language models (LLMs) that enable diverse reasoning over conversational input. Despite the progress, the field has many aspects left to explore. The currently available public datasets for conversational recommendation lack specific user preferences and explanations for recommendations, hindering high-quality recommendations. To address such challenges, we present a novel conversational recommendation dataset named PEARL, synthesized with persona- and knowledge-augmented LLM simulators. We obtain detailed persona and knowledge from real-world reviews and construct a large-scale dataset with over 57k dialogues. Our experimental results demonstrate that utterances in PEARL include more specific user preferences, show expertise in the target domain, and provide recommendations more relevant to the dialogue context than those in prior datasets.
Modularized Transfer Learning with Multiple Knowledge Graphs for Zero-shot Commonsense Reasoning
Jun 22, 2022
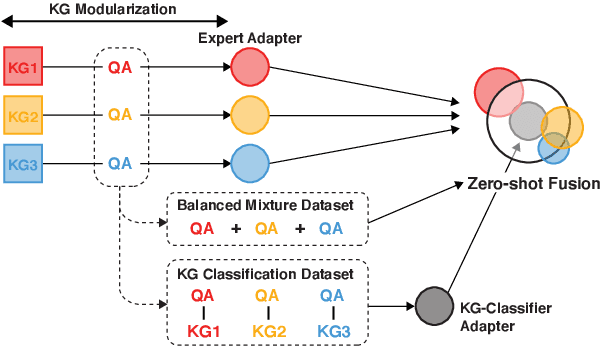
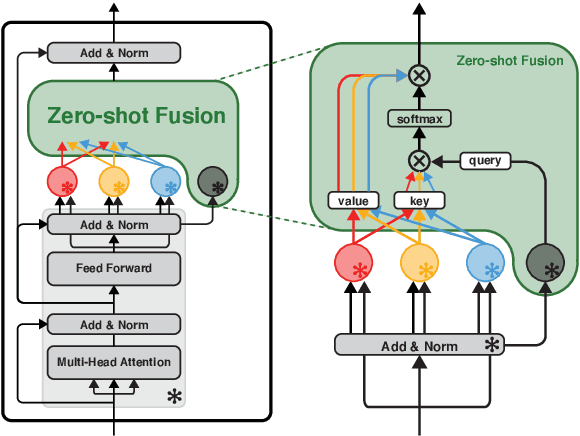
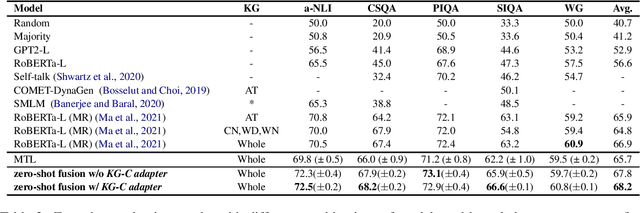
Commonsense reasoning systems should be able to generalize to diverse reasoning cases. However, most state-of-the-art approaches depend on expensive data annotations and overfit to a specific benchmark without learning how to perform general semantic reasoning. To overcome these drawbacks, zero-shot QA systems have shown promise as a robust learning scheme by transforming a commonsense knowledge graph (KG) into synthetic QA-form samples for model training. Considering the increasing type of different commonsense KGs, this paper aims to extend the zero-shot transfer learning scenario into multiple-source settings, where different KGs can be utilized synergetically. Towards this goal, we propose to mitigate the loss of knowledge from the interference among the different knowledge sources, by developing a modular variant of the knowledge aggregation as a new zero-shot commonsense reasoning framework. Results on five commonsense reasoning benchmarks demonstrate the efficacy of our framework, improving the performance with multiple KGs.