 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Two Heads the Same as One? Identifying Disparate Treatment in Fair Neural Networks
Apr 09, 2022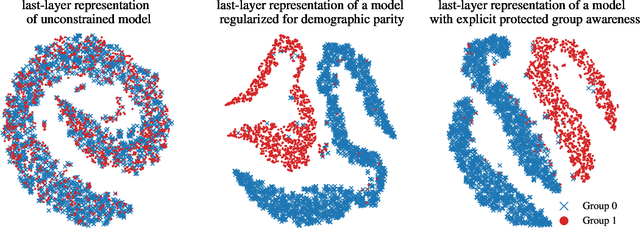
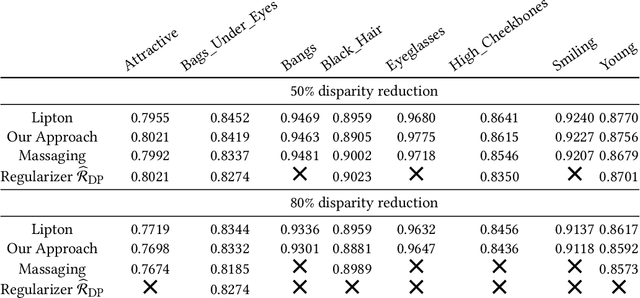
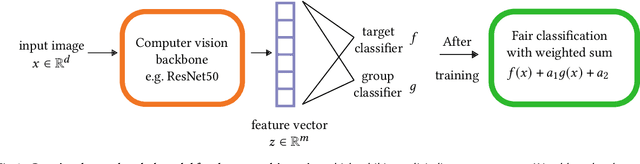
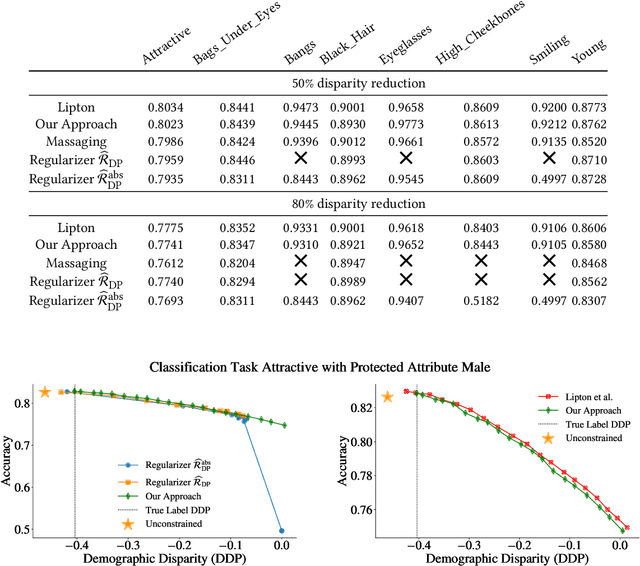
We show that deep neural networks that satisfy demographic parity do so through a form of race or gender awareness, and that the more we force a network to be fair, the more accurately we can recover race or gender from the internal state of the network. Based on this observation, we propose a simple two-stage solution for enforcing fairness. First, we train a two-headed network to predict the protected attribute (such as race or gender) alongside the original task, and second, we enforce demographic parity by taking a weighted sum of the heads. In the end, this approach creates a single-headed network with the same backbone architecture as the original network. Our approach has near identical performance compared to existing regularization-based or preprocessing methods, but has greater stability and higher accuracy where near exact demographic parity is required. To cement the relationship between these two approaches, we show that an unfair and optimally accurate classifier can be recovered by taking a weighted sum of a fair classifier and a classifier predicting the protected attribute. We use this to argue that both the fairness approaches and our explicit formulation demonstrate disparate treatment and that, consequentially, they are likely to be unlawful in a wide range of scenarios under the US law.
Diverse Counterfactual Explanations for Anomaly Detection in Time Series
Mar 21, 2022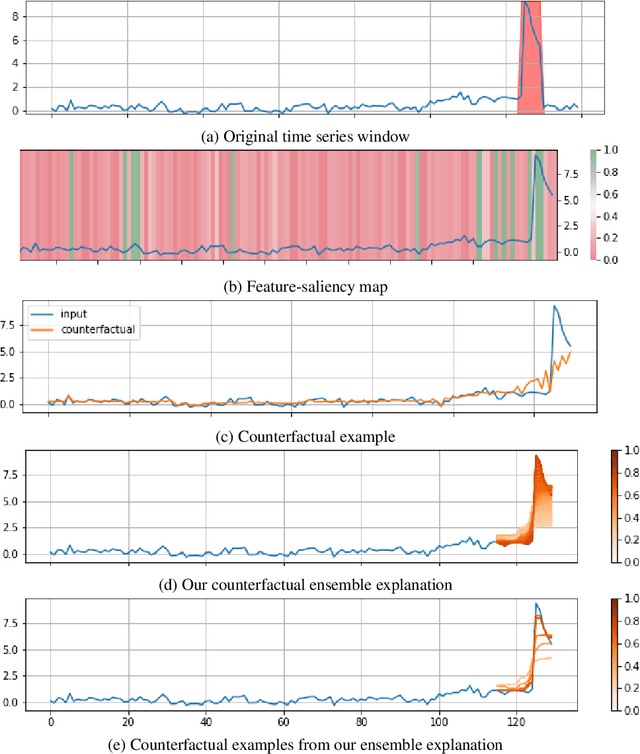
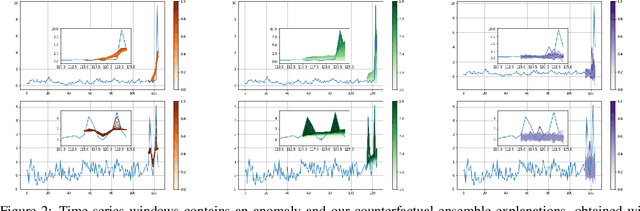
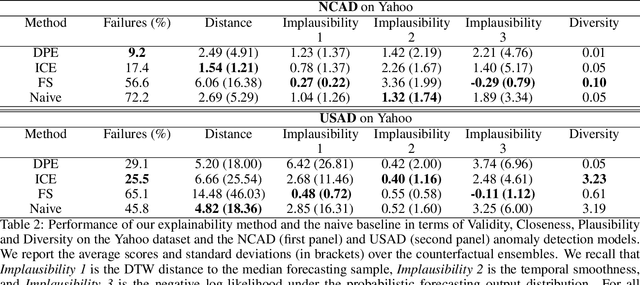
Data-driven methods that detect anomalies in times series data are ubiquitous in practice, but they are in general unable to provide helpful explanations for the predictions they make. In this work we propose a model-agnostic algorithm that generates counterfactual ensemble explanations for time series anomaly detection models. Our method generates a set of diverse counterfactual examples, i.e, multiple perturbed versions of the original time series that are not considered anomalous by the detection model. Since the magnitude of the perturbations is limited, these counterfactuals represent an ensemble of inputs similar to the original time series that the model would deem normal. Our algorithm is applicable to any differentiable anomaly detection model. We investigate the value of our method on univariate and multivariate real-world datasets and two deep-learning-based anomaly detection models, under several explainability criteria previously proposed in other data domains such as Validity, Plausibility, Closeness and Diversity. We show that our algorithm can produce ensembles of counterfactual examples that satisfy these criteria and thanks to a novel type of visualisation, can convey a richer interpretation of a model's internal mechanism than existing methods. Moreover, we design a sparse variant of our method to improve the interpretability of counterfactual explanations for high-dimensional time series anomalies. In this setting, our explanation is localised on only a few dimensions and can therefore be communicated more efficiently to the model's user.
COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks
Mar 16, 2022
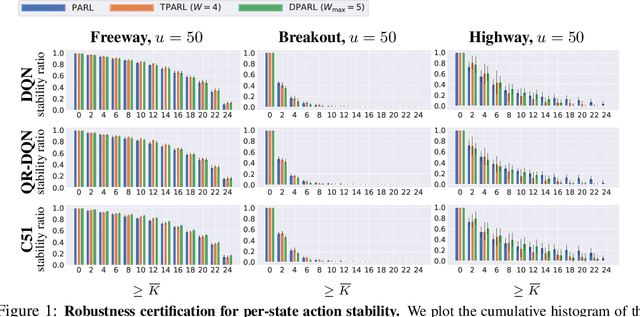
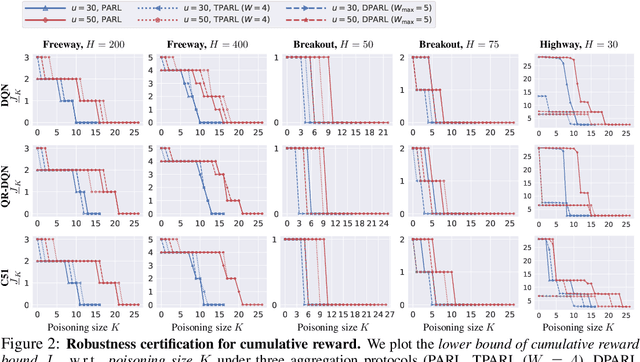
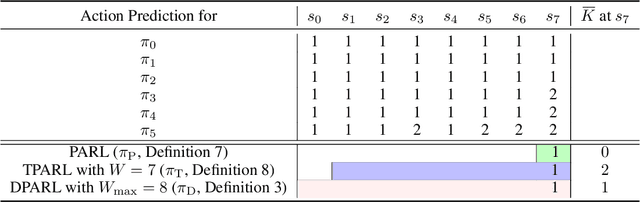
As reinforcement learning (RL) has achieved near human-level performance in a variety of tasks, its robustness has raised great attention. While a vast body of research has explored test-time (evasion) attacks in RL and corresponding defenses, its robustness against training-time (poisoning) attacks remains largely unanswered. In this work, we focus on certifying the robustness of offline RL in the presence of poisoning attacks, where a subset of training trajectories could be arbitrarily manipulated. We propose the first certification framework, COPA, to certify the number of poisoning trajectories that can be tolerated regarding different certification criteria. Given the complex structure of RL, we propose two certification criteria: per-state action stability and cumulative reward bound. To further improve the certification, we propose new partition and aggregation protocols to train robust policies. We further prove that some of the proposed certification methods are theoretically tight and some are NP-Complete problems. We leverage COPA to certify three RL environments trained with different algorithms and conclude: (1) The proposed robust aggregation protocols such as temporal aggregation can significantly improve the certifications; (2) Our certification for both per-state action stability and cumulative reward bound are efficient and tight; (3) The certification for different training algorithms and environments are different, implying their intrinsic robustness properties. All experimental results are available at https://copa-leaderboard.github.io.
Human-Algorithm Collaboration: Achieving Complementarity and Avoiding Unfairness
Feb 17, 2022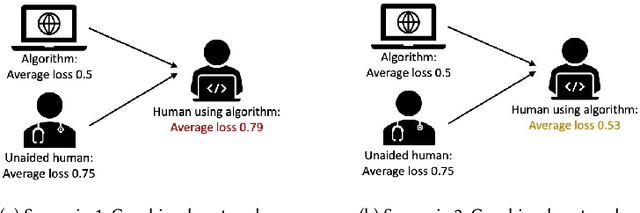
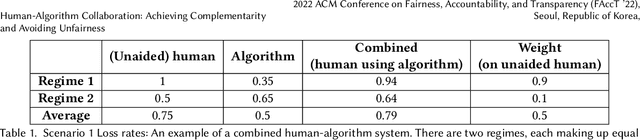

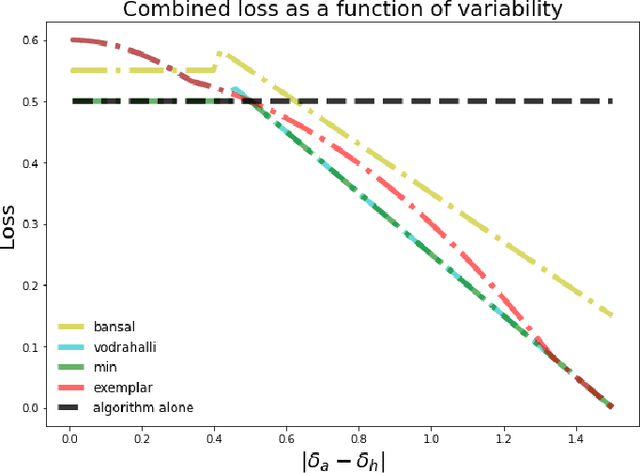
Much of machine learning research focuses on predictive accuracy: given a task, create a machine learning model (or algorithm) that maximizes accuracy. In many settings, however, the final prediction or decision of a system is under the control of a human, who uses an algorithm's output along with their own personal expertise in order to produce a combined prediction. One ultimate goal of such collaborative systems is "complementarity": that is, to produce lower loss (equivalently, greater payoff or utility) than either the human or algorithm alone. However, experimental results have shown that even in carefully-designed systems, complementary performance can be elusive. Our work provides three key contributions. First, we provide a theoretical framework for modeling simple human-algorithm systems and demonstrate that multiple prior analyses can be expressed within it. Next, we use this model to prove conditions where complementarity is impossible, and give constructive examples of where complementarity is achievable. Finally, we discuss the implications of our findings, especially with respect to the fairness of a classifier. In sum, these results deepen our understanding of key factors influencing the combined performance of human-algorithm systems, giving insight into how algorithmic tools can best be designed for collaborative environments.
Designing Closed Human-in-the-loop Deferral Pipelines
Feb 09, 2022



In hybrid human-machine deferral frameworks, a classifier can defer uncertain cases to human decision-makers (who are often themselves fallible). Prior work on simultaneous training of such classifier and deferral models has typically assumed access to an oracle during training to obtain true class labels for training samples, but in practice there often is no such oracle. In contrast, we consider a "closed" decision-making pipeline in which the same fallible human decision-makers used in deferral also provide training labels. How can imperfect and biased human expert labels be used to train a fair and accurate deferral framework? Our key insight is that by exploiting weak prior information, we can match experts to input examples to ensure fairness and accuracy of the resulting deferral framework, even when imperfect and biased experts are used in place of ground truth labels. The efficacy of our approach is shown both by theoretical analysis and by evaluation on two tasks.
More Than Words: Towards Better Quality Interpretations of Text Classifiers
Dec 23, 2021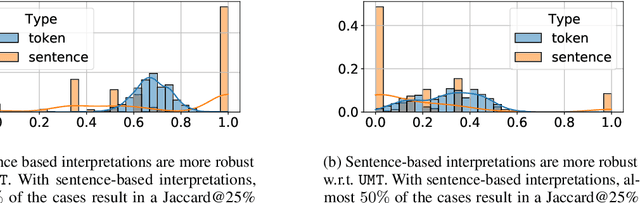



The large size and complex decision mechanisms of state-of-the-art text classifiers make it difficult for humans to understand their predictions, leading to a potential lack of trust by the users. These issues have led to the adoption of methods like SHAP and Integrated Gradients to explain classification decisions by assigning importance scores to input tokens. However, prior work, using different randomization tests, has shown that interpretations generated by these methods may not be robust. For instance, models making the same predictions on the test set may still lead to different feature importance rankings. In order to address the lack of robustness of token-based interpretability, we explore explanations at higher semantic levels like sentences. We use computational metrics and human subject studies to compare the quality of sentence-based interpretations against token-based ones. Our experiments show that higher-level feature attributions offer several advantages: 1) they are more robust as measured by the randomization tests, 2) they lead to lower variability when using approximation-based methods like SHAP, and 3) they are more intelligible to humans in situations where the linguistic coherence resides at a higher granularity level. Based on these findings, we show that token-based interpretability, while being a convenient first choice given the input interfaces of the ML models, is not the most effective one in all situations.
Amazon SageMaker Model Monitor: A System for Real-Time Insights into Deployed Machine Learning Models
Dec 13, 2021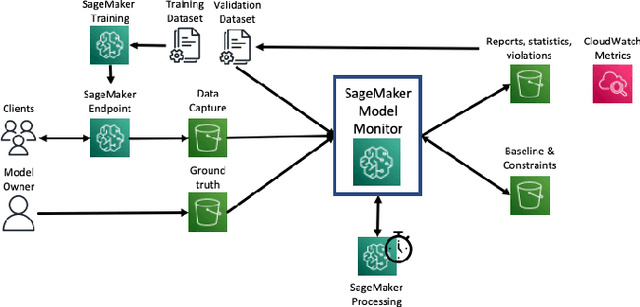
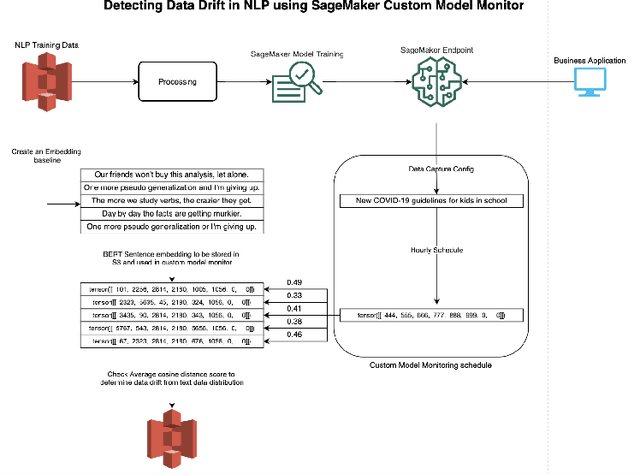
With the increasing adoption of machine learning (ML) models and systems in high-stakes settings across different industries, guaranteeing a model's performance after deployment has become crucial. Monitoring models in production is a critical aspect of ensuring their continued performance and reliability. We present Amazon SageMaker Model Monitor, a fully managed service that continuously monitors the quality of machine learning models hosted on Amazon SageMaker. Our system automatically detects data, concept, bias, and feature attribution drift in models in real-time and provides alerts so that model owners can take corrective actions and thereby maintain high quality models. We describe the key requirements obtained from customers, system design and architecture, and methodology for detecting different types of drift. Further, we provide quantitative evaluations followed by use cases, insights, and lessons learned from more than 1.5 years of production deployment.
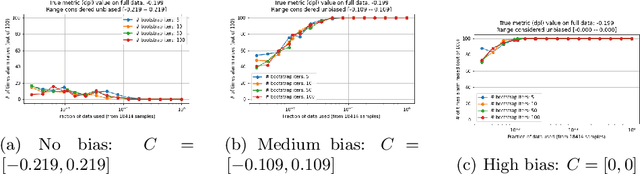
Amazon SageMaker Clarify: Machine Learning Bias Detection and Explainability in the Cloud
Sep 07, 2021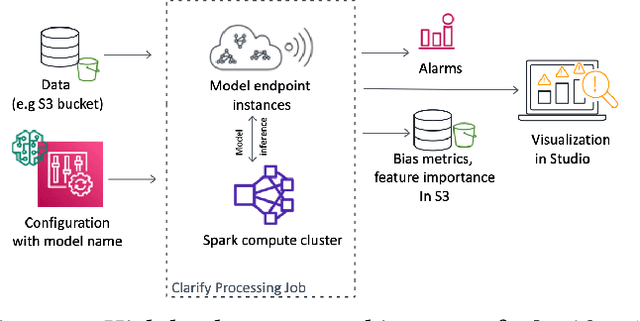
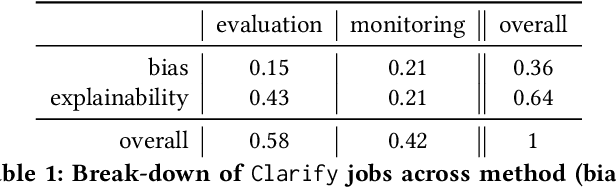
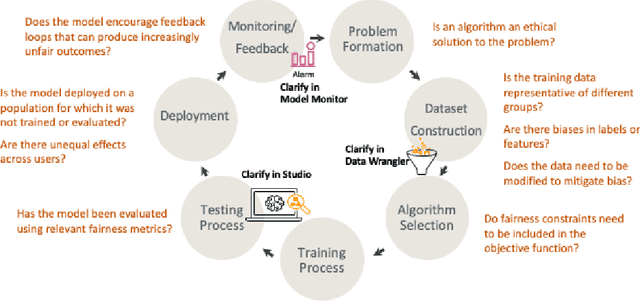
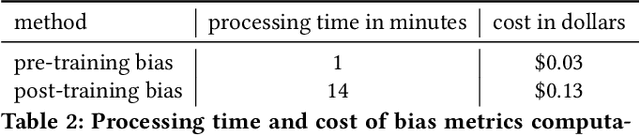
Understanding the predictions made by machine learning (ML) models and their potential biases remains a challenging and labor-intensive task that depends on the application, the dataset, and the specific model. We present Amazon SageMaker Clarify, an explainability feature for Amazon SageMaker that launched in December 2020, providing insights into data and ML models by identifying biases and explaining predictions. It is deeply integrated into Amazon SageMaker, a fully managed service that enables data scientists and developers to build, train, and deploy ML models at any scale. Clarify supports bias detection and feature importance computation across the ML lifecycle, during data preparation, model evaluation, and post-deployment monitoring. We outline the desiderata derived from customer input, the modular architecture, and the methodology for bias and explanation computations. Further, we describe the technical challenges encountered and the tradeoffs we had to make. For illustration, we discuss two customer use cases. We present our deployment results including qualitative customer feedback and a quantitative evaluation. Finally, we summarize lessons learned, and discuss best practices for the successful adoption of fairness and explanation tools in practice.
Multiaccurate Proxies for Downstream Fairness
Jul 09, 2021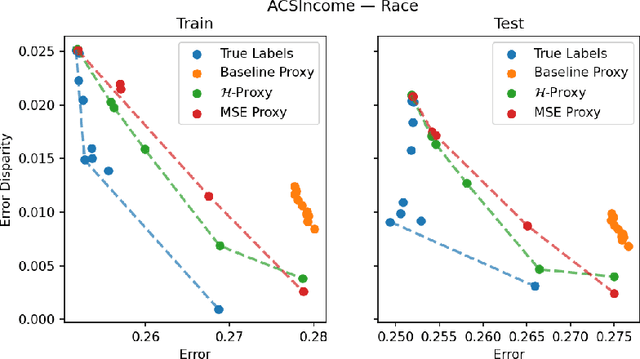
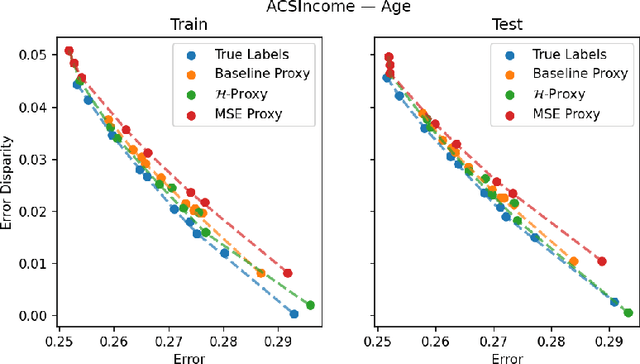
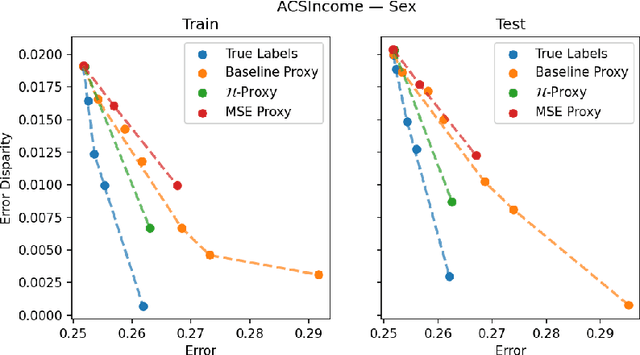
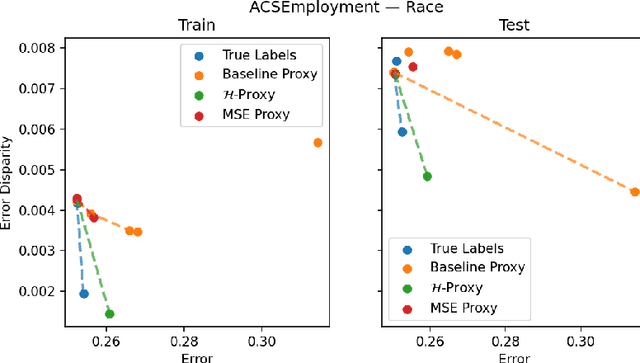
We study the problem of training a model that must obey demographic fairness conditions when the sensitive features are not available at training time -- in other words, how can we train a model to be fair by race when we don't have data about race? We adopt a fairness pipeline perspective, in which an "upstream" learner that does have access to the sensitive features will learn a proxy model for these features from the other attributes. The goal of the proxy is to allow a general "downstream" learner -- with minimal assumptions on their prediction task -- to be able to use the proxy to train a model that is fair with respect to the true sensitive features. We show that obeying multiaccuracy constraints with respect to the downstream model class suffices for this purpose, and provide sample- and oracle efficient-algorithms and generalization bounds for learning such proxies. In general, multiaccuracy can be much easier to satisfy than classification accuracy, and can be satisfied even when the sensitive features are hard to predict.
On the Lack of Robust Interpretability of Neural Text Classifiers
Jun 08, 2021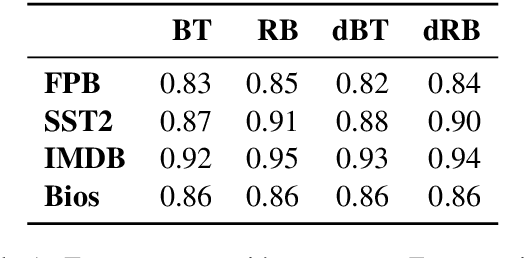
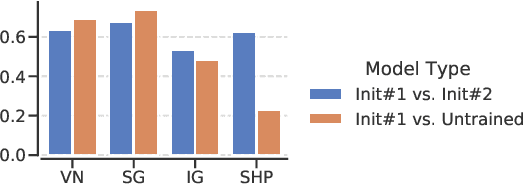

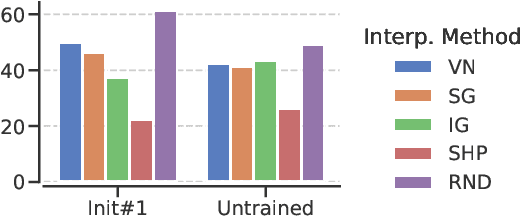
With the ever-increasing complexity of neural language models, practitioners have turned to methods for understanding the predictions of these models. One of the most well-adopted approaches for model interpretability is feature-based interpretability, i.e., ranking the features in terms of their impact on model predictions. Several prior studies have focused on assessing the fidelity of feature-based interpretability methods, i.e., measuring the impact of dropping the top-ranked features on the model output. However, relatively little work has been conducted on quantifying the robustness of interpretations. In this work, we assess the robustness of interpretations of neural text classifiers, specifically, those based on pretrained Transformer encoders, using two randomization tests. The first compares the interpretations of two models that are identical except for their initializations. The second measures whether the interpretations differ between a model with trained parameters and a model with random parameters. Both tests show surprising deviations from expected behavior, raising questions about the extent of insights that practitioners may draw from interpretations.