 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Yield Curve Forecasting using Machine Learning and Econometrics: A Comparative Analysis
May 11, 2026While machine learning has revolutionized many fields such as natural language processing (NLP) and computer vision, its impact on time-series forecasting is still widely disputed, especially in the finance domain. This paper compares forecasting performance on U.S. Treasury yield curve data across econometrics/time-series analysis, classical machine learning, and deep learning methods, using daily data over 47 years. The Treasury yield curve is important because it is widely used by every participant in the bond markets, which are larger than equity markets. We examine a variety of methods that have not been tested on yield curve forecasting, especially deep learning algorithms. The algorithms include the Autoregressive Integrated Moving Average (ARIMA) model and its extensions, naive benchmarks, ensemble methods, Recurrent Neural Networks (RNNs), and multiple transformers built for forecasting. ARIMA and naive econometric models outperform other models overall, except in one time block. Of the machine learning methods, TimeGPT, LGBM and RNNs perform the best. Furthermore, the paper explores whether stationary or nonstationary data are more appropriate as input to deep learning models.
* 18 pages, 12 figures, comparative study of econometric, machine learning, and deep learning methods for U.S. Treasury yield curve forecasting
PPLqa: An Unsupervised Information-Theoretic Quality Metric for Comparing Generative Large Language Models
Nov 22, 2024We propose PPLqa, an easy to compute, language independent, information-theoretic metric to measure the quality of responses of generative Large Language Models (LLMs) in an unsupervised way, without requiring ground truth annotations or human supervision. The method and metric enables users to rank generative language models for quality of responses, so as to make a selection of the best model for a given task. Our single metric assesses LLMs with an approach that subsumes, but is not explicitly based on, coherence and fluency (quality of writing) and relevance and consistency (appropriateness of response) to the query. PPLqa performs as well as other related metrics, and works better with long-form Q\&A. Thus, PPLqa enables bypassing the lengthy annotation process required for ground truth evaluations, and it also correlates well with human and LLM rankings.
Diverse Counterfactual Explanations for Anomaly Detection in Time Series
Mar 21, 2022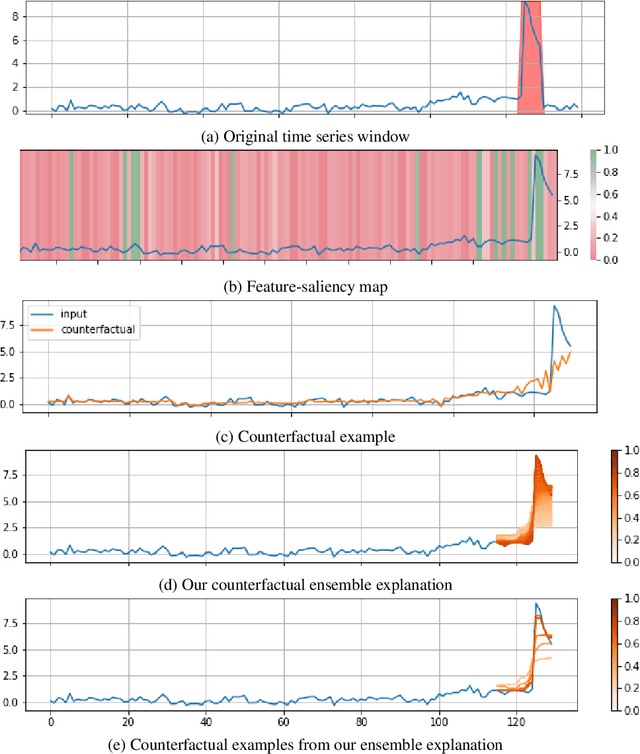
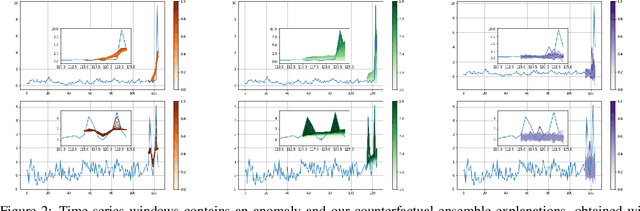
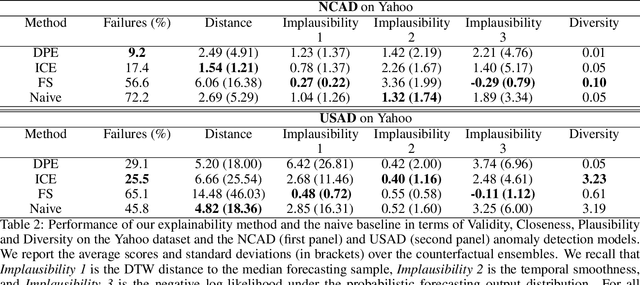
Data-driven methods that detect anomalies in times series data are ubiquitous in practice, but they are in general unable to provide helpful explanations for the predictions they make. In this work we propose a model-agnostic algorithm that generates counterfactual ensemble explanations for time series anomaly detection models. Our method generates a set of diverse counterfactual examples, i.e, multiple perturbed versions of the original time series that are not considered anomalous by the detection model. Since the magnitude of the perturbations is limited, these counterfactuals represent an ensemble of inputs similar to the original time series that the model would deem normal. Our algorithm is applicable to any differentiable anomaly detection model. We investigate the value of our method on univariate and multivariate real-world datasets and two deep-learning-based anomaly detection models, under several explainability criteria previously proposed in other data domains such as Validity, Plausibility, Closeness and Diversity. We show that our algorithm can produce ensembles of counterfactual examples that satisfy these criteria and thanks to a novel type of visualisation, can convey a richer interpretation of a model's internal mechanism than existing methods. Moreover, we design a sparse variant of our method to improve the interpretability of counterfactual explanations for high-dimensional time series anomalies. In this setting, our explanation is localised on only a few dimensions and can therefore be communicated more efficiently to the model's user.
Amazon SageMaker Clarify: Machine Learning Bias Detection and Explainability in the Cloud
Sep 07, 2021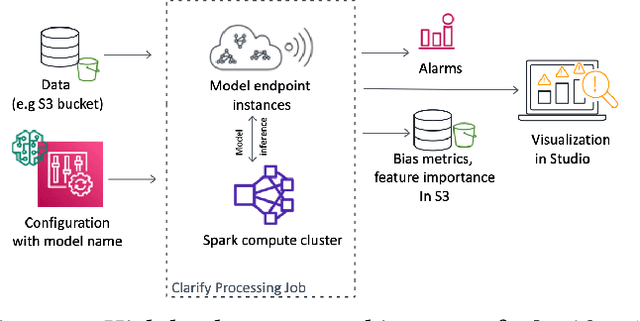
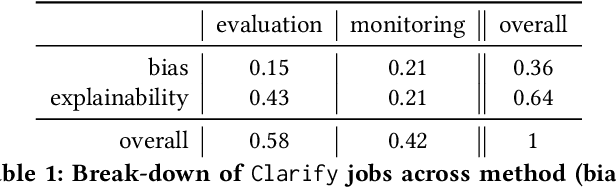
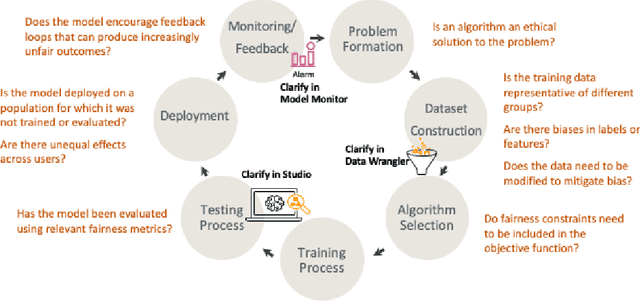
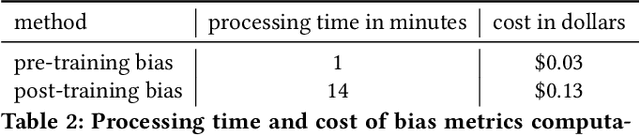
Understanding the predictions made by machine learning (ML) models and their potential biases remains a challenging and labor-intensive task that depends on the application, the dataset, and the specific model. We present Amazon SageMaker Clarify, an explainability feature for Amazon SageMaker that launched in December 2020, providing insights into data and ML models by identifying biases and explaining predictions. It is deeply integrated into Amazon SageMaker, a fully managed service that enables data scientists and developers to build, train, and deploy ML models at any scale. Clarify supports bias detection and feature importance computation across the ML lifecycle, during data preparation, model evaluation, and post-deployment monitoring. We outline the desiderata derived from customer input, the modular architecture, and the methodology for bias and explanation computations. Further, we describe the technical challenges encountered and the tradeoffs we had to make. For illustration, we discuss two customer use cases. We present our deployment results including qualitative customer feedback and a quantitative evaluation. Finally, we summarize lessons learned, and discuss best practices for the successful adoption of fairness and explanation tools in practice.
On the Lack of Robust Interpretability of Neural Text Classifiers
Jun 08, 2021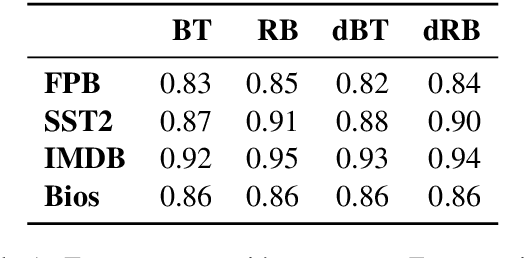
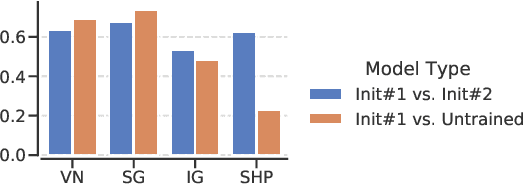

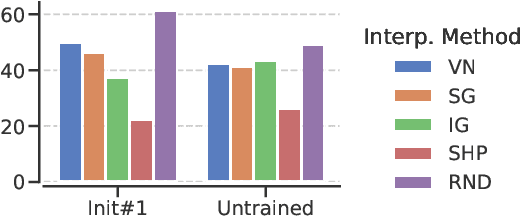
With the ever-increasing complexity of neural language models, practitioners have turned to methods for understanding the predictions of these models. One of the most well-adopted approaches for model interpretability is feature-based interpretability, i.e., ranking the features in terms of their impact on model predictions. Several prior studies have focused on assessing the fidelity of feature-based interpretability methods, i.e., measuring the impact of dropping the top-ranked features on the model output. However, relatively little work has been conducted on quantifying the robustness of interpretations. In this work, we assess the robustness of interpretations of neural text classifiers, specifically, those based on pretrained Transformer encoders, using two randomization tests. The first compares the interpretations of two models that are identical except for their initializations. The second measures whether the interpretations differ between a model with trained parameters and a model with random parameters. Both tests show surprising deviations from expected behavior, raising questions about the extent of insights that practitioners may draw from interpretations.