 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Artificial Intelligence Models for Health Recognition Using Face Photographs (FAHR-Face)
Jun 17, 2025Background: Facial appearance offers a noninvasive window into health. We built FAHR-Face, a foundation model trained on >40 million facial images and fine-tuned it for two distinct tasks: biological age estimation (FAHR-FaceAge) and survival risk prediction (FAHR-FaceSurvival). Methods: FAHR-FaceAge underwent a two-stage, age-balanced fine-tuning on 749,935 public images; FAHR-FaceSurvival was fine-tuned on 34,389 photos of cancer patients. Model robustness (cosmetic surgery, makeup, pose, lighting) and independence (saliency mapping) was tested extensively. Both models were clinically tested in two independent cancer patient datasets with survival analyzed by multivariable Cox models and adjusted for clinical prognostic factors. Findings: For age estimation, FAHR-FaceAge had the lowest mean absolute error of 5.1 years on public datasets, outperforming benchmark models and maintaining accuracy across the full human lifespan. In cancer patients, FAHR-FaceAge outperformed a prior facial age estimation model in survival prognostication. FAHR-FaceSurvival demonstrated robust prediction of mortality, and the highest-risk quartile had more than triple the mortality of the lowest (adjusted hazard ratio 3.22; P<0.001). These findings were validated in the independent cohort and both models showed generalizability across age, sex, race and cancer subgroups. The two algorithms provided distinct, complementary prognostic information; saliency mapping revealed each model relied on distinct facial regions. The combination of FAHR-FaceAge and FAHR-FaceSurvival improved prognostic accuracy. Interpretation: A single foundation model can generate inexpensive, scalable facial biomarkers that capture both biological ageing and disease-related mortality risk. The foundation model enabled effective training using relatively small clinical datasets.
Magnetic resonance delta radiomics to track radiation response in lung tumors receiving stereotactic MRI-guided radiotherapy
Feb 23, 2024



Introduction: Lung cancer is a leading cause of cancer-related mortality, and stereotactic body radiotherapy (SBRT) has become a standard treatment for early-stage lung cancer. However, the heterogeneous response to radiation at the tumor level poses challenges. Currently, standardized dosage regimens lack adaptation based on individual patient or tumor characteristics. Thus, we explore the potential of delta radiomics from on-treatment magnetic resonance (MR) imaging to track radiation dose response, inform personalized radiotherapy dosing, and predict outcomes. Methods: A retrospective study of 47 MR-guided lung SBRT treatments for 39 patients was conducted. Radiomic features were extracted using Pyradiomics, and stability was evaluated temporally and spatially. Delta radiomics were correlated with radiation dose delivery and assessed for associations with tumor control and survival with Cox regressions. Results: Among 107 features, 49 demonstrated temporal stability, and 57 showed spatial stability. Fifteen stable and non-collinear features were analyzed. Median Skewness and surface to volume ratio decreased with radiation dose fraction delivery, while coarseness and 90th percentile values increased. Skewness had the largest relative median absolute changes (22%-45%) per fraction from baseline and was associated with locoregional failure (p=0.012) by analysis of covariance. Skewness, Elongation, and Flatness were significantly associated with local recurrence-free survival, while tumor diameter and volume were not. Conclusions: Our study establishes the feasibility and stability of delta radiomics analysis for MR-guided lung SBRT. Findings suggest that MR delta radiomics can capture short-term radiographic manifestations of intra-tumoral radiation effect.
Amazon SageMaker Clarify: Machine Learning Bias Detection and Explainability in the Cloud
Sep 07, 2021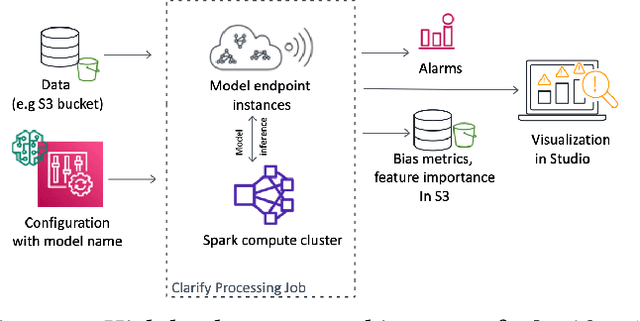
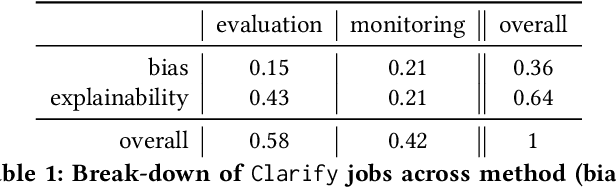
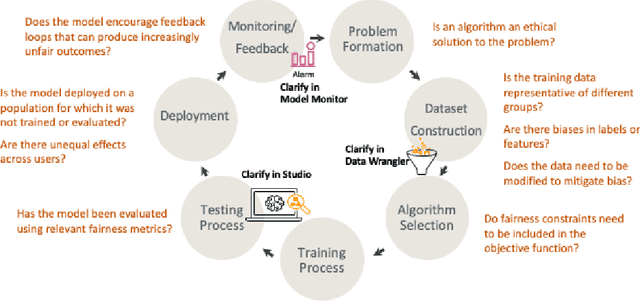
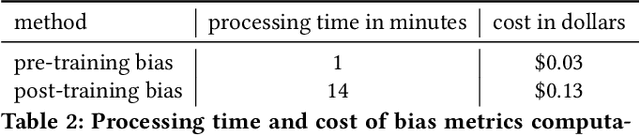
Understanding the predictions made by machine learning (ML) models and their potential biases remains a challenging and labor-intensive task that depends on the application, the dataset, and the specific model. We present Amazon SageMaker Clarify, an explainability feature for Amazon SageMaker that launched in December 2020, providing insights into data and ML models by identifying biases and explaining predictions. It is deeply integrated into Amazon SageMaker, a fully managed service that enables data scientists and developers to build, train, and deploy ML models at any scale. Clarify supports bias detection and feature importance computation across the ML lifecycle, during data preparation, model evaluation, and post-deployment monitoring. We outline the desiderata derived from customer input, the modular architecture, and the methodology for bias and explanation computations. Further, we describe the technical challenges encountered and the tradeoffs we had to make. For illustration, we discuss two customer use cases. We present our deployment results including qualitative customer feedback and a quantitative evaluation. Finally, we summarize lessons learned, and discuss best practices for the successful adoption of fairness and explanation tools in practice.