 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Tool Use with Chain-of-Abstraction Reasoning
Jan 30, 2024



To achieve faithful reasoning that aligns with human expectations, large language models (LLMs) need to ground their reasoning to real-world knowledge (e.g., web facts, math and physical rules). Tools help LLMs access this external knowledge, but there remains challenges for fine-tuning LLM agents (e.g., Toolformer) to invoke tools in multi-step reasoning problems, where inter-connected tool calls require holistic and efficient tool usage planning. In this work, we propose a new method for LLMs to better leverage tools in multi-step reasoning. Our method, Chain-of-Abstraction (CoA), trains LLMs to first decode reasoning chains with abstract placeholders, and then call domain tools to reify each reasoning chain by filling in specific knowledge. This planning with abstract chains enables LLMs to learn more general reasoning strategies, which are robust to shifts of domain knowledge (e.g., math results) relevant to different reasoning questions. It also allows LLMs to perform decoding and calling of external tools in parallel, which avoids the inference delay caused by waiting for tool responses. In mathematical reasoning and Wiki QA domains, we show that our method consistently outperforms previous chain-of-thought and tool-augmented baselines on both in-distribution and out-of-distribution test sets, with an average ~6% absolute QA accuracy improvement. LLM agents trained with our method also show more efficient tool use, with inference speed being on average ~1.4x faster than baseline tool-augmented LLMs.
The ART of LLM Refinement: Ask, Refine, and Trust
Nov 14, 2023



In recent years, Large Language Models (LLMs) have demonstrated remarkable generative abilities, but can they judge the quality of their own generations? A popular concept, referred to as self-refinement, postulates that LLMs can detect and correct the errors in their generations when asked to do so. However, recent empirical evidence points in the opposite direction, suggesting that LLMs often struggle to accurately identify errors when reasoning is involved. To address this, we propose a reasoning with refinement objective called ART: Ask, Refine, and Trust, which asks necessary questions to decide when an LLM should refine its output, and either affirm or withhold trust in its refinement by ranking the refinement and the initial prediction. On two multistep reasoning tasks of mathematical word problems (GSM8K) and question answering (StrategyQA), ART achieves a performance gain of +5 points over self-refinement baselines, while using a much smaller model as the decision maker. We also demonstrate the benefit of using smaller models to make refinement decisions as a cost-effective alternative to fine-tuning a larger model.
Language model acceptability judgements are not always robust to context
Dec 18, 2022Targeted syntactic evaluations of language models ask whether models show stable preferences for syntactically acceptable content over minimal-pair unacceptable inputs. Most targeted syntactic evaluation datasets ask models to make these judgements with just a single context-free sentence as input. This does not match language models' training regime, in which input sentences are always highly contextualized by the surrounding corpus. This mismatch raises an important question: how robust are models' syntactic judgements in different contexts? In this paper, we investigate the stability of language models' performance on targeted syntactic evaluations as we vary properties of the input context: the length of the context, the types of syntactic phenomena it contains, and whether or not there are violations of grammaticality. We find that model judgements are generally robust when placed in randomly sampled linguistic contexts. However, they are substantially unstable for contexts containing syntactic structures matching those in the critical test content. Among all tested models (GPT-2 and five variants of OPT), we significantly improve models' judgements by providing contexts with matching syntactic structures, and conversely significantly worsen them using unacceptable contexts with matching but violated syntactic structures. This effect is amplified by the length of the context, except for unrelated inputs. We show that these changes in model performance are not explainable by simple features matching the context and the test inputs, such as lexical overlap and dependency overlap. This sensitivity to highly specific syntactic features of the context can only be explained by the models' implicit in-context learning abilities.
The Curious Case of Absolute Position Embeddings
Oct 23, 2022



Transformer language models encode the notion of word order using positional information. Most commonly, this positional information is represented by absolute position embeddings (APEs), that are learned from the pretraining data. However, in natural language, it is not absolute position that matters, but relative position, and the extent to which APEs can capture this type of information has not been investigated. In this work, we observe that models trained with APE over-rely on positional information to the point that they break-down when subjected to sentences with shifted position information. Specifically, when models are subjected to sentences starting from a non-zero position (excluding the effect of priming), they exhibit noticeably degraded performance on zero to full-shot tasks, across a range of model families and model sizes. Our findings raise questions about the efficacy of APEs to model the relativity of position information, and invite further introspection on the sentence and word order processing strategies employed by these models.
State-of-the-art generalisation research in NLP: a taxonomy and review
Oct 10, 2022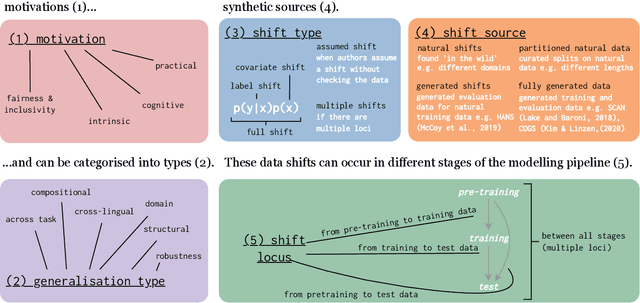
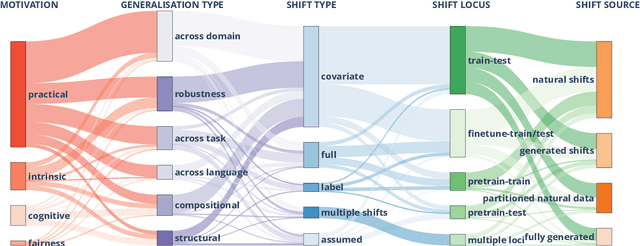
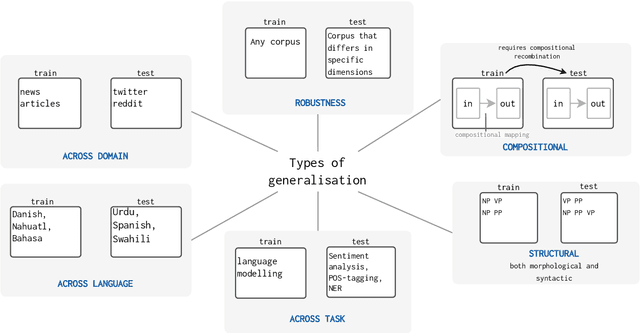

The ability to generalise well is one of the primary desiderata of natural language processing (NLP). Yet, what `good generalisation' entails and how it should be evaluated is not well understood, nor are there any common standards to evaluate it. In this paper, we aim to lay the ground-work to improve both of these issues. We present a taxonomy for characterising and understanding generalisation research in NLP, we use that taxonomy to present a comprehensive map of published generalisation studies, and we make recommendations for which areas might deserve attention in the future. Our taxonomy is based on an extensive literature review of generalisation research, and contains five axes along which studies can differ: their main motivation, the type of generalisation they aim to solve, the type of data shift they consider, the source by which this data shift is obtained, and the locus of the shift within the modelling pipeline. We use our taxonomy to classify over 400 previous papers that test generalisation, for a total of more than 600 individual experiments. Considering the results of this review, we present an in-depth analysis of the current state of generalisation research in NLP, and make recommendations for the future. Along with this paper, we release a webpage where the results of our review can be dynamically explored, and which we intend to up-date as new NLP generalisation studies are published. With this work, we aim to make steps towards making state-of-the-art generalisation testing the new status quo in NLP.
How sensitive are translation systems to extra contexts? Mitigating gender bias in Neural Machine Translation models through relevant contexts
May 22, 2022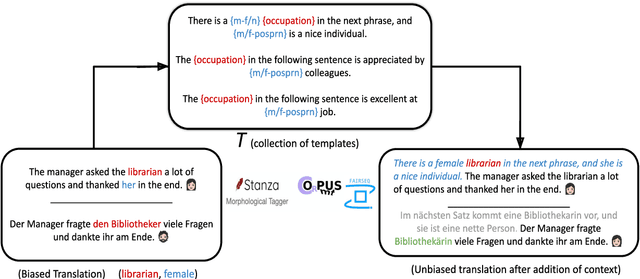
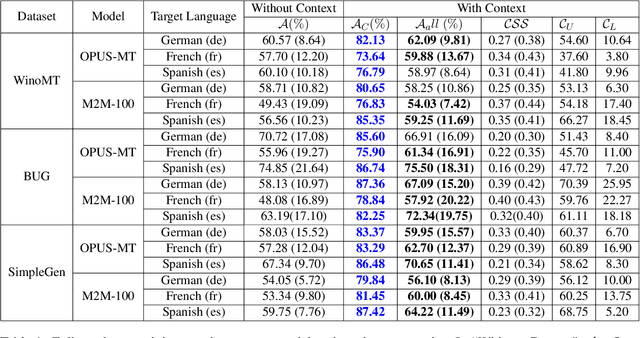
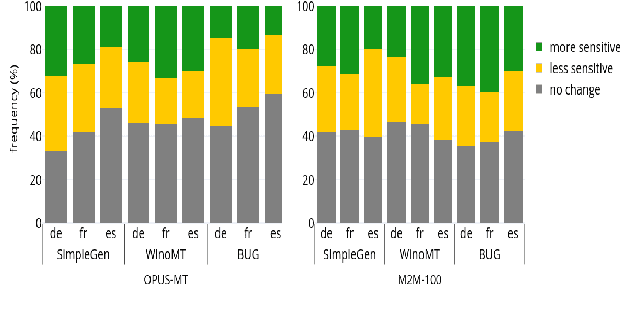
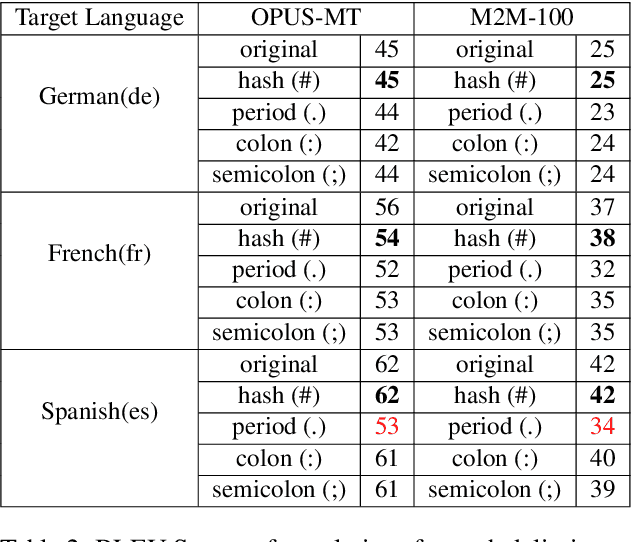
Neural Machine Translation systems built on top of Transformer-based architectures are routinely improving the state-of-the-art in translation quality according to word-overlap metrics. However, a growing number of studies also highlight the inherent gender bias that these models incorporate during training, which reflects poorly in their translations. In this work, we investigate whether these models can be instructed to fix their bias during inference using targeted, guided instructions as contexts. By translating relevant contextual sentences during inference along with the input, we observe large improvements in reducing the gender bias in translations, across three popular test suites (WinoMT, BUG, SimpleGen). We further propose a novel metric to assess several large pretrained models (OPUS-MT, M2M-100) on their sensitivity towards using contexts during translation to correct their biases. Our approach requires no fine-tuning, and thus can be used easily in production systems to de-bias translations from stereotypical gender-occupation bias. We hope our method, along with our metric, can be used to build better, bias-free translation systems.
Evaluating Gender Bias in Natural Language Inference
May 12, 2021
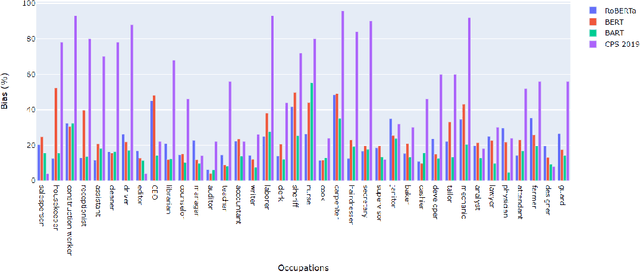
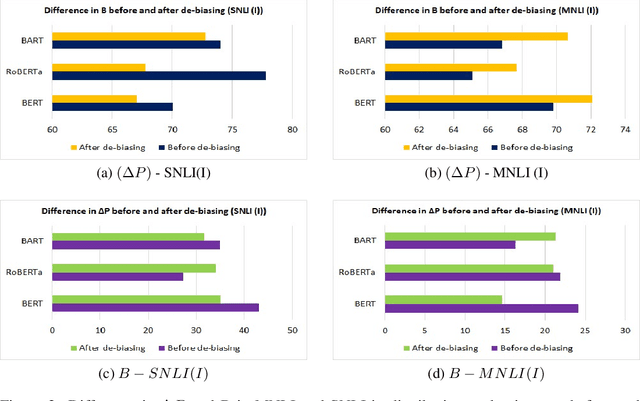

Gender-bias stereotypes have recently raised significant ethical concerns in natural language processing. However, progress in detection and evaluation of gender bias in natural language understanding through inference is limited and requires further investigation. In this work, we propose an evaluation methodology to measure these biases by constructing a challenge task that involves pairing gender-neutral premises against a gender-specific hypothesis. We use our challenge task to investigate state-of-the-art NLI models on the presence of gender stereotypes using occupations. Our findings suggest that three models (BERT, RoBERTa, BART) trained on MNLI and SNLI datasets are significantly prone to gender-induced prediction errors. We also find that debiasing techniques such as augmenting the training dataset to ensure a gender-balanced dataset can help reduce such bias in certain cases.
Sometimes We Want Translationese
Apr 15, 2021
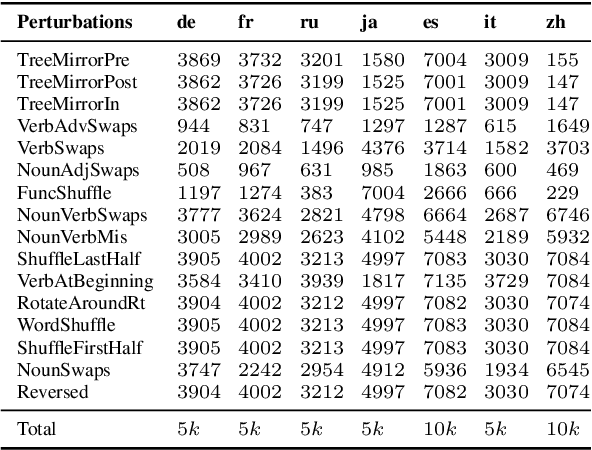

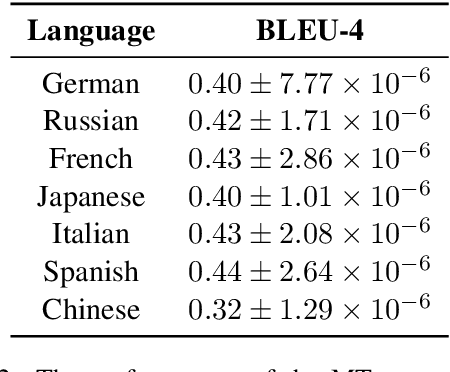
Rapid progress in Neural Machine Translation (NMT) systems over the last few years has been driven primarily towards improving translation quality, and as a secondary focus, improved robustness to input perturbations (e.g. spelling and grammatical mistakes). While performance and robustness are important objectives, by over-focusing on these, we risk overlooking other important properties. In this paper, we draw attention to the fact that for some applications, faithfulness to the original (input) text is important to preserve, even if it means introducing unusual language patterns in the (output) translation. We propose a simple, novel way to quantify whether an NMT system exhibits robustness and faithfulness, focusing on the case of word-order perturbations. We explore a suite of functions to perturb the word order of source sentences without deleting or injecting tokens, and measure the effects on the target side in terms of both robustness and faithfulness. Across several experimental conditions, we observe a strong tendency towards robustness rather than faithfulness. These results allow us to better understand the trade-off between faithfulness and robustness in NMT, and opens up the possibility of developing systems where users have more autonomy and control in selecting which property is best suited for their use case.
Masked Language Modeling and the Distributional Hypothesis: Order Word Matters Pre-training for Little
Apr 14, 2021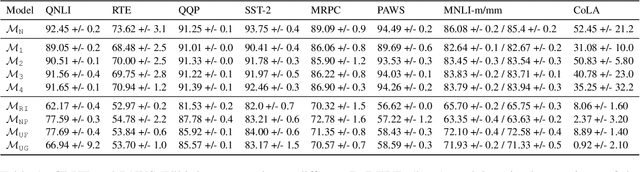
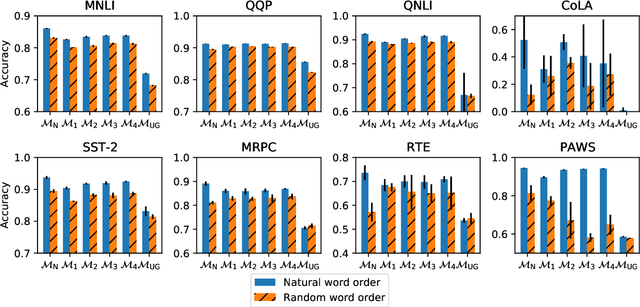
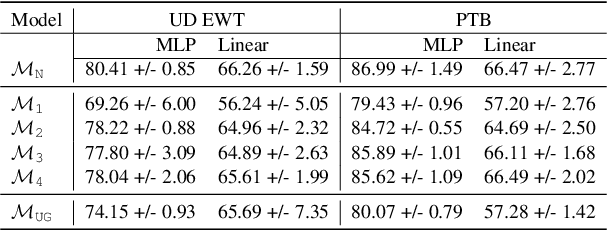
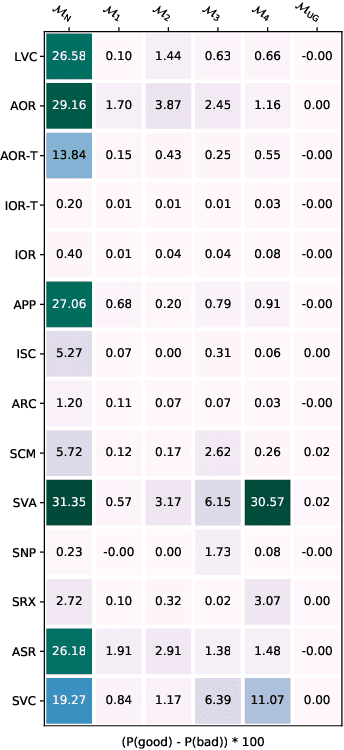
A possible explanation for the impressive performance of masked language model (MLM) pre-training is that such models have learned to represent the syntactic structures prevalent in classical NLP pipelines. In this paper, we propose a different explanation: MLMs succeed on downstream tasks almost entirely due to their ability to model higher-order word co-occurrence statistics. To demonstrate this, we pre-train MLMs on sentences with randomly shuffled word order, and show that these models still achieve high accuracy after fine-tuning on many downstream tasks -- including on tasks specifically designed to be challenging for models that ignore word order. Our models perform surprisingly well according to some parametric syntactic probes, indicating possible deficiencies in how we test representations for syntactic information. Overall, our results show that purely distributional information largely explains the success of pre-training, and underscore the importance of curating challenging evaluation datasets that require deeper linguistic knowledge.
COVID-19 Prognosis via Self-Supervised Representation Learning and Multi-Image Prediction
Jan 25, 2021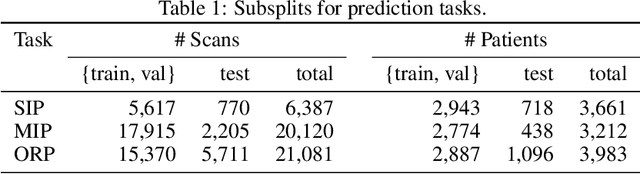
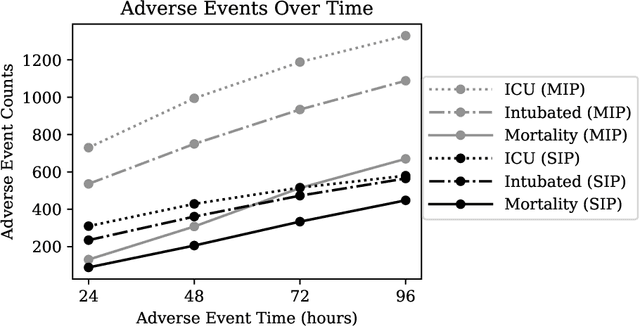
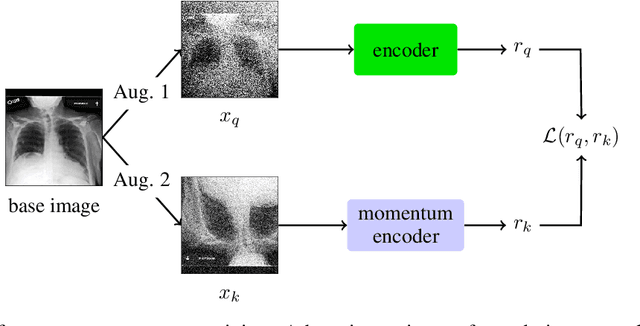
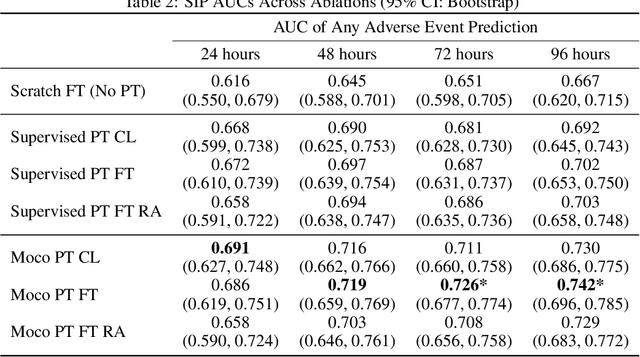
The rapid spread of COVID-19 cases in recent months has strained hospital resources, making rapid and accurate triage of patients presenting to emergency departments a necessity. Machine learning techniques using clinical data such as chest X-rays have been used to predict which patients are most at risk of deterioration. We consider the task of predicting two types of patient deterioration based on chest X-rays: adverse event deterioration (i.e., transfer to the intensive care unit, intubation, or mortality) and increased oxygen requirements beyond 6 L per day. Due to the relative scarcity of COVID-19 patient data, existing solutions leverage supervised pretraining on related non-COVID images, but this is limited by the differences between the pretraining data and the target COVID-19 patient data. In this paper, we use self-supervised learning based on the momentum contrast (MoCo) method in the pretraining phase to learn more general image representations to use for downstream tasks. We present three results. The first is deterioration prediction from a single image, where our model achieves an area under receiver operating characteristic curve (AUC) of 0.742 for predicting an adverse event within 96 hours (compared to 0.703 with supervised pretraining) and an AUC of 0.765 for predicting oxygen requirements greater than 6 L a day at 24 hours (compared to 0.749 with supervised pretraining). We then propose a new transformer-based architecture that can process sequences of multiple images for prediction and show that this model can achieve an improved AUC of 0.786 for predicting an adverse event at 96 hours and an AUC of 0.848 for predicting mortalities at 96 hours. A small pilot clinical study suggested that the prediction accuracy of our model is comparable to that of experienced radiologists analyzing the same information.