 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepAudio 2.5 Technical Report
May 22, 2026Unified audio-language modeling has emerged as a prominent trend in modern speech systems, promising to bring the reasoning capabilities of large language models to auditory tasks. However, existing unified foundations often struggle to match the depth of specialized systems across automatic speech recognition (ASR), text-to-speech synthesis (TTS), and realtime spoken interaction. Bridging this gap remains an open challenge. This report presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across all three capabilities. Rather than treating these tasks as architecturally distinct, we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes: data construction, optimization targets, and decoding constraints. Guided by this insight, we advance the post-training paradigm from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF), using it as the primary mechanism to define complex optimization targets. We leverage this RLHF-centric alignment, alongside specialized decoding, to shape a shared backbone into three distinct operational modes. Concretely, the ASR branch advances transcription efficiency via verifiable multi-token decoding; the TTS branch achieves controllable, expressive synthesis through preference-based RLHF and context-rich supervision; and the Realtime branch realizes low-latency, persona-consistent dialogue via generative reward modeling within an RLHF framework. On standard benchmarks, StepAudio 2.5 achieves state-of-the-art results across ASR, TTS, and Realtime, demonstrating that a singular audio-language foundation can successfully internalize the distinct deployment objectives of speech understanding, generation, and live interaction.
JoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
The Voice Timbre Attribute Detection 2025 Challenge Evaluation Plan
May 14, 2025Voice timbre refers to the unique quality or character of a person's voice that distinguishes it from others as perceived by human hearing. The Voice Timbre Attribute Detection (VtaD) 2025 challenge focuses on explaining the voice timbre attribute in a comparative manner. In this challenge, the human impression of voice timbre is verbalized with a set of sensory descriptors, including bright, coarse, soft, magnetic, and so on. The timbre is explained from the comparison between two voices in their intensity within a specific descriptor dimension. The VtaD 2025 challenge starts in May and culminates in a special proposal at the NCMMSC2025 conference in October 2025 in Zhenjiang, China.
Introducing voice timbre attribute detection
May 14, 2025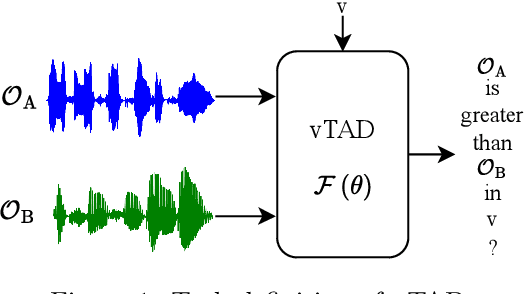
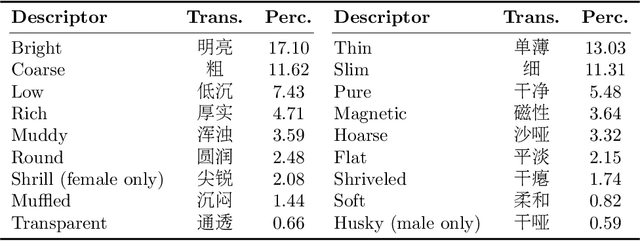
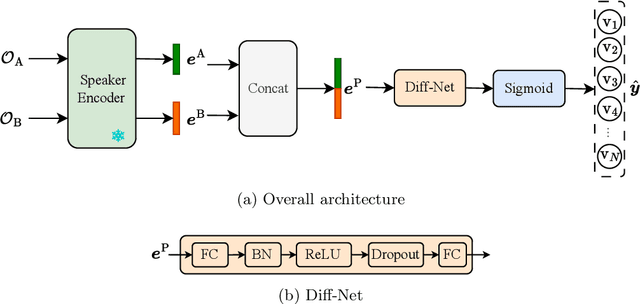
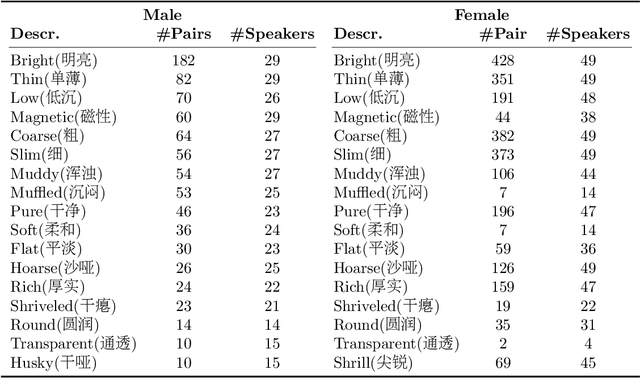
This paper focuses on explaining the timbre conveyed by speech signals and introduces a task termed voice timbre attribute detection (vTAD). In this task, voice timbre is explained with a set of sensory attributes describing its human perception. A pair of speech utterances is processed, and their intensity is compared in a designated timbre descriptor. Moreover, a framework is proposed, which is built upon the speaker embeddings extracted from the speech utterances. The investigation is conducted on the VCTK-RVA dataset. Experimental examinations on the ECAPA-TDNN and FACodec speaker encoders demonstrated that: 1) the ECAPA-TDNN speaker encoder was more capable in the seen scenario, where the testing speakers were included in the training set; 2) the FACodec speaker encoder was superior in the unseen scenario, where the testing speakers were not part of the training, indicating enhanced generalization capability. The VCTK-RVA dataset and open-source code are available on the website https://github.com/vTAD2025-Challenge/vTAD.
Unispeaker: A Unified Approach for Multimodality-driven Speaker Generation
Jan 11, 2025



Recent advancements in personalized speech generation have brought synthetic speech increasingly close to the realism of target speakers' recordings, yet multimodal speaker generation remains on the rise. This paper introduces UniSpeaker, a unified approach for multimodality-driven speaker generation. Specifically, we propose a unified voice aggregator based on KV-Former, applying soft contrastive loss to map diverse voice description modalities into a shared voice space, ensuring that the generated voice aligns more closely with the input descriptions. To evaluate multimodality-driven voice control, we build the first multimodality-based voice control (MVC) benchmark, focusing on voice suitability, voice diversity, and speech quality. UniSpeaker is evaluated across five tasks using the MVC benchmark, and the experimental results demonstrate that UniSpeaker outperforms previous modality-specific models. Speech samples are available at \url{https://UniSpeaker.github.io}.
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Dec 13, 2024



In our previous work, we introduced CosyVoice, a multilingual speech synthesis model based on supervised discrete speech tokens. By employing progressive semantic decoding with two popular generative models, language models (LMs) and Flow Matching, CosyVoice demonstrated high prosody naturalness, content consistency, and speaker similarity in speech in-context learning. Recently, significant progress has been made in multi-modal large language models (LLMs), where the response latency and real-time factor of speech synthesis play a crucial role in the interactive experience. Therefore, in this report, we present an improved streaming speech synthesis model, CosyVoice 2, which incorporates comprehensive and systematic optimizations. Specifically, we introduce finite-scalar quantization to improve the codebook utilization of speech tokens. For the text-speech LM, we streamline the model architecture to allow direct use of a pre-trained LLM as the backbone. In addition, we develop a chunk-aware causal flow matching model to support various synthesis scenarios, enabling both streaming and non-streaming synthesis within a single model. By training on a large-scale multilingual dataset, CosyVoice 2 achieves human-parity naturalness, minimal response latency, and virtually lossless synthesis quality in the streaming mode. We invite readers to listen to the demos at https://funaudiollm.github.io/cosyvoice2.
Voice Attribute Editing with Text Prompt
Apr 13, 2024



Despite recent advancements in speech generation with text prompt providing control over speech style, voice attributes in synthesized speech remain elusive and challenging to control. This paper introduces a novel task: voice attribute editing with text prompt, with the goal of making relative modifications to voice attributes according to the actions described in the text prompt. To solve this task, VoxEditor, an end-to-end generative model, is proposed. In VoxEditor, addressing the insufficiency of text prompt, a Residual Memory (ResMem) block is designed, that efficiently maps voice attributes and these descriptors into the shared feature space. Additionally, the ResMem block is enhanced with a voice attribute degree prediction (VADP) block to align voice attributes with corresponding descriptors, addressing the imprecision of text prompt caused by non-quantitative descriptions of voice attributes. We also establish the open-source VCTK-RVA dataset, which leads the way in manual annotations detailing voice characteristic differences among different speakers. Extensive experiments demonstrate the effectiveness and generalizability of our proposed method in terms of both objective and subjective metrics. The dataset and audio samples are available on the website.