 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of the Removability of Speaker-Adversarial Perturbations
Paper and Code
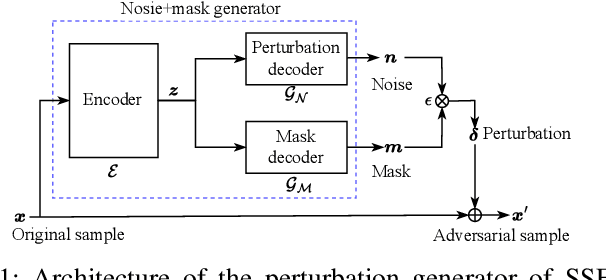
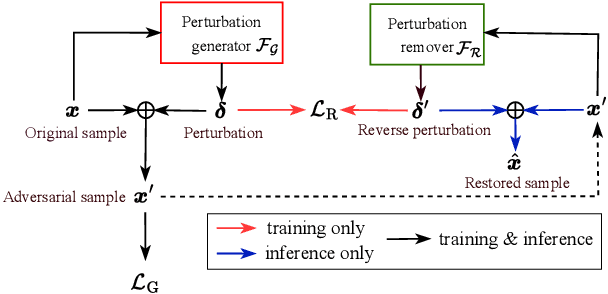
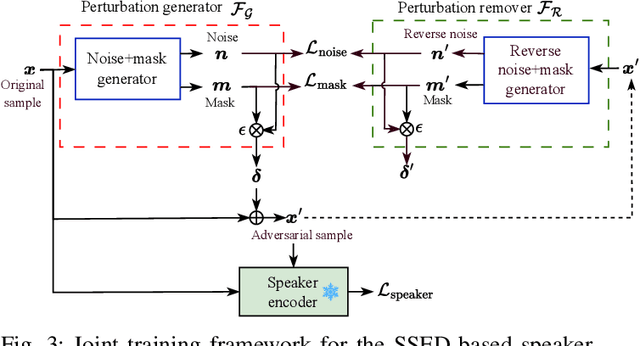

Recent advancements in adversarial attacks have demonstrated their effectiveness in misleading speaker recognition models, making wrong predictions about speaker identities. On the other hand, defense techniques against speaker-adversarial attacks focus on reducing the effects of speaker-adversarial perturbations on speaker attribute extraction. These techniques do not seek to fully remove the perturbations and restore the original speech. To this end, this paper studies the removability of speaker-adversarial perturbations. Specifically, the investigation is conducted assuming various degrees of awareness of the perturbation generator across three scenarios: ignorant, semi-informed, and well-informed. Besides, we consider both the optimization-based and feedforward perturbation generation methods. Experiments conducted on the LibriSpeech dataset demonstrated that: 1) in the ignorant scenario, speaker-adversarial perturbations cannot be eliminated, although their impact on speaker attribute extraction is reduced, 2) in the semi-informed scenario, the speaker-adversarial perturbations cannot be fully removed, while those generated by the feedforward model can be considerably reduced, and 3) in the well-informed scenario, speaker-adversarial perturbations are nearly eliminated, allowing for the restoration of the original speech. Audio samples can be found in https://voiceprivacy.github.io/Perturbation-Generation-Removal/.