 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing voice timbre attribute detection
Paper and Code
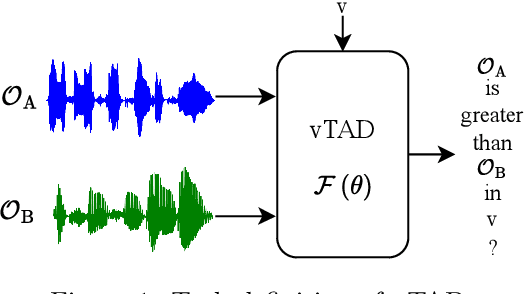
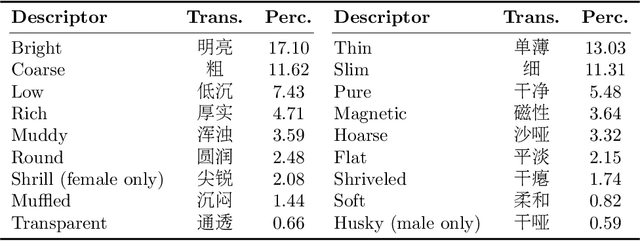
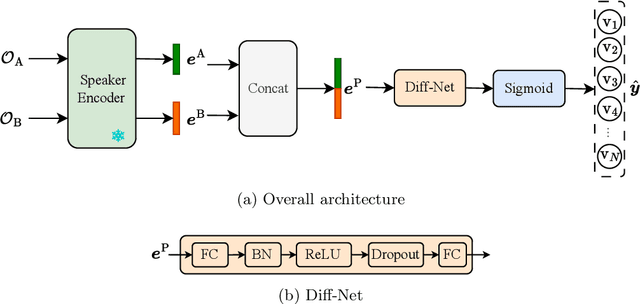
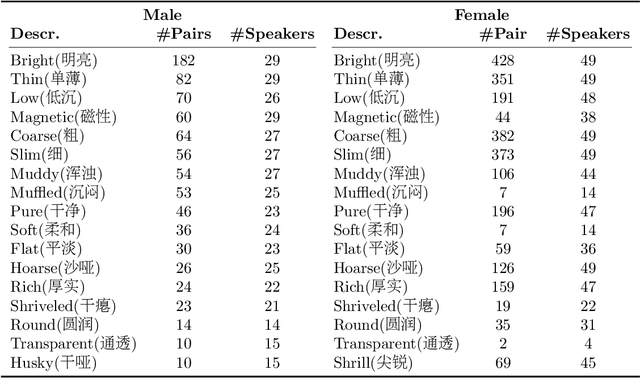
This paper focuses on explaining the timbre conveyed by speech signals and introduces a task termed voice timbre attribute detection (vTAD). In this task, voice timbre is explained with a set of sensory attributes describing its human perception. A pair of speech utterances is processed, and their intensity is compared in a designated timbre descriptor. Moreover, a framework is proposed, which is built upon the speaker embeddings extracted from the speech utterances. The investigation is conducted on the VCTK-RVA dataset. Experimental examinations on the ECAPA-TDNN and FACodec speaker encoders demonstrated that: 1) the ECAPA-TDNN speaker encoder was more capable in the seen scenario, where the testing speakers were included in the training set; 2) the FACodec speaker encoder was superior in the unseen scenario, where the testing speakers were not part of the training, indicating enhanced generalization capability. The VCTK-RVA dataset and open-source code are available on the website https://github.com/vTAD2025-Challenge/vTAD.