 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInclusive, Differentially Private Federated Learning for Clinical Data
May 28, 2025Federated Learning (FL) offers a promising approach for training clinical AI models without centralizing sensitive patient data. However, its real-world adoption is hindered by challenges related to privacy, resource constraints, and compliance. Existing Differential Privacy (DP) approaches often apply uniform noise, which disproportionately degrades model performance, even among well-compliant institutions. In this work, we propose a novel compliance-aware FL framework that enhances DP by adaptively adjusting noise based on quantifiable client compliance scores. Additionally, we introduce a compliance scoring tool based on key healthcare and security standards to promote secure, inclusive, and equitable participation across diverse clinical settings. Extensive experiments on public datasets demonstrate that integrating under-resourced, less compliant clinics with highly regulated institutions yields accuracy improvements of up to 15% over traditional FL. This work advances FL by balancing privacy, compliance, and performance, making it a viable solution for real-world clinical workflows in global healthcare.
Advances in Automated Fetal Brain MRI Segmentation and Biometry: Insights from the FeTA 2024 Challenge
May 05, 2025


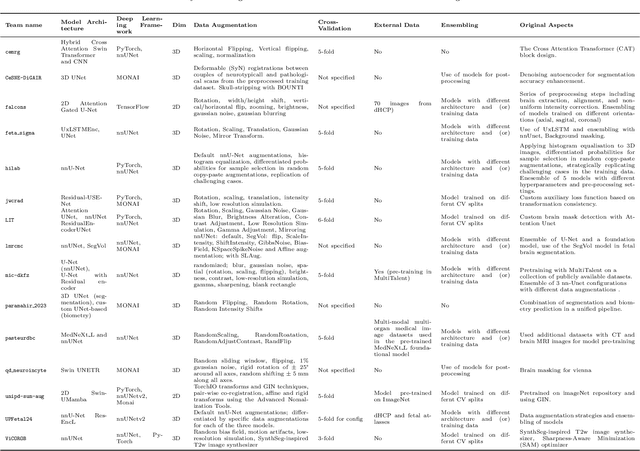
Accurate fetal brain tissue segmentation and biometric analysis are essential for studying brain development in utero. The FeTA Challenge 2024 advanced automated fetal brain MRI analysis by introducing biometry prediction as a new task alongside tissue segmentation. For the first time, our diverse multi-centric test set included data from a new low-field (0.55T) MRI dataset. Evaluation metrics were also expanded to include the topology-specific Euler characteristic difference (ED). Sixteen teams submitted segmentation methods, most of which performed consistently across both high- and low-field scans. However, longitudinal trends indicate that segmentation accuracy may be reaching a plateau, with results now approaching inter-rater variability. The ED metric uncovered topological differences that were missed by conventional metrics, while the low-field dataset achieved the highest segmentation scores, highlighting the potential of affordable imaging systems when paired with high-quality reconstruction. Seven teams participated in the biometry task, but most methods failed to outperform a simple baseline that predicted measurements based solely on gestational age, underscoring the challenge of extracting reliable biometric estimates from image data alone. Domain shift analysis identified image quality as the most significant factor affecting model generalization, with super-resolution pipelines also playing a substantial role. Other factors, such as gestational age, pathology, and acquisition site, had smaller, though still measurable, effects. Overall, FeTA 2024 offers a comprehensive benchmark for multi-class segmentation and biometry estimation in fetal brain MRI, underscoring the need for data-centric approaches, improved topological evaluation, and greater dataset diversity to enable clinically robust and generalizable AI tools.
nnLandmark: A Self-Configuring Method for 3D Medical Landmark Detection
Apr 10, 2025Landmark detection plays a crucial role in medical imaging tasks that rely on precise spatial localization, including specific applications in diagnosis, treatment planning, image registration, and surgical navigation. However, manual annotation is labor-intensive and requires expert knowledge. While deep learning shows promise in automating this task, progress is hindered by limited public datasets, inconsistent benchmarks, and non-standardized baselines, restricting reproducibility, fair comparisons, and model generalizability. This work introduces nnLandmark, a self-configuring deep learning framework for 3D medical landmark detection, adapting nnU-Net to perform heatmap-based regression. By leveraging nnU-Net's automated configuration, nnLandmark eliminates the need for manual parameter tuning, offering out-of-the-box usability. It achieves state-of-the-art accuracy across two public datasets, with a mean radial error (MRE) of 1.5 mm on the Mandibular Molar Landmark (MML) dental CT dataset and 1.2 mm for anatomical fiducials on a brain MRI dataset (AFIDs), where nnLandmark aligns with the inter-rater variability of 1.5 mm. With its strong generalization, reproducibility, and ease of deployment, nnLandmark establishes a reliable baseline for 3D landmark detection, supporting research in anatomical localization and clinical workflows that depend on precise landmark identification. The code will be available soon.
Benchmark of Segmentation Techniques for Pelvic Fracture in CT and X-ray: Summary of the PENGWIN 2024 Challenge
Apr 03, 2025The segmentation of pelvic fracture fragments in CT and X-ray images is crucial for trauma diagnosis, surgical planning, and intraoperative guidance. However, accurately and efficiently delineating the bone fragments remains a significant challenge due to complex anatomy and imaging limitations. The PENGWIN challenge, organized as a MICCAI 2024 satellite event, aimed to advance automated fracture segmentation by benchmarking state-of-the-art algorithms on these complex tasks. A diverse dataset of 150 CT scans was collected from multiple clinical centers, and a large set of simulated X-ray images was generated using the DeepDRR method. Final submissions from 16 teams worldwide were evaluated under a rigorous multi-metric testing scheme. The top-performing CT algorithm achieved an average fragment-wise intersection over union (IoU) of 0.930, demonstrating satisfactory accuracy. However, in the X-ray task, the best algorithm attained an IoU of 0.774, highlighting the greater challenges posed by overlapping anatomical structures. Beyond the quantitative evaluation, the challenge revealed methodological diversity in algorithm design. Variations in instance representation, such as primary-secondary classification versus boundary-core separation, led to differing segmentation strategies. Despite promising results, the challenge also exposed inherent uncertainties in fragment definition, particularly in cases of incomplete fractures. These findings suggest that interactive segmentation approaches, integrating human decision-making with task-relevant information, may be essential for improving model reliability and clinical applicability.
Enhanced Diagnostic Fidelity in Pathology Whole Slide Image Compression via Deep Learning
Mar 14, 2025Accurate diagnosis of disease often depends on the exhaustive examination of Whole Slide Images (WSI) at microscopic resolution. Efficient handling of these data-intensive images requires lossy compression techniques. This paper investigates the limitations of the widely-used JPEG algorithm, the current clinical standard, and reveals severe image artifacts impacting diagnostic fidelity. To overcome these challenges, we introduce a novel deep-learning (DL)-based compression method tailored for pathology images. By enforcing feature similarity of deep features between the original and compressed images, our approach achieves superior Peak Signal-to-Noise Ratio (PSNR), Multi-Scale Structural Similarity Index (MS-SSIM), and Learned Perceptual Image Patch Similarity (LPIPS) scores compared to JPEG-XL, Webp, and other DL compression methods.
nnInteractive: Redefining 3D Promptable Segmentation
Mar 11, 2025



Accurate and efficient 3D segmentation is essential for both clinical and research applications. While foundation models like SAM have revolutionized interactive segmentation, their 2D design and domain shift limitations make them ill-suited for 3D medical images. Current adaptations address some of these challenges but remain limited, either lacking volumetric awareness, offering restricted interactivity, or supporting only a small set of structures and modalities. Usability also remains a challenge, as current tools are rarely integrated into established imaging platforms and often rely on cumbersome web-based interfaces with restricted functionality. We introduce nnInteractive, the first comprehensive 3D interactive open-set segmentation method. It supports diverse prompts-including points, scribbles, boxes, and a novel lasso prompt-while leveraging intuitive 2D interactions to generate full 3D segmentations. Trained on 120+ diverse volumetric 3D datasets (CT, MRI, PET, 3D Microscopy, etc.), nnInteractive sets a new state-of-the-art in accuracy, adaptability, and usability. Crucially, it is the first method integrated into widely used image viewers (e.g., Napari, MITK), ensuring broad accessibility for real-world clinical and research applications. Extensive benchmarking demonstrates that nnInteractive far surpasses existing methods, setting a new standard for AI-driven interactive 3D segmentation. nnInteractive is publicly available: https://github.com/MIC-DKFZ/napari-nninteractive (Napari plugin), https://www.mitk.org/MITK-nnInteractive (MITK integration), https://github.com/MIC-DKFZ/nnInteractive (Python backend).
Primus: Enforcing Attention Usage for 3D Medical Image Segmentation
Mar 03, 2025



Transformers have achieved remarkable success across multiple fields, yet their impact on 3D medical image segmentation remains limited with convolutional networks still dominating major benchmarks. In this work, we a) analyze current Transformer-based segmentation models and identify critical shortcomings, particularly their over-reliance on convolutional blocks. Further, we demonstrate that in some architectures, performance is unaffected by the absence of the Transformer, thereby demonstrating their limited effectiveness. To address these challenges, we move away from hybrid architectures and b) introduce a fully Transformer-based segmentation architecture, termed Primus. Primus leverages high-resolution tokens, combined with advances in positional embeddings and block design, to maximally leverage its Transformer blocks. Through these adaptations Primus surpasses current Transformer-based methods and competes with state-of-the-art convolutional models on multiple public datasets. By doing so, we create the first pure Transformer architecture and take a significant step towards making Transformers state-of-the-art for 3D medical image segmentation.
LesionLocator: Zero-Shot Universal Tumor Segmentation and Tracking in 3D Whole-Body Imaging
Feb 28, 2025In this work, we present LesionLocator, a framework for zero-shot longitudinal lesion tracking and segmentation in 3D medical imaging, establishing the first end-to-end model capable of 4D tracking with dense spatial prompts. Our model leverages an extensive dataset of 23,262 annotated medical scans, as well as synthesized longitudinal data across diverse lesion types. The diversity and scale of our dataset significantly enhances model generalizability to real-world medical imaging challenges and addresses key limitations in longitudinal data availability. LesionLocator outperforms all existing promptable models in lesion segmentation by nearly 10 dice points, reaching human-level performance, and achieves state-of-the-art results in lesion tracking, with superior lesion retrieval and segmentation accuracy. LesionLocator not only sets a new benchmark in universal promptable lesion segmentation and automated longitudinal lesion tracking but also provides the first open-access solution of its kind, releasing our synthetic 4D dataset and model to the community, empowering future advancements in medical imaging. Code is available at: www.github.com/MIC-DKFZ/LesionLocator
Bridging vision language model (VLM) evaluation gaps with a framework for scalable and cost-effective benchmark generation
Feb 21, 2025



Reliable evaluation of AI models is critical for scientific progress and practical application. While existing VLM benchmarks provide general insights into model capabilities, their heterogeneous designs and limited focus on a few imaging domains pose significant challenges for both cross-domain performance comparison and targeted domain-specific evaluation. To address this, we propose three key contributions: (1) a framework for the resource-efficient creation of domain-specific VLM benchmarks enabled by task augmentation for creating multiple diverse tasks from a single existing task, (2) the release of new VLM benchmarks for seven domains, created according to the same homogeneous protocol and including 162,946 thoroughly human-validated answers, and (3) an extensive benchmarking of 22 state-of-the-art VLMs on a total of 37,171 tasks, revealing performance variances across domains and tasks, thereby supporting the need for tailored VLM benchmarks. Adoption of our methodology will pave the way for the resource-efficient domain-specific selection of models and guide future research efforts toward addressing core open questions.
Tumor Detection, Segmentation and Classification Challenge on Automated 3D Breast Ultrasound: The TDSC-ABUS Challenge
Jan 26, 2025



Breast cancer is one of the most common causes of death among women worldwide. Early detection helps in reducing the number of deaths. Automated 3D Breast Ultrasound (ABUS) is a newer approach for breast screening, which has many advantages over handheld mammography such as safety, speed, and higher detection rate of breast cancer. Tumor detection, segmentation, and classification are key components in the analysis of medical images, especially challenging in the context of 3D ABUS due to the significant variability in tumor size and shape, unclear tumor boundaries, and a low signal-to-noise ratio. The lack of publicly accessible, well-labeled ABUS datasets further hinders the advancement of systems for breast tumor analysis. Addressing this gap, we have organized the inaugural Tumor Detection, Segmentation, and Classification Challenge on Automated 3D Breast Ultrasound 2023 (TDSC-ABUS2023). This initiative aims to spearhead research in this field and create a definitive benchmark for tasks associated with 3D ABUS image analysis. In this paper, we summarize the top-performing algorithms from the challenge and provide critical analysis for ABUS image examination. We offer the TDSC-ABUS challenge as an open-access platform at https://tdsc-abus2023.grand-challenge.org/ to benchmark and inspire future developments in algorithmic research.