 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Vision-Language Pre-training from the Lens of Multimodal Machine Translation
Jun 12, 2023



Large language models such as BERT and the GPT series started a paradigm shift that calls for building general-purpose models via pre-training on large datasets, followed by fine-tuning on task-specific datasets. There is now a plethora of large pre-trained models for Natural Language Processing and Computer Vision. Recently, we have seen rapid developments in the joint Vision-Language space as well, where pre-trained models such as CLIP (Radford et al., 2021) have demonstrated improvements in downstream tasks like image captioning and visual question answering. However, surprisingly there is comparatively little work on exploring these models for the task of multimodal machine translation, where the goal is to leverage image/video modality in text-to-text translation. To fill this gap, this paper surveys the landscape of language-and-vision pre-training from the lens of multimodal machine translation. We summarize the common architectures, pre-training objectives, and datasets from literature and conjecture what further is needed to make progress on multimodal machine translation.
Exploring Representational Disparities Between Multilingual and Bilingual Translation Models
May 23, 2023Multilingual machine translation has proven immensely useful for low-resource and zero-shot language pairs. However, language pairs in multilingual models sometimes see worse performance than in bilingual models, especially when translating in a one-to-many setting. To understand why, we examine the geometric differences in the representations from bilingual models versus those from one-to-many multilingual models. Specifically, we evaluate the isotropy of the representations, to measure how well they utilize the dimensions in their underlying vector space. Using the same evaluation data in both models, we find that multilingual model decoder representations tend to be less isotropic than bilingual model decoder representations. Additionally, we show that much of the anisotropy in multilingual decoder representations can be attributed to modeling language-specific information, therefore limiting remaining representational capacity.
In-context Learning as Maintaining Coherency: A Study of On-the-fly Machine Translation Using Large Language Models
May 05, 2023



The phenomena of in-context learning has typically been thought of as "learning from examples". In this work which focuses on Machine Translation, we present a perspective of in-context learning as the desired generation task maintaining coherency with its context, i.e., the prompt examples. We first investigate randomly sampled prompts across 4 domains, and find that translation performance improves when shown in-domain prompts. Next, we investigate coherency for the in-domain setting, which uses prompt examples from a moving window. We study this with respect to other factors that have previously been identified in the literature such as length, surface similarity and sentence embedding similarity. Our results across 3 models (GPTNeo2.7B, Bloom3B, XGLM2.9B), and three translation directions (\texttt{en}$\rightarrow$\{\texttt{pt, de, fr}\}) suggest that the long-term coherency of the prompts and the test sentence is a good indicator of downstream translation performance. In doing so, we demonstrate the efficacy of In-context Machine Translation for on-the-fly adaptation.
Bilingual Lexicon Induction for Low-Resource Languages using Graph Matching via Optimal Transport
Oct 25, 2022



Bilingual lexicons form a critical component of various natural language processing applications, including unsupervised and semisupervised machine translation and crosslingual information retrieval. We improve bilingual lexicon induction performance across 40 language pairs with a graph-matching method based on optimal transport. The method is especially strong with low amounts of supervision.
IsoVec: Controlling the Relative Isomorphism of Word Embedding Spaces
Oct 11, 2022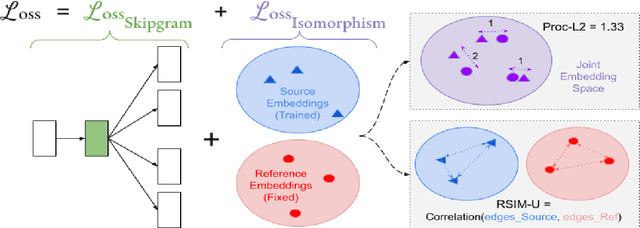
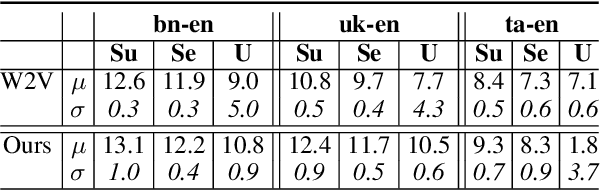

The ability to extract high-quality translation dictionaries from monolingual word embedding spaces depends critically on the geometric similarity of the spaces -- their degree of "isomorphism." We address the root-cause of faulty cross-lingual mapping: that word embedding training resulted in the underlying spaces being non-isomorphic. We incorporate global measures of isomorphism directly into the skipgram loss function, successfully increasing the relative isomorphism of trained word embedding spaces and improving their ability to be mapped to a shared cross-lingual space. The result is improved bilingual lexicon induction in general data conditions, under domain mismatch, and with training algorithm dissimilarities. We release IsoVec at https://github.com/kellymarchisio/isovec.
Transfer Learning Approaches for Building Cross-Language Dense Retrieval Models
Jan 20, 2022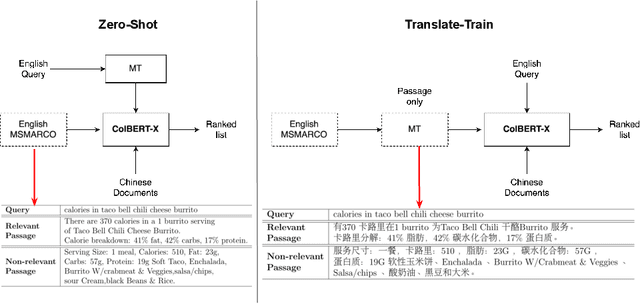
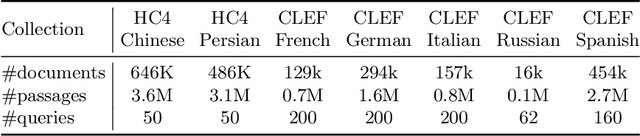
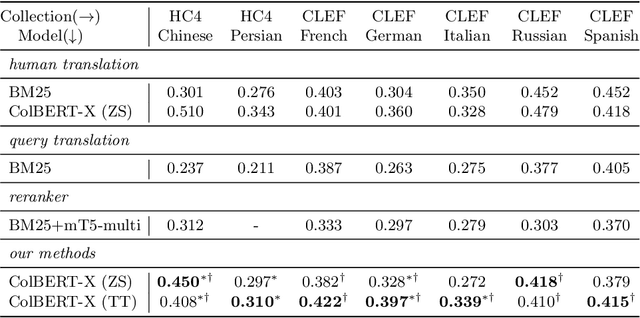
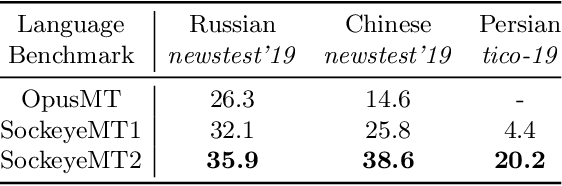
The advent of transformer-based models such as BERT has led to the rise of neural ranking models. These models have improved the effectiveness of retrieval systems well beyond that of lexical term matching models such as BM25. While monolingual retrieval tasks have benefited from large-scale training collections such as MS MARCO and advances in neural architectures, cross-language retrieval tasks have fallen behind these advancements. This paper introduces ColBERT-X, a generalization of the ColBERT multi-representation dense retrieval model that uses the XLM-RoBERTa (XLM-R) encoder to support cross-language information retrieval (CLIR). ColBERT-X can be trained in two ways. In zero-shot training, the system is trained on the English MS MARCO collection, relying on the XLM-R encoder for cross-language mappings. In translate-train, the system is trained on the MS MARCO English queries coupled with machine translations of the associated MS MARCO passages. Results on ad hoc document ranking tasks in several languages demonstrate substantial and statistically significant improvements of these trained dense retrieval models over traditional lexical CLIR baselines.
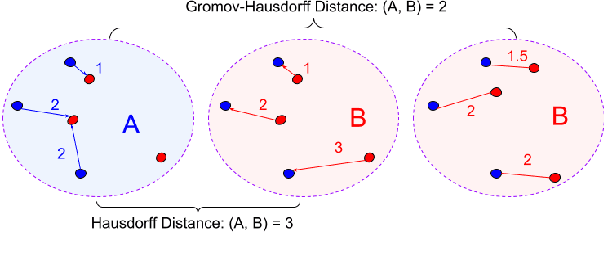
An Analysis of Euclidean vs. Graph-Based Framing for Bilingual Lexicon Induction from Word Embedding Spaces
Sep 26, 2021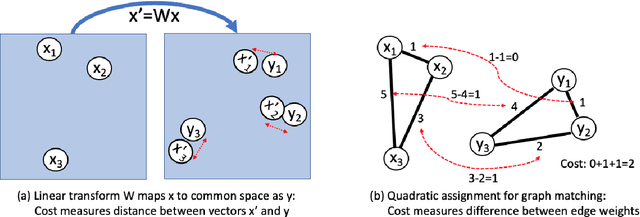

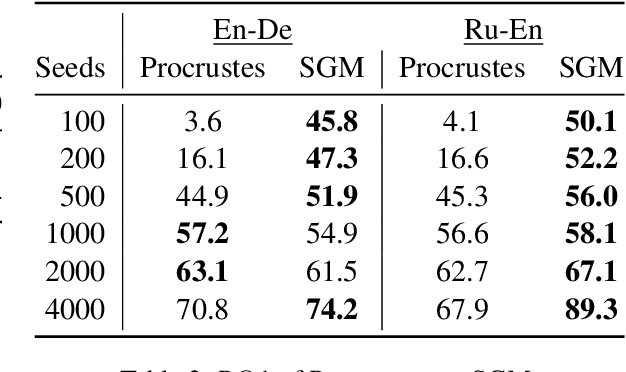
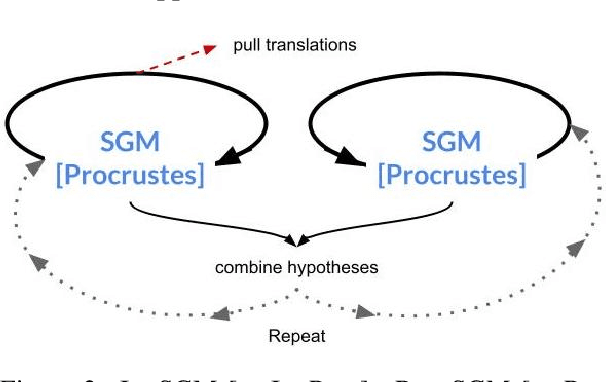
Much recent work in bilingual lexicon induction (BLI) views word embeddings as vectors in Euclidean space. As such, BLI is typically solved by finding a linear transformation that maps embeddings to a common space. Alternatively, word embeddings may be understood as nodes in a weighted graph. This framing allows us to examine a node's graph neighborhood without assuming a linear transform, and exploits new techniques from the graph matching optimization literature. These contrasting approaches have not been compared in BLI so far. In this work, we study the behavior of Euclidean versus graph-based approaches to BLI under differing data conditions and show that they complement each other when combined. We release our code at https://github.com/kellymarchisio/euc-v-graph-bli.
Non-autoregressive End-to-end Speech Translation with Parallel Autoregressive Rescoring
Sep 09, 2021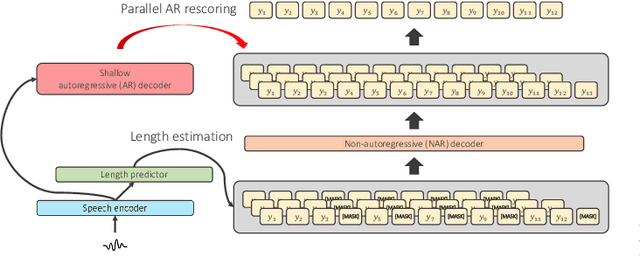
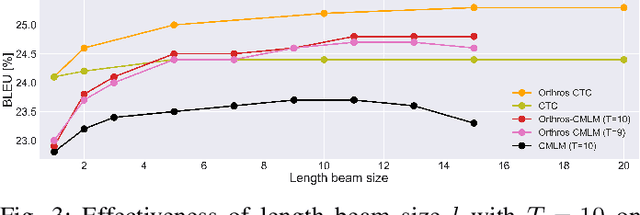
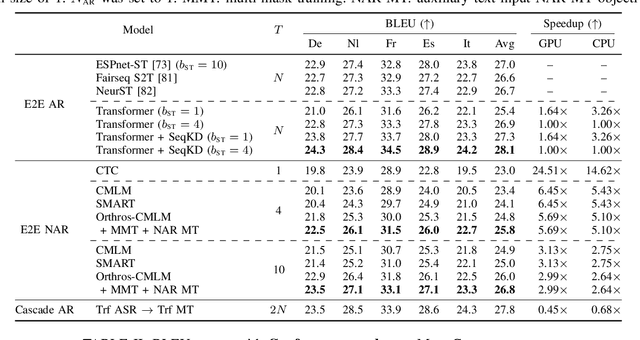
This article describes an efficient end-to-end speech translation (E2E-ST) framework based on non-autoregressive (NAR) models. End-to-end speech translation models have several advantages over traditional cascade systems such as inference latency reduction. However, conventional AR decoding methods are not fast enough because each token is generated incrementally. NAR models, however, can accelerate the decoding speed by generating multiple tokens in parallel on the basis of the token-wise conditional independence assumption. We propose a unified NAR E2E-ST framework called Orthros, which has an NAR decoder and an auxiliary shallow AR decoder on top of the shared encoder. The auxiliary shallow AR decoder selects the best hypothesis by rescoring multiple candidates generated from the NAR decoder in parallel (parallel AR rescoring). We adopt conditional masked language model (CMLM) and a connectionist temporal classification (CTC)-based model as NAR decoders for Orthros, referred to as Orthros-CMLM and Orthros-CTC, respectively. We also propose two training methods to enhance the CMLM decoder. Experimental evaluations on three benchmark datasets with six language directions demonstrated that Orthros achieved large improvements in translation quality with a very small overhead compared with the baseline NAR model. Moreover, the Conformer encoder architecture enabled large quality improvements, especially for CTC-based models. Orthros-CTC with the Conformer encoder increased decoding speed by 3.63x on CPU with translation quality comparable to that of an AR model.
ESPnet-ST IWSLT 2021 Offline Speech Translation System
Jul 06, 2021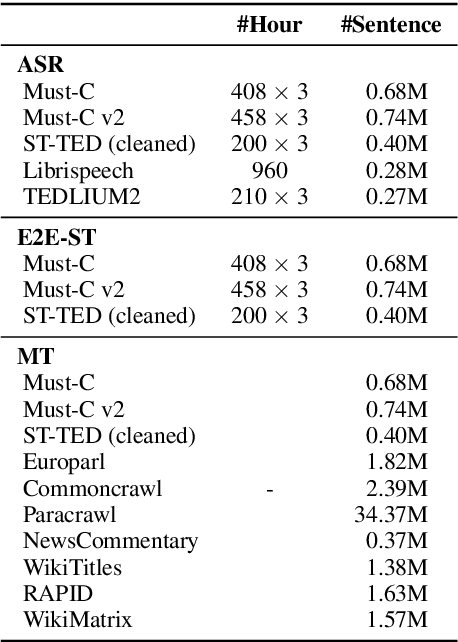
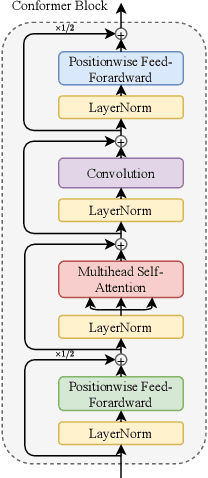
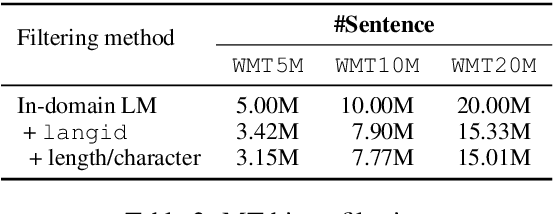
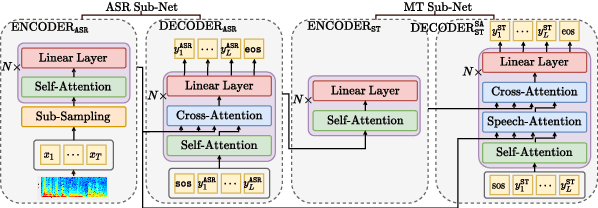
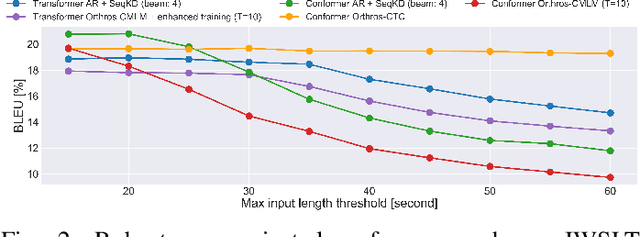
This paper describes the ESPnet-ST group's IWSLT 2021 submission in the offline speech translation track. This year we made various efforts on training data, architecture, and audio segmentation. On the data side, we investigated sequence-level knowledge distillation (SeqKD) for end-to-end (E2E) speech translation. Specifically, we used multi-referenced SeqKD from multiple teachers trained on different amounts of bitext. On the architecture side, we adopted the Conformer encoder and the Multi-Decoder architecture, which equips dedicated decoders for speech recognition and translation tasks in a unified encoder-decoder model and enables search in both source and target language spaces during inference. We also significantly improved audio segmentation by using the pyannote.audio toolkit and merging multiple short segments for long context modeling. Experimental evaluations showed that each of them contributed to large improvements in translation performance. Our best E2E system combined all the above techniques with model ensembling and achieved 31.4 BLEU on the 2-ref of tst2021 and 21.2 BLEU and 19.3 BLEU on the two single references of tst2021.
Self-Guided Curriculum Learning for Neural Machine Translation
May 15, 2021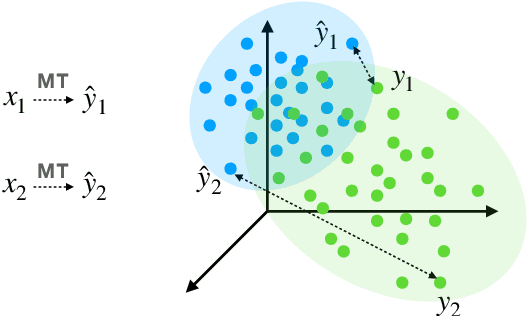

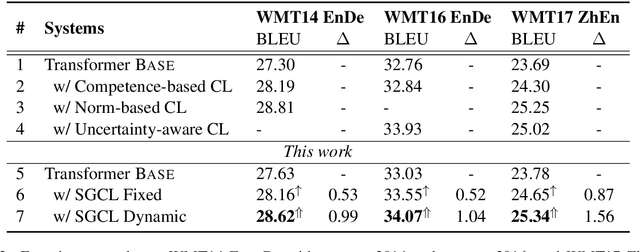
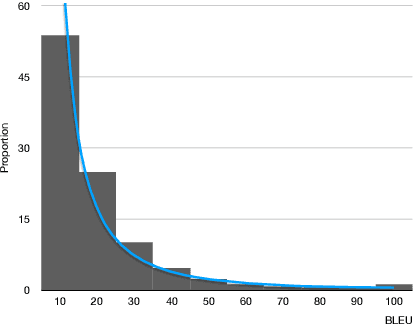
In the field of machine learning, the well-trained model is assumed to be able to recover the training labels, i.e. the synthetic labels predicted by the model should be as close to the ground-truth labels as possible. Inspired by this, we propose a self-guided curriculum strategy to encourage the learning of neural machine translation (NMT) models to follow the above recovery criterion, where we cast the recovery degree of each training example as its learning difficulty. Specifically, we adopt the sentence level BLEU score as the proxy of recovery degree. Different from existing curricula relying on linguistic prior knowledge or third-party language models, our chosen learning difficulty is more suitable to measure the degree of knowledge mastery of the NMT models. Experiments on translation benchmarks, including WMT14 English$\Rightarrow$German and WMT17 Chinese$\Rightarrow$English, demonstrate that our approach can consistently improve translation performance against strong baseline Transformer.