 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the MAGMaR 2026 Shared Task
Jun 10, 2026This overview paper presents the results of the shared task for the second workshop on Multimodal Augmented Generation via Multimodal Retrieval (MAGMaR). In this shared task participants submitted systems focused on either (i) video retrieval or (ii) grounded generation of articles given retrieved videos. Teams could submit to either task. For the retrieval task, we had 2 participating teams that submitted a total of 17 systems -- all of which beat a baseline derived from the winner of last year's shared task. On the generation side, we had 4 teams submit 16 systems. All teams had at least one generated report that was labeled the best by a human annotator.
Adding Multimodal Capabilities to a Text-only Translation Model
Mar 05, 2024



While most current work in multimodal machine translation (MMT) uses the Multi30k dataset for training and evaluation, we find that the resulting models overfit to the Multi30k dataset to an extreme degree. Consequently, these models perform very badly when evaluated against typical text-only testing sets such as the WMT newstest datasets. In order to perform well on both Multi30k and typical text-only datasets, we use a performant text-only machine translation (MT) model as the starting point of our MMT model. We add vision-text adapter layers connected via gating mechanisms to the MT model, and incrementally transform the MT model into an MMT model by 1) pre-training using vision-based masking of the source text and 2) fine-tuning on Multi30k.
Detecting Concrete Visual Tokens for Multimodal Machine Translation
Mar 05, 2024



The challenge of visual grounding and masking in multimodal machine translation (MMT) systems has encouraged varying approaches to the detection and selection of visually-grounded text tokens for masking. We introduce new methods for detection of visually and contextually relevant (concrete) tokens from source sentences, including detection with natural language processing (NLP), detection with object detection, and a joint detection-verification technique. We also introduce new methods for selection of detected tokens, including shortest $n$ tokens, longest $n$ tokens, and all detected concrete tokens. We utilize the GRAM MMT architecture to train models against synthetically collated multimodal datasets of source images with masked sentences, showing performance improvements and improved usage of visual context during translation tasks over the baseline model.
The Case for Evaluating Multimodal Translation Models on Text Datasets
Mar 05, 2024

A good evaluation framework should evaluate multimodal machine translation (MMT) models by measuring 1) their use of visual information to aid in the translation task and 2) their ability to translate complex sentences such as done for text-only machine translation. However, most current work in MMT is evaluated against the Multi30k testing sets, which do not measure these properties. Namely, the use of visual information by the MMT model cannot be shown directly from the Multi30k test set results and the sentences in Multi30k are are image captions, i.e., short, descriptive sentences, as opposed to complex sentences that typical text-only machine translation models are evaluated against. Therefore, we propose that MMT models be evaluated using 1) the CoMMuTE evaluation framework, which measures the use of visual information by MMT models, 2) the text-only WMT news translation task test sets, which evaluates translation performance against complex sentences, and 3) the Multi30k test sets, for measuring MMT model performance against a real MMT dataset. Finally, we evaluate recent MMT models trained solely against the Multi30k dataset against our proposed evaluation framework and demonstrate the dramatic drop performance against text-only testing sets compared to recent text-only MT models.
A Survey of Vision-Language Pre-training from the Lens of Multimodal Machine Translation
Jun 12, 2023



Large language models such as BERT and the GPT series started a paradigm shift that calls for building general-purpose models via pre-training on large datasets, followed by fine-tuning on task-specific datasets. There is now a plethora of large pre-trained models for Natural Language Processing and Computer Vision. Recently, we have seen rapid developments in the joint Vision-Language space as well, where pre-trained models such as CLIP (Radford et al., 2021) have demonstrated improvements in downstream tasks like image captioning and visual question answering. However, surprisingly there is comparatively little work on exploring these models for the task of multimodal machine translation, where the goal is to leverage image/video modality in text-to-text translation. To fill this gap, this paper surveys the landscape of language-and-vision pre-training from the lens of multimodal machine translation. We summarize the common architectures, pre-training objectives, and datasets from literature and conjecture what further is needed to make progress on multimodal machine translation.
Learning When to Say "I Don't Know"
Sep 11, 2022
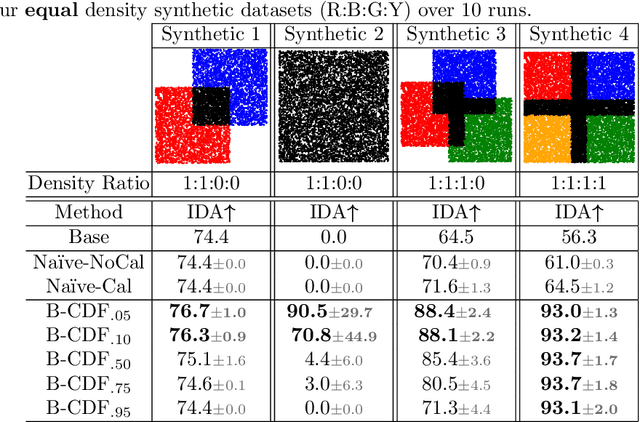
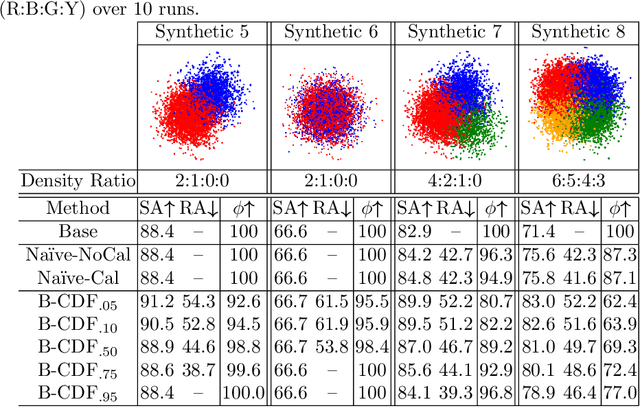
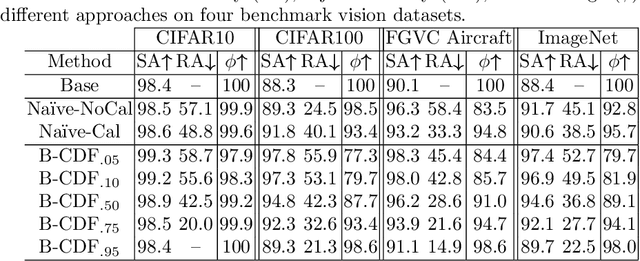
We propose a new Reject Option Classification technique to identify and remove regions of uncertainty in the decision space for a given neural classifier and dataset. Such existing formulations employ a learned rejection (remove)/selection (keep) function and require either a known cost for rejecting examples or strong constraints on the accuracy or coverage of the selected examples. We consider an alternative formulation by instead analyzing the complementary reject region and employing a validation set to learn per-class softmax thresholds. The goal is to maximize the accuracy of the selected examples subject to a natural randomness allowance on the rejected examples (rejecting more incorrect than correct predictions). We provide results showing the benefits of the proposed method over na\"ively thresholding calibrated/uncalibrated softmax scores with 2-D points, imagery, and text classification datasets using state-of-the-art pretrained models. Source code is available at https://github.com/osu-cvl/learning-idk.
An Empirical Exploration of Curriculum Learning for Neural Machine Translation
Nov 02, 2018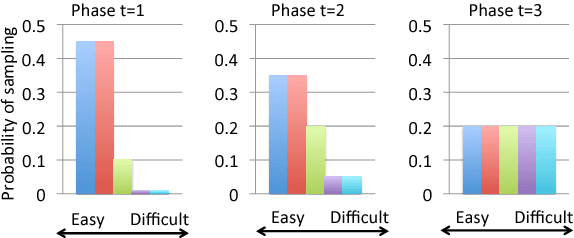
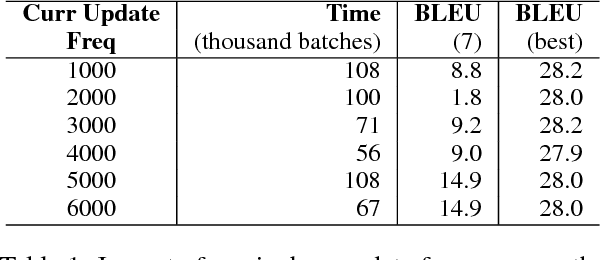

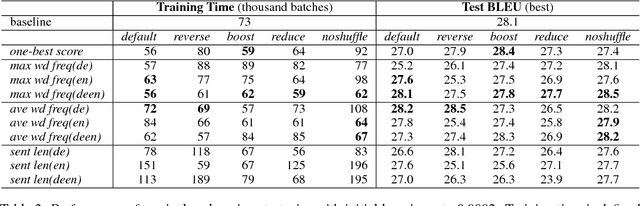
Machine translation systems based on deep neural networks are expensive to train. Curriculum learning aims to address this issue by choosing the order in which samples are presented during training to help train better models faster. We adopt a probabilistic view of curriculum learning, which lets us flexibly evaluate the impact of curricula design, and perform an extensive exploration on a German-English translation task. Results show that it is possible to improve convergence time at no loss in translation quality. However, results are highly sensitive to the choice of sample difficulty criteria, curriculum schedule and other hyperparameters.
Freezing Subnetworks to Analyze Domain Adaptation in Neural Machine Translation
Sep 14, 2018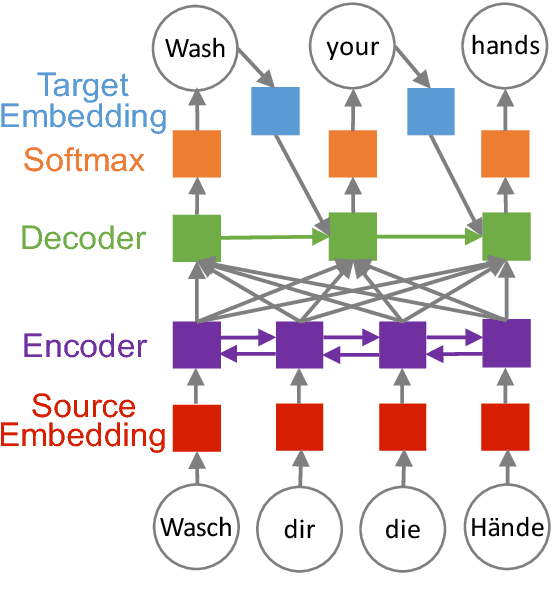
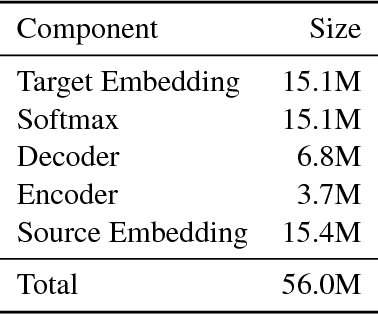
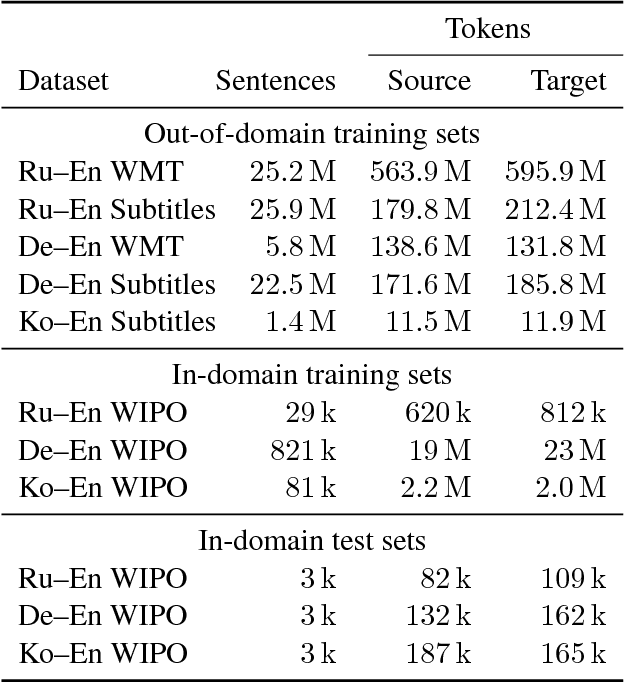

To better understand the effectiveness of continued training, we analyze the major components of a neural machine translation system (the encoder, decoder, and each embedding space) and consider each component's contribution to, and capacity for, domain adaptation. We find that freezing any single component during continued training has minimal impact on performance, and that performance is surprisingly good when a single component is adapted while holding the rest of the model fixed. We also find that continued training does not move the model very far from the out-of-domain model, compared to a sensitivity analysis metric, suggesting that the out-of-domain model can provide a good generic initialization for the new domain.