 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Model Rollouts for Pessimistic Offline Policy Optimization
Jan 11, 2024



Model-based offline reinforcement learning (RL) has made remarkable progress, offering a promising avenue for improving generalization with synthetic model rollouts. Existing works primarily focus on incorporating pessimism for policy optimization, usually via constructing a Pessimistic Markov Decision Process (P-MDP). However, the P-MDP discourages the policies from learning in out-of-distribution (OOD) regions beyond the support of offline datasets, which can under-utilize the generalization ability of dynamics models. In contrast, we propose constructing an Optimistic MDP (O-MDP). We initially observed the potential benefits of optimism brought by encouraging more OOD rollouts. Motivated by this observation, we present ORPO, a simple yet effective model-based offline RL framework. ORPO generates Optimistic model Rollouts for Pessimistic offline policy Optimization. Specifically, we train an optimistic rollout policy in the O-MDP to sample more OOD model rollouts. Then we relabel the sampled state-action pairs with penalized rewards and optimize the output policy in the P-MDP. Theoretically, we demonstrate that the performance of policies trained with ORPO can be lower-bounded in linear MDPs. Experimental results show that our framework significantly outperforms P-MDP baselines by a margin of 30%, achieving state-of-the-art performance on the widely-used benchmark. Moreover, ORPO exhibits notable advantages in problems that require generalization.
Uncertainty-Penalized Reinforcement Learning from Human Feedback with Diverse Reward LoRA Ensembles
Dec 30, 2023Reinforcement learning from human feedback (RLHF) emerges as a promising paradigm for aligning large language models (LLMs). However, a notable challenge in RLHF is overoptimization, where beyond a certain threshold, the pursuit of higher rewards leads to a decline in human preferences. In this paper, we observe the weakness of KL regularization which is commonly employed in existing RLHF methods to address overoptimization. To mitigate this limitation, we scrutinize the RLHF objective in the offline dataset and propose uncertainty-penalized RLHF (UP-RLHF), which incorporates uncertainty regularization during RL-finetuning. To enhance the uncertainty quantification abilities for reward models, we first propose a diverse low-rank adaptation (LoRA) ensemble by maximizing the nuclear norm of LoRA matrix concatenations. Then we optimize policy models utilizing penalized rewards, determined by both rewards and uncertainties provided by the diverse reward LoRA ensembles. Our experimental results, based on two real human preference datasets, showcase the effectiveness of diverse reward LoRA ensembles in quantifying reward uncertainty. Additionally, uncertainty regularization in UP-RLHF proves to be pivotal in mitigating overoptimization, thereby contributing to the overall performance.
Cheap-fake Detection with LLM using Prompt Engineering
Jun 05, 2023The misuse of real photographs with conflicting image captions in news items is an example of the out-of-context (OOC) misuse of media. In order to detect OOC media, individuals must determine the accuracy of the statement and evaluate whether the triplet (~\textit{i.e.}, the image and two captions) relates to the same event. This paper presents a novel learnable approach for detecting OOC media in ICME'23 Grand Challenge on Detecting Cheapfakes. The proposed method is based on the COSMOS structure, which assesses the coherence between an image and captions, as well as between two captions. We enhance the baseline algorithm by incorporating a Large Language Model (LLM), GPT3.5, as a feature extractor. Specifically, we propose an innovative approach to feature extraction utilizing prompt engineering to develop a robust and reliable feature extractor with GPT3.5 model. The proposed method captures the correlation between two captions and effectively integrates this module into the COSMOS baseline model, which allows for a deeper understanding of the relationship between captions. By incorporating this module, we demonstrate the potential for significant improvements in cheap-fakes detection performance. The proposed methodology holds promising implications for various applications such as natural language processing, image captioning, and text-to-image synthesis. Docker for submission is available at https://hub.docker.com/repository/docker/mulns/ acmmmcheapfakes.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Self-Supervised Exploration via Temporal Inconsistency in Reinforcement Learning
Aug 24, 2022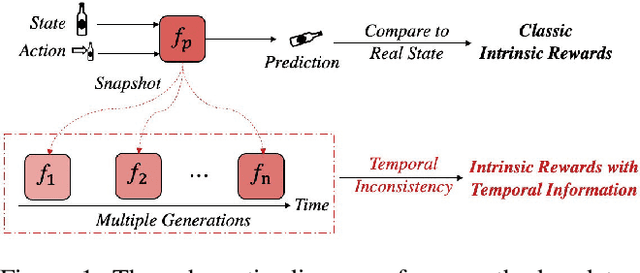
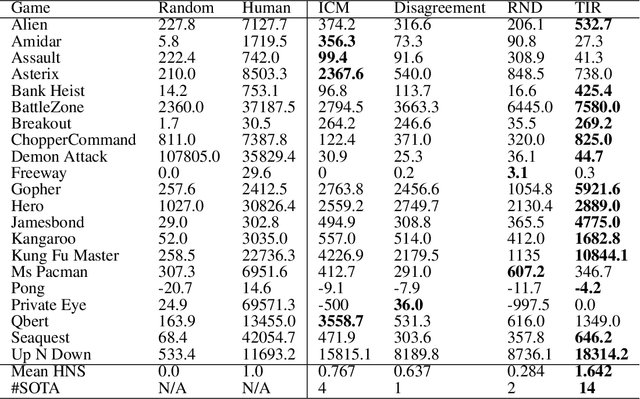
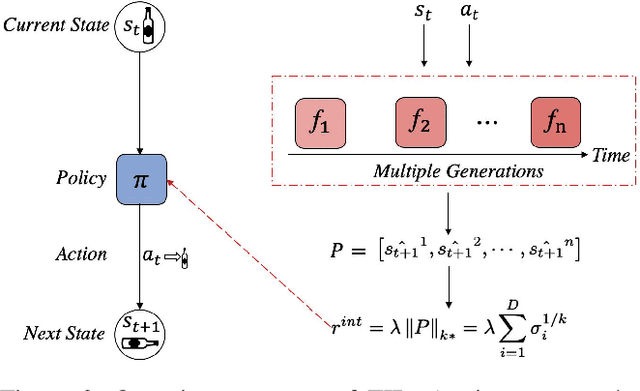
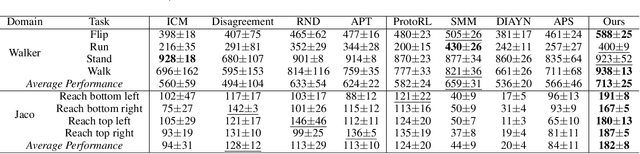
In real-world scenarios, reinforcement learning under sparse-reward synergistic settings has remained challenging, despite surging interests in this field. Previous attempts suggest that intrinsic reward can alleviate the issue caused by sparsity. In this paper, we present a novel intrinsic reward that is inspired by human learning, as humans evaluate curiosity by comparing current observations with historical knowledge. Specifically, we train a self-supervised prediction model and save a set of snapshots of the model parameters, without incurring addition training cost. Then we employ nuclear norm to evaluate the temporal inconsistency between the predictions of different snapshots, which can be further deployed as the intrinsic reward. Moreover, a variational weighting mechanism is proposed to assign weight to different snapshots in an adaptive manner. We demonstrate the efficacy of the proposed method in various benchmark environments. The results suggest that our method can provide overwhelming state-of-the-art performance compared with other intrinsic reward-based methods, without incurring additional training costs and maintaining higher noise tolerance. Our code will be released publicly to enhance reproducibility.
Dynamic Memory-based Curiosity: A Bootstrap Approach for Exploration
Aug 24, 2022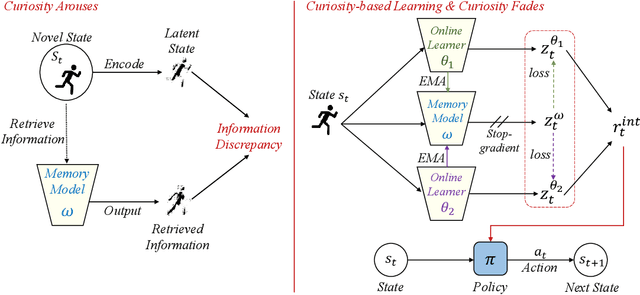
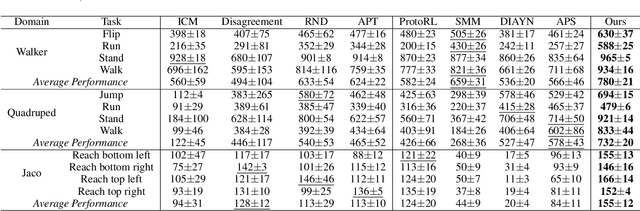
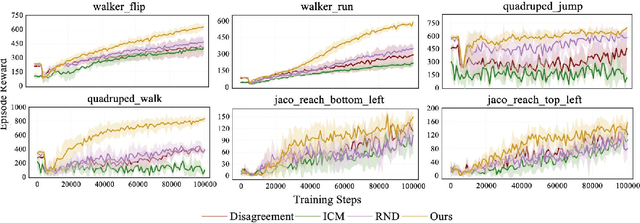
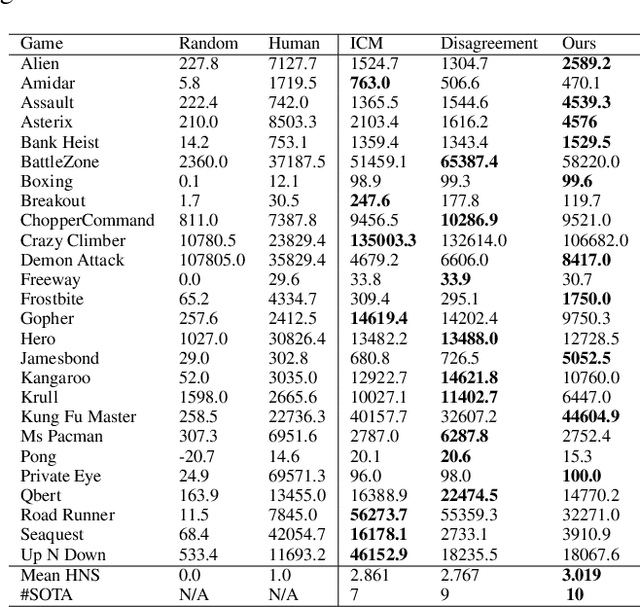
The sparsity of extrinsic rewards poses a serious challenge for reinforcement learning (RL). Currently, many efforts have been made on curiosity which can provide a representative intrinsic reward for effective exploration. However, the challenge is still far from being solved. In this paper, we present a novel curiosity for RL, named DyMeCu, which stands for Dynamic Memory-based Curiosity. Inspired by human curiosity and information theory, DyMeCu consists of a dynamic memory and dual online learners. The curiosity arouses if memorized information can not deal with the current state, and the information gap between dual learners can be formulated as the intrinsic reward for agents, and then such state information can be consolidated into the dynamic memory. Compared with previous curiosity methods, DyMeCu can better mimic human curiosity with dynamic memory, and the memory module can be dynamically grown based on a bootstrap paradigm with dual learners. On multiple benchmarks including DeepMind Control Suite and Atari Suite, large-scale empirical experiments are conducted and the results demonstrate that DyMeCu outperforms competitive curiosity-based methods with or without extrinsic rewards. We will release the code to enhance reproducibility.
Wound Segmentation with Dynamic Illumination Correction and Dual-view Semantic Fusion
Jul 12, 2022
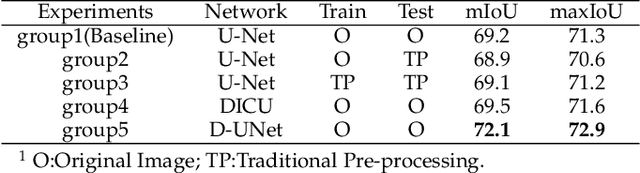
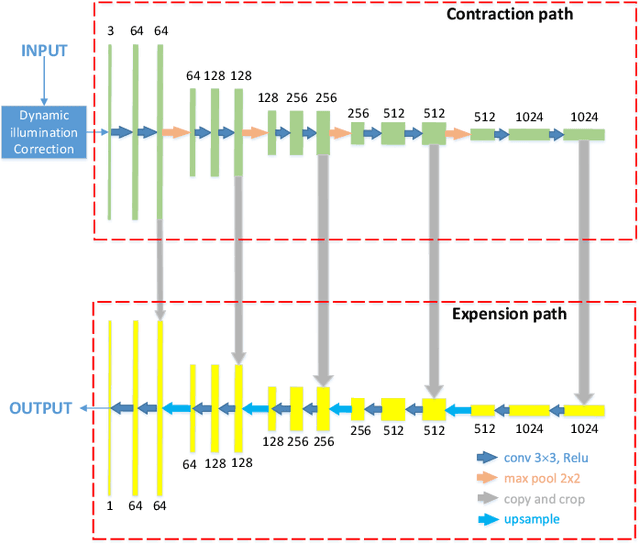

Wound image segmentation is a critical component for the clinical diagnosis and in-time treatment of wounds. Recently, deep learning has become the mainstream methodology for wound image segmentation. However, the pre-processing of the wound image, such as the illumination correction, is required before the training phase as the performance can be greatly improved. The correction procedure and the training of deep models are independent of each other, which leads to sub-optimal segmentation performance as the fixed illumination correction may not be suitable for all images. To address aforementioned issues, an end-to-end dual-view segmentation approach was proposed in this paper, by incorporating a learn-able illumination correction module into the deep segmentation models. The parameters of the module can be learned and updated during the training stage automatically, while the dual-view fusion can fully employ the features from both the raw images and the enhanced ones. To demonstrate the effectiveness and robustness of the proposed framework, the extensive experiments are conducted on the benchmark datasets. The encouraging results suggest that our framework can significantly improve the segmentation performance, compared to the state-of-the-art methods.
Trusted Multi-Scale Classification Framework for Whole Slide Image
Jul 12, 2022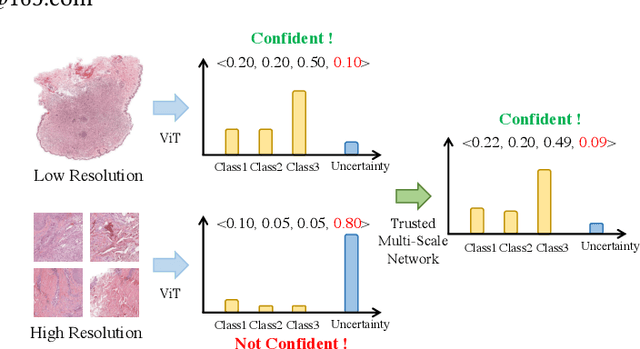


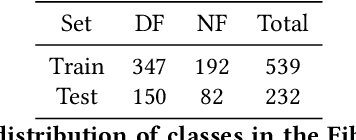
Despite remarkable efforts been made, the classification of gigapixels whole-slide image (WSI) is severely restrained from either the constrained computing resources for the whole slides, or limited utilizing of the knowledge from different scales. Moreover, most of the previous attempts lacked of the ability of uncertainty estimation. Generally, the pathologists often jointly analyze WSI from the different magnifications. If the pathologists are uncertain by using single magnification, then they will change the magnification repeatedly to discover various features of the tissues. Motivated by the diagnose process of the pathologists, in this paper, we propose a trusted multi-scale classification framework for the WSI. Leveraging the Vision Transformer as the backbone for multi branches, our framework can jointly classification modeling, estimating the uncertainty of each magnification of a microscope and integrate the evidence from different magnification. Moreover, to exploit discriminative patches from WSIs and reduce the requirement for computation resources, we propose a novel patch selection schema using attention rollout and non-maximum suppression. To empirically investigate the effectiveness of our approach, empirical experiments are conducted on our WSI classification tasks, using two benchmark databases. The obtained results suggest that the trusted framework can significantly improve the WSI classification performance compared with the state-of-the-art methods.
Nuclear Norm Maximization Based Curiosity-Driven Learning
May 28, 2022
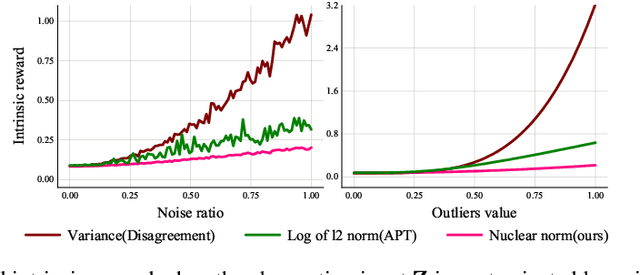
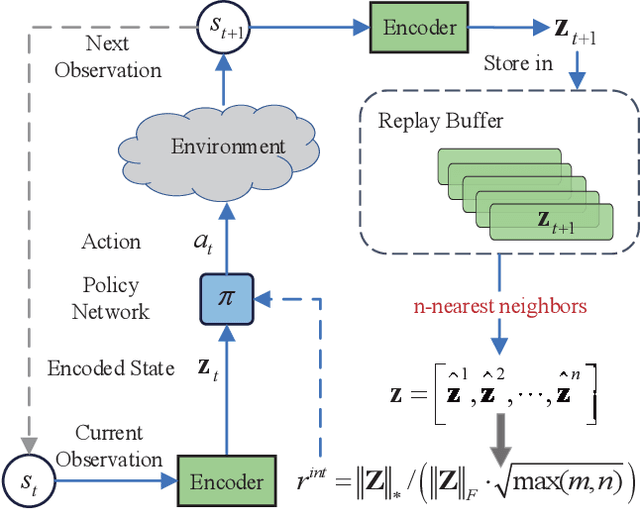
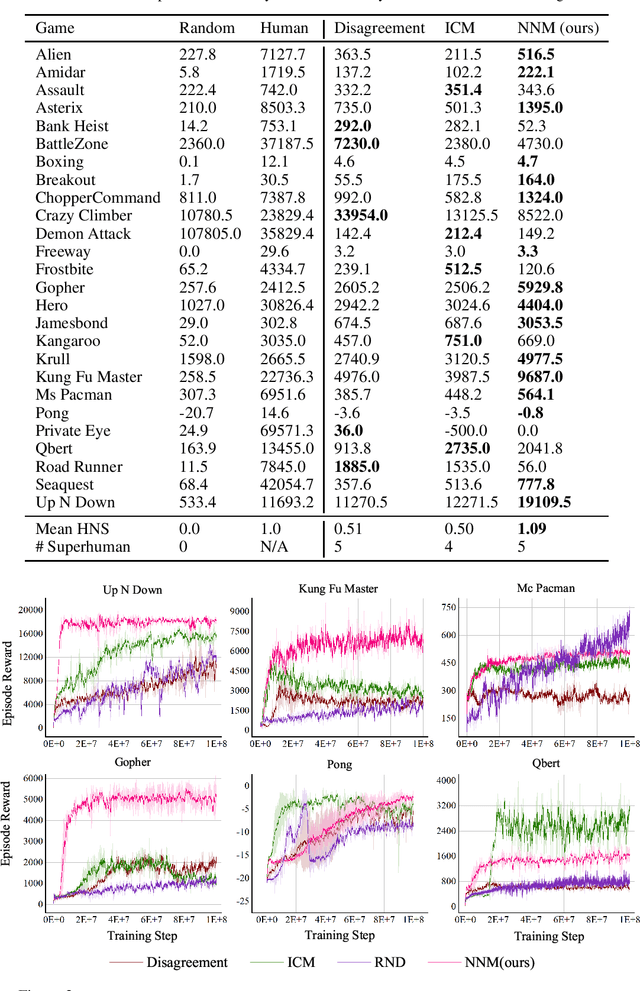
To handle the sparsity of the extrinsic rewards in reinforcement learning, researchers have proposed intrinsic reward which enables the agent to learn the skills that might come in handy for pursuing the rewards in the future, such as encouraging the agent to visit novel states. However, the intrinsic reward can be noisy due to the undesirable environment's stochasticity and directly applying the noisy value predictions to supervise the policy is detrimental to improve the learning performance and efficiency. Moreover, many previous studies employ $\ell^2$ norm or variance to measure the exploration novelty, which will amplify the noise due to the square operation. In this paper, we address aforementioned challenges by proposing a novel curiosity leveraging the nuclear norm maximization (NNM), which can quantify the novelty of exploring the environment more accurately while providing high-tolerance to the noise and outliers. We conduct extensive experiments across a variety of benchmark environments and the results suggest that NNM can provide state-of-the-art performance compared with previous curiosity methods. On 26 Atari games subset, when trained with only intrinsic reward, NNM achieves a human-normalized score of 1.09, which doubles that of competitive intrinsic rewards-based approaches. Our code will be released publicly to enhance the reproducibility.