 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing and Controlling AI Agent Actions in Spreadsheets
Apr 22, 2026Advances in AI agent capabilities have outpaced users' ability to meaningfully oversee their execution. AI agents can perform sophisticated, multi-step knowledge work autonomously from start to finish, yet this process remains effectively inaccessible during execution, often buried within large volumes of intermediate reasoning and outputs: by the time users receive the output, all underlying decisions have already been made without their involvement. This lack of transparency leaves users unable to examine the agent's assumptions, identify errors before they propagate, or redirect execution when it deviates from their intent. The stakes are particularly high in spreadsheet environments, where process and artifact are inseparable. Each decision the agent makes is recorded directly in cells that belong to and reflect on the user. We introduce Pista, a spreadsheet AI agent that decomposes execution into auditable, controllable actions, providing users with visibility into the agent's decision-making process and the capacity to intervene at each step. A formative study (N = 8) and a within-subjects summative evaluation (N = 16) comparing Pista to a baseline agent demonstrated that active participation in execution influenced not only task outcomes but also users' comprehension of the task, their perception of the agent, and their sense of role within the workflow. Users identified their own intent reflected in the agent's actions, detected errors that post-hoc review would have failed to surface, and reported a sense of co-ownership over the resulting output. These findings indicate that meaningful human oversight of AI agents in knowledge work requires not improved post-hoc review mechanisms, but active participation in decisions as they are made.
Exploring the Challenges and Opportunities of AI-assisted Codebase Generation
Aug 11, 2025



Recent AI code assistants have significantly improved their ability to process more complex contexts and generate entire codebases based on a textual description, compared to the popular snippet-level generation. These codebase AI assistants (CBAs) can also extend or adapt codebases, allowing users to focus on higher-level design and deployment decisions. While prior work has extensively studied the impact of snippet-level code generation, this new class of codebase generation models is relatively unexplored. Despite initial anecdotal reports of excitement about these agents, they remain less frequently adopted compared to snippet-level code assistants. To utilize CBAs better, we need to understand how developers interact with CBAs, and how and why CBAs fall short of developers' needs. In this paper, we explored these gaps through a counterbalanced user study and interview with (n = 16) students and developers working on coding tasks with CBAs. We found that participants varied the information in their prompts, like problem description (48% of prompts), required functionality (98% of prompts), code structure (48% of prompts), and their prompt writing process. Despite various strategies, the overall satisfaction score with generated codebases remained low (mean = 2.8, median = 3, on a scale of one to five). Participants mentioned functionality as the most common factor for dissatisfaction (77% of instances), alongside poor code quality (42% of instances) and communication issues (25% of instances). We delve deeper into participants' dissatisfaction to identify six underlying challenges that participants faced when using CBAs, and extracted five barriers to incorporating CBAs into their workflows. Finally, we surveyed 21 commercial CBAs to compare their capabilities with participant challenges and present design opportunities for more efficient and useful CBAs.
ELI-Why: Evaluating the Pedagogical Utility of Language Model Explanations
Jun 17, 2025



Language models today are widely used in education, yet their ability to tailor responses for learners with varied informational needs and knowledge backgrounds remains under-explored. To this end, we introduce ELI-Why, a benchmark of 13.4K "Why" questions to evaluate the pedagogical capabilities of language models. We then conduct two extensive human studies to assess the utility of language model-generated explanatory answers (explanations) on our benchmark, tailored to three distinct educational grades: elementary, high-school and graduate school. In our first study, human raters assume the role of an "educator" to assess model explanations' fit to different educational grades. We find that GPT-4-generated explanations match their intended educational background only 50% of the time, compared to 79% for lay human-curated explanations. In our second study, human raters assume the role of a learner to assess if an explanation fits their own informational needs. Across all educational backgrounds, users deemed GPT-4-generated explanations 20% less suited on average to their informational needs, when compared to explanations curated by lay people. Additionally, automated evaluation metrics reveal that explanations generated across different language model families for different informational needs remain indistinguishable in their grade-level, limiting their pedagogical effectiveness.
From Prompts to Propositions: A Logic-Based Lens on Student-LLM Interactions
Apr 25, 2025Background and Context. The increasing integration of large language models (LLMs) in computing education presents an emerging challenge in understanding how students use LLMs and craft prompts to solve computational tasks. Prior research has used both qualitative and quantitative methods to analyze prompting behavior, but these approaches lack scalability or fail to effectively capture the semantic evolution of prompts. Objective. In this paper, we investigate whether students prompts can be systematically analyzed using propositional logic constraints. We examine whether this approach can identify patterns in prompt evolution, detect struggling students, and provide insights into effective and ineffective strategies. Method. We introduce Prompt2Constraints, a novel method that translates students prompts into logical constraints. The constraints are able to represent the intent of the prompts in succinct and quantifiable ways. We used this approach to analyze a dataset of 1,872 prompts from 203 students solving introductory programming tasks. Findings. We find that while successful and unsuccessful attempts tend to use a similar number of constraints overall, when students fail, they often modify their prompts more significantly, shifting problem-solving strategies midway. We also identify points where specific interventions could be most helpful to students for refining their prompts. Implications. This work offers a new and scalable way to detect students who struggle in solving natural language programming tasks. This work could be extended to investigate more complex tasks and integrated into programming tools to provide real-time support.
Generating Contextually-Relevant Navigation Instructions for Blind and Low Vision People
Jul 11, 2024Navigating unfamiliar environments presents significant challenges for blind and low-vision (BLV) individuals. In this work, we construct a dataset of images and goals across different scenarios such as searching through kitchens or navigating outdoors. We then investigate how grounded instruction generation methods can provide contextually-relevant navigational guidance to users in these instances. Through a sighted user study, we demonstrate that large pretrained language models can produce correct and useful instructions perceived as beneficial for BLV users. We also conduct a survey and interview with 4 BLV users and observe useful insights on preferences for different instructions based on the scenario.
Explaining Reinforcement Learning to Mere Mortals: An Empirical Study
Mar 22, 2019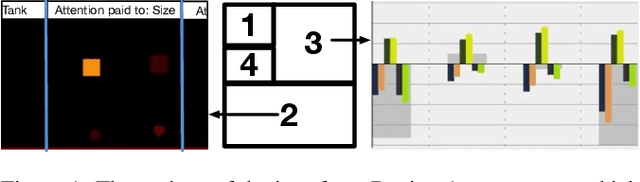
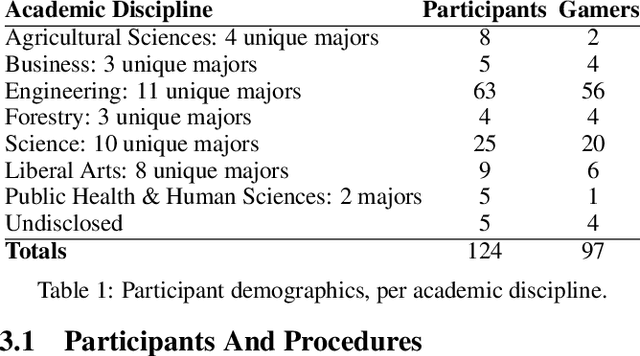
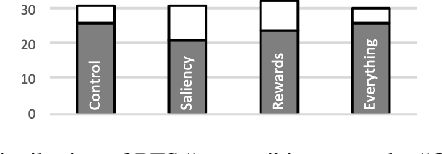
We present a user study to investigate the impact of explanations on non-experts' understanding of reinforcement learning (RL) agents. We investigate both a common RL visualization, saliency maps (the focus of attention), and a more recent explanation type, reward-decomposition bars (predictions of future types of rewards). We designed a 124 participant, four-treatment experiment to compare participants' mental models of an RL agent in a simple Real-Time Strategy (RTS) game. Our results show that the combination of both saliency and reward bars were needed to achieve a statistically significant improvement in mental model score over the control. In addition, our qualitative analysis of the data reveals a number of effects for further study.