 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld of Workflows: a Benchmark for Bringing World Models to Enterprise Systems
Jan 29, 2026Frontier large language models (LLMs) excel as autonomous agents in many domains, yet they remain untested in complex enterprise systems where hidden workflows create cascading effects across interconnected databases. Existing enterprise benchmarks evaluate surface-level agentic task completion similar to general consumer benchmarks, ignoring true challenges in enterprises, such as limited observability, large database state, and hidden workflows with cascading side effects. We introduce World of Workflows (WoW), a realistic ServiceNow-based environment incorporating 4,000+ business rules and 55 active workflows embedded in the system, alongside WoW-bench, a benchmark of 234 tasks evaluating constrained agentic task completion and enterprise dynamics modeling capabilities. We reveal two major takeaways: (1) Frontier LLMs suffer from dynamics blindness, consistently failing to predict the invisible, cascading side effects of their actions, which leads to silent constraint violations, and (2) reliability in opaque systems requires grounded world modeling, where agents must mentally simulate hidden state transitions to bridge the observability gap when high-fidelity feedback is unavailable. For reliable and useful enterprise agents, WoW motivates a new paradigm to explicitly learn system dynamics. We release our GitHub for setting up and evaluating WoW.
CASSANDRA: Programmatic and Probabilistic Learning and Inference for Stochastic World Modeling
Jan 26, 2026Building world models is essential for planning in real-world domains such as businesses. Since such domains have rich semantics, we can leverage world knowledge to effectively model complex action effects and causal relationships from limited data. In this work, we propose CASSANDRA, a neurosymbolic world modeling approach that leverages an LLM as a knowledge prior to construct lightweight transition models for planning. CASSANDRA integrates two components: (1) LLM-synthesized code to model deterministic features, and (2) LLM-guided structure learning of a probabilistic graphical model to capture causal relationships among stochastic variables. We evaluate CASSANDRA in (i) a small-scale coffee-shop simulator and (ii) a complex theme park business simulator, where we demonstrate significant improvements in transition prediction and planning over baselines.
SCOPE: Language Models as One-Time Teacher for Hierarchical Planning in Text Environments
Dec 10, 2025Long-term planning in complex, text-based environments presents significant challenges due to open-ended action spaces, ambiguous observations, and sparse feedback. Recent research suggests that large language models (LLMs) encode rich semantic knowledge about the world, which can be valuable for guiding agents in high-level reasoning and planning across both embodied and purely textual settings. However, existing approaches often depend heavily on querying LLMs during training and inference, making them computationally expensive and difficult to deploy efficiently. In addition, these methods typically employ a pretrained, unaltered LLM whose parameters remain fixed throughout training, providing no opportunity for adaptation to the target task. To address these limitations, we introduce SCOPE (Subgoal-COnditioned Pretraining for Efficient planning), a one-shot hierarchical planner that leverages LLM-generated subgoals only at initialization to pretrain a lightweight student model. Unlike prior approaches that distill LLM knowledge by repeatedly prompting the model to adaptively generate subgoals during training, our method derives subgoals directly from example trajectories. This design removes the need for repeated LLM queries, significantly improving efficiency, though at the cost of reduced explainability and potentially suboptimal subgoals. Despite their suboptimality, our results on the TextCraft environment show that LLM-generated subgoals can still serve as a strong starting point for hierarchical goal decomposition in text-based planning tasks. Compared to the LLM-based hierarchical agent ADaPT (Prasad et al., 2024), which achieves a 0.52 success rate, our method reaches 0.56 and reduces inference time from 164.4 seconds to just 3.0 seconds.
Investigating Failures to Generalize for Coreference Resolution Models
Mar 16, 2023



Coreference resolution models are often evaluated on multiple datasets. Datasets vary, however, in how coreference is realized -- i.e., how the theoretical concept of coreference is operationalized in the dataset -- due to factors such as the choice of corpora and annotation guidelines. We investigate the extent to which errors of current coreference resolution models are associated with existing differences in operationalization across datasets (OntoNotes, PreCo, and Winogrande). Specifically, we distinguish between and break down model performance into categories corresponding to several types of coreference, including coreferring generic mentions, compound modifiers, and copula predicates, among others. This break down helps us investigate how state-of-the-art models might vary in their ability to generalize across different coreference types. In our experiments, for example, models trained on OntoNotes perform poorly on generic mentions and copula predicates in PreCo. Our findings help calibrate expectations of current coreference resolution models; and, future work can explicitly account for those types of coreference that are empirically associated with poor generalization when developing models.
The KITMUS Test: Evaluating Knowledge Integration from Multiple Sources in Natural Language Understanding Systems
Dec 15, 2022Many state-of-the-art natural language understanding (NLU) models are based on pretrained neural language models. These models often make inferences using information from multiple sources. An important class of such inferences are those that require both background knowledge, presumably contained in a model's pretrained parameters, and instance-specific information that is supplied at inference time. However, the integration and reasoning abilities of NLU models in the presence of multiple knowledge sources have been largely understudied. In this work, we propose a test suite of coreference resolution tasks that require reasoning over multiple facts. Our dataset is organized into subtasks that differ in terms of which knowledge sources contain relevant facts. We evaluate state-of-the-art coreference resolution models on our dataset. Our results indicate that several models struggle to reason on-the-fly over knowledge observed both at pretrain time and at inference time. However, with task-specific training, a subset of models demonstrates the ability to integrate certain knowledge types from multiple sources.
Deconstructing NLG Evaluation: Evaluation Practices, Assumptions, and Their Implications
May 13, 2022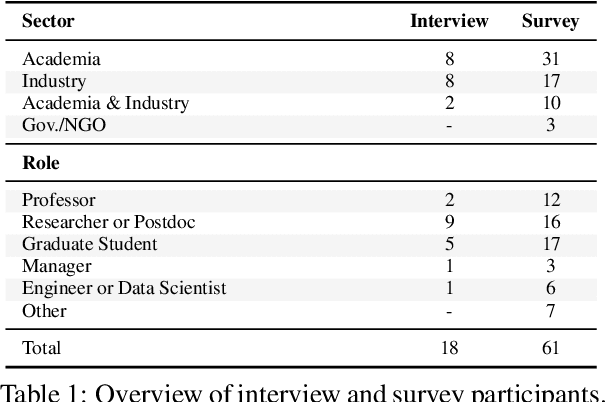
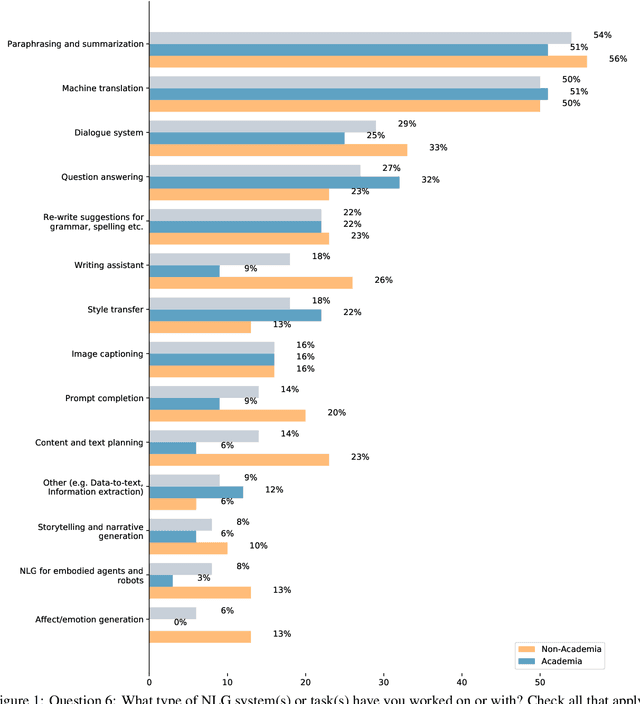
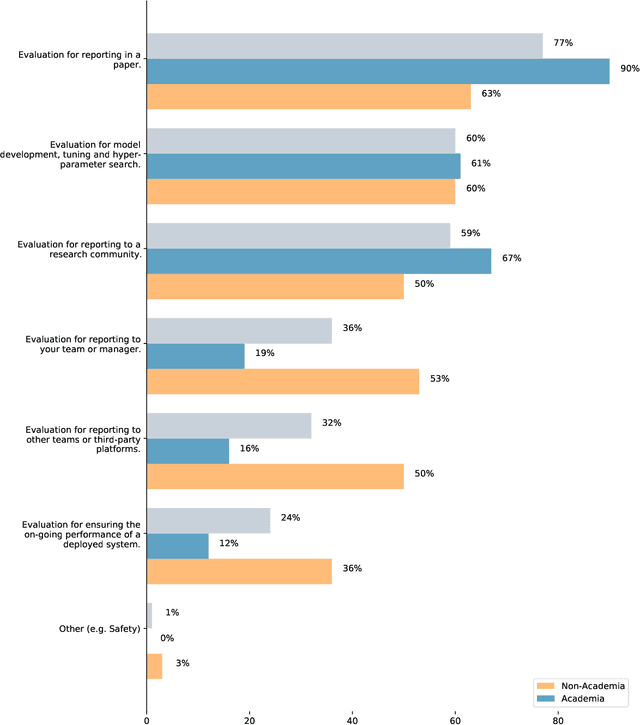
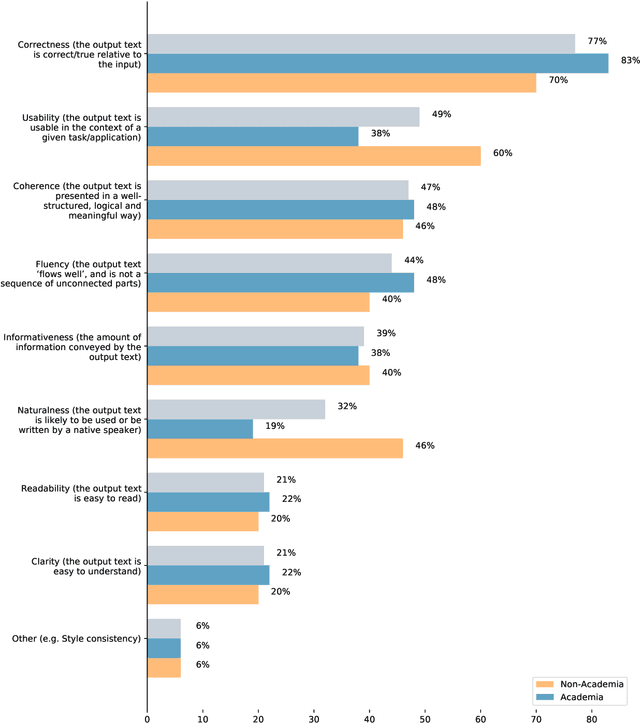
There are many ways to express similar things in text, which makes evaluating natural language generation (NLG) systems difficult. Compounding this difficulty is the need to assess varying quality criteria depending on the deployment setting. While the landscape of NLG evaluation has been well-mapped, practitioners' goals, assumptions, and constraints -- which inform decisions about what, when, and how to evaluate -- are often partially or implicitly stated, or not stated at all. Combining a formative semi-structured interview study of NLG practitioners (N=18) with a survey study of a broader sample of practitioners (N=61), we surface goals, community practices, assumptions, and constraints that shape NLG evaluations, examining their implications and how they embody ethical considerations.
TopiOCQA: Open-domain Conversational Question Answeringwith Topic Switching
Oct 02, 2021

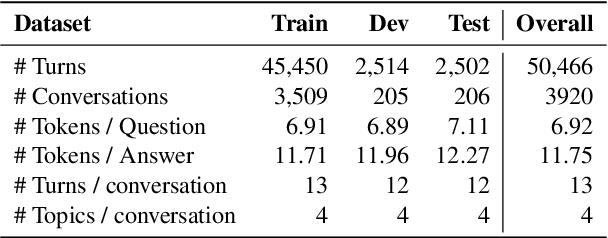
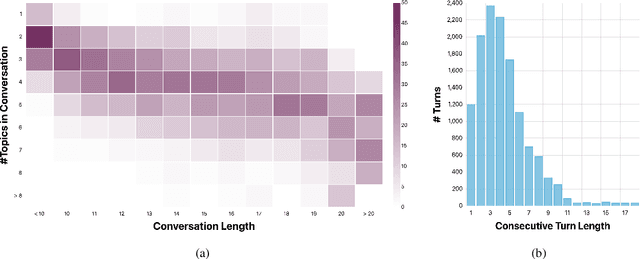
In a conversational question answering scenario, a questioner seeks to extract information about a topic through a series of interdependent questions and answers. As the conversation progresses, they may switch to related topics, a phenomenon commonly observed in information-seeking search sessions. However, current datasets for conversational question answering are limiting in two ways: 1) they do not contain topic switches; and 2) they assume the reference text for the conversation is given, i.e., the setting is not open-domain. We introduce TopiOCQA (pronounced Tapioca), an open-domain conversational dataset with topic switches on Wikipedia. TopiOCQA contains 3,920 conversations with information-seeking questions and free-form answers. TopiOCQA poses a challenging test-bed for models, where efficient retrieval is required on multiple turns of the same conversation, in conjunction with constructing valid responses using conversational history. We evaluate several baselines, by combining state-of-the-art document retrieval methods with neural reader models. Our best models achieves F1 of 51.9, and BLEU score of 42.1 which falls short of human performance by 18.3 points and 17.6 points respectively, indicating the difficulty of our dataset. Our dataset and code will be available at https://mcgill-nlp.github.io/topiocqa
Modeling Event Plausibility with Consistent Conceptual Abstraction
Apr 20, 2021

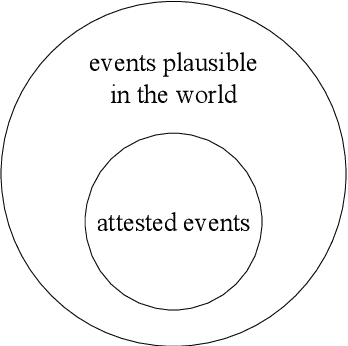

Understanding natural language requires common sense, one aspect of which is the ability to discern the plausibility of events. While distributional models -- most recently pre-trained, Transformer language models -- have demonstrated improvements in modeling event plausibility, their performance still falls short of humans'. In this work, we show that Transformer-based plausibility models are markedly inconsistent across the conceptual classes of a lexical hierarchy, inferring that "a person breathing" is plausible while "a dentist breathing" is not, for example. We find this inconsistency persists even when models are softly injected with lexical knowledge, and we present a simple post-hoc method of forcing model consistency that improves correlation with human plausibility judgements.
An Analysis of Dataset Overlap on Winograd-Style Tasks
Nov 09, 2020
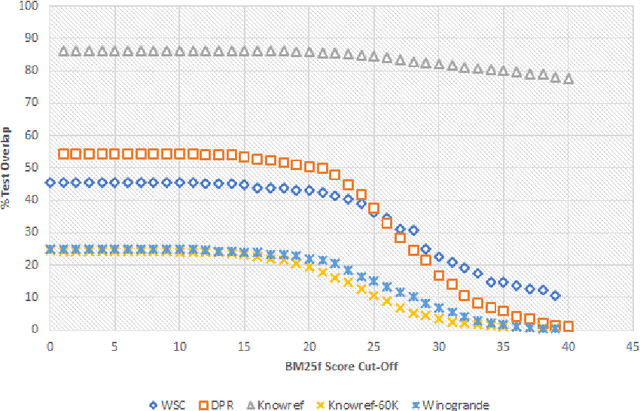
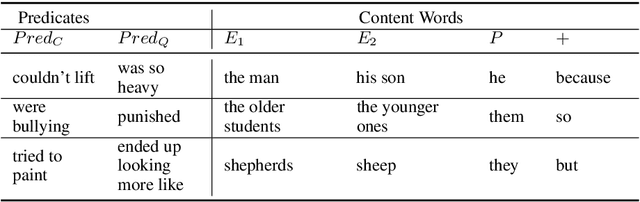
The Winograd Schema Challenge (WSC) and variants inspired by it have become important benchmarks for common-sense reasoning (CSR). Model performance on the WSC has quickly progressed from chance-level to near-human using neural language models trained on massive corpora. In this paper, we analyze the effects of varying degrees of overlap between these training corpora and the test instances in WSC-style tasks. We find that a large number of test instances overlap considerably with the corpora on which state-of-the-art models are (pre)trained, and that a significant drop in classification accuracy occurs when we evaluate models on instances with minimal overlap. Based on these results, we develop the KnowRef-60K dataset, which consists of over 60k pronoun disambiguation problems scraped from web data. KnowRef-60K is the largest corpus to date for WSC-style common-sense reasoning and exhibits a significantly lower proportion of overlaps with current pretraining corpora.
Can a Gorilla Ride a Camel? Learning Semantic Plausibility from Text
Nov 13, 2019


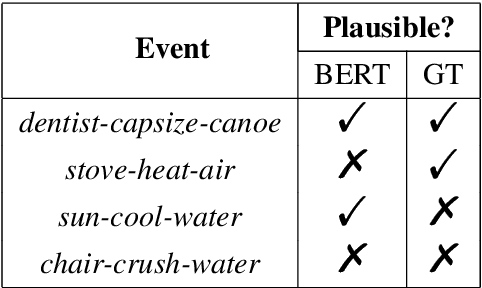
Modeling semantic plausibility requires commonsense knowledge about the world and has been used as a testbed for exploring various knowledge representations. Previous work has focused specifically on modeling physical plausibility and shown that distributional methods fail when tested in a supervised setting. At the same time, distributional models, namely large pretrained language models, have led to improved results for many natural language understanding tasks. In this work, we show that these pretrained language models are in fact effective at modeling physical plausibility in the supervised setting. We therefore present the more difficult problem of learning to model physical plausibility directly from text. We create a training set by extracting attested events from a large corpus, and we provide a baseline for training on these attested events in a self-supervised manner and testing on a physical plausibility task. We believe results could be further improved by injecting explicit commonsense knowledge into a distributional model.
* Accepted at COIN@EMNLP 2019