 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Logical Instruction Generation
Aug 12, 2025Instruction following has catalyzed the recent era of Large Language Models (LLMs) and is the foundational skill underpinning more advanced capabilities such as reasoning and agentic behaviors. As tasks grow more challenging, the logic structures embedded in natural language instructions becomes increasingly intricate. However, how well LLMs perform on such logic-rich instructions remains under-explored. We propose LogicIFGen and LogicIFEval. LogicIFGen is a scalable, automated framework for generating verifiable instructions from code functions, which can naturally express rich logic such as conditionals, nesting, recursion, and function calls. We further curate a collection of complex code functions and use LogicIFGen to construct LogicIFEval, a benchmark comprising 426 verifiable logic-rich instructions. Our experiments demonstrate that current state-of-the-art LLMs still struggle to correctly follow the instructions in LogicIFEval. Most LLMs can only follow fewer than 60% of the instructions, revealing significant deficiencies in the instruction-following ability. Code and Benchmark: https://github.com/mianzhang/LogicIF
Multi-module GRPO: Composing Policy Gradients and Prompt Optimization for Language Model Programs
Aug 06, 2025Group Relative Policy Optimization (GRPO) has proven to be an effective tool for post-training language models (LMs). However, AI systems are increasingly expressed as modular programs that mix together multiple LM calls with distinct prompt templates and other tools, and it is not clear how best to leverage GRPO to improve these systems. We begin to address this challenge by defining mmGRPO, a simple multi-module generalization of GRPO that groups LM calls by module across rollouts and handles variable-length and interrupted trajectories. We find that mmGRPO, composed with automatic prompt optimization, improves accuracy by 11% on average across classification, many-hop search, and privacy-preserving delegation tasks against the post-trained LM, and by 5% against prompt optimization on its own. We open-source mmGRPO in DSPy as the dspy.GRPO optimizer.
Instructional Segment Embedding: Improving LLM Safety with Instruction Hierarchy
Oct 09, 2024



Large Language Models (LLMs) are susceptible to security and safety threats, such as prompt injection, prompt extraction, and harmful requests. One major cause of these vulnerabilities is the lack of an instruction hierarchy. Modern LLM architectures treat all inputs equally, failing to distinguish between and prioritize various types of instructions, such as system messages, user prompts, and data. As a result, lower-priority user prompts may override more critical system instructions, including safety protocols. Existing approaches to achieving instruction hierarchy, such as delimiters and instruction-based training, do not address this issue at the architectural level. We introduce the Instructional Segment Embedding (ISE) technique, inspired by BERT, to modern large language models, which embeds instruction priority information directly into the model. This approach enables models to explicitly differentiate and prioritize various instruction types, significantly improving safety against malicious prompts that attempt to override priority rules. Our experiments on the Structured Query and Instruction Hierarchy benchmarks demonstrate an average robust accuracy increase of up to 15.75% and 18.68%, respectively. Furthermore, we observe an improvement in instruction-following capability of up to 4.1% evaluated on AlpacaEval. Overall, our approach offers a promising direction for enhancing the safety and effectiveness of LLM architectures.
Improving Multilingual Instruction Finetuning via Linguistically Natural and Diverse Datasets
Jul 01, 2024



Advancements in Large Language Models (LLMs) have significantly enhanced instruction-following capabilities. However, most Instruction Fine-Tuning (IFT) datasets are predominantly in English, limiting model performance in other languages. Traditional methods for creating multilingual IFT datasets such as translating existing English IFT datasets or converting existing NLP datasets into IFT datasets by templating, struggle to capture linguistic nuances and ensure prompt (instruction) diversity. To address this issue, we propose a novel method for collecting multilingual IFT datasets that preserves linguistic naturalness and ensures prompt diversity. This approach leverages English-focused LLMs, monolingual corpora, and a scoring function to create high-quality, diversified IFT datasets in multiple languages. Experiments demonstrate that LLMs finetuned using these IFT datasets show notable improvements in both generative and discriminative tasks, indicating enhanced language comprehension by LLMs in non-English contexts. Specifically, on the multilingual summarization task, LLMs using our IFT dataset achieved 17.57% and 15.23% improvements over LLMs fine-tuned with translation-based and template-based datasets, respectively.
WPO: Enhancing RLHF with Weighted Preference Optimization
Jun 17, 2024Reinforcement learning from human feedback (RLHF) is a promising solution to align large language models (LLMs) more closely with human values. Off-policy preference optimization, where the preference data is obtained from other models, is widely adopted due to its cost efficiency and scalability. However, off-policy preference optimization often suffers from a distributional gap between the policy used for data collection and the target policy, leading to suboptimal optimization. In this paper, we propose a novel strategy to mitigate this problem by simulating on-policy learning with off-policy preference data. Our Weighted Preference Optimization (WPO) method adapts off-policy data to resemble on-policy data more closely by reweighting preference pairs according to their probability under the current policy. This method not only addresses the distributional gap problem but also enhances the optimization process without incurring additional costs. We validate our method on instruction following benchmarks including Alpaca Eval 2 and MT-bench. WPO not only outperforms Direct Preference Optimization (DPO) by up to 5.6% on Alpaca Eval 2 but also establishes a remarkable length-controlled winning rate against GPT-4-turbo of 48.6% based on Llama-3-8B-Instruct, making it the strongest 8B model on the leaderboard. We will release the code and models at https://github.com/wzhouad/WPO.
When Reasoning Meets Information Aggregation: A Case Study with Sports Narratives
Jun 17, 2024



Reasoning is most powerful when an LLM accurately aggregates relevant information. We examine the critical role of information aggregation in reasoning by requiring the LLM to analyze sports narratives. To succeed at this task, an LLM must infer points from actions, identify related entities, attribute points accurately to players and teams, and compile key statistics to draw conclusions. We conduct comprehensive experiments with real NBA basketball data and present SportsGen, a new method to synthesize game narratives. By synthesizing data, we can rigorously evaluate LLMs' reasoning capabilities under complex scenarios with varying narrative lengths and density of information. Our findings show that most models, including GPT-4o, often fail to accurately aggregate basketball scores due to frequent scoring patterns. Open-source models like Llama-3 further suffer from significant score hallucinations. Finally, the effectiveness of reasoning is influenced by narrative complexity, information density, and domain-specific terms, highlighting the challenges in analytical reasoning tasks.
Polarity Calibration for Opinion Summarization
Apr 02, 2024



Opinion summarization is automatically generating summaries from a variety of subjective information, such as product reviews or political opinions. The challenge of opinions summarization lies in presenting divergent or even conflicting opinions. We conduct an analysis of previous summarization models, which reveals their inclination to amplify the polarity bias, emphasizing the majority opinions while ignoring the minority opinions. To address this issue and make the summarizer express both sides of opinions, we introduce the concept of polarity calibration, which aims to align the polarity of output summary with that of input text. Specifically, we develop a reinforcement training approach for polarity calibration. This approach feeds the polarity distance between output summary and input text as reward into the summarizer, and also balance polarity calibration with content preservation and language naturality. We evaluate our Polarity Calibration model (PoCa) on two types of opinions summarization tasks: summarizing product reviews and political opinions articles. Automatic and human evaluation demonstrate that our approach can mitigate the polarity mismatch between output summary and input text, as well as maintain the content semantic and language quality.
Can Large Language Models do Analytical Reasoning?
Mar 06, 2024

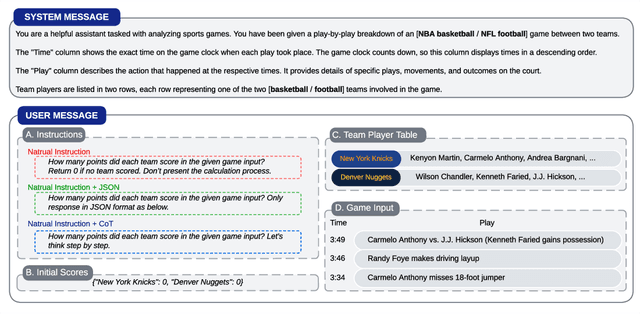
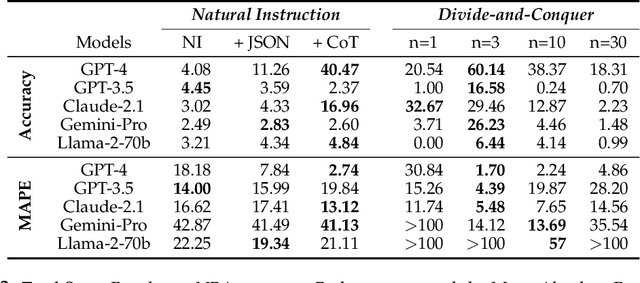
This paper explores the cutting-edge Large Language Model with analytical reasoning on sports. Our analytical reasoning embodies the tasks of letting large language models count how many points each team scores in a quarter in the NBA and NFL games. Our major discoveries are in two folds. Firstly, we find among all the models we employed, GPT-4 stands out in effectiveness, followed by Claude-2.1, with GPT-3.5, Gemini-Pro, and Llama-2-70b lagging behind. Specifically, we compare three different prompting techniques and a divide-and-conquer approach, we find that the latter was the most effective. Our divide-and-conquer approach breaks down play-by-play data into smaller, more manageable segments, solves each piece individually, and then aggregates them together. Besides the divide-and-conquer approach, we also explore the Chain of Thought (CoT) strategy, which markedly improves outcomes for certain models, notably GPT-4 and Claude-2.1, with their accuracy rates increasing significantly. However, the CoT strategy has negligible or even detrimental effects on the performance of other models like GPT-3.5 and Gemini-Pro. Secondly, to our surprise, we observe that most models, including GPT-4, struggle to accurately count the total scores for NBA quarters despite showing strong performance in counting NFL quarter scores. This leads us to further investigate the factors that impact the complexity of analytical reasoning tasks with extensive experiments, through which we conclude that task complexity depends on the length of context, the information density, and the presence of related information. Our research provides valuable insights into the complexity of analytical reasoning tasks and potential directions for developing future large language models.
SportsMetrics: Blending Text and Numerical Data to Understand Information Fusion in LLMs
Feb 15, 2024Large language models hold significant potential for integrating various data types, such as text documents and database records, for advanced analytics. However, blending text and numerical data presents substantial challenges. LLMs need to process and cross-reference entities and numbers, handle data inconsistencies and redundancies, and develop planning capabilities such as building a working memory for managing complex data queries. In this paper, we introduce four novel tasks centered around sports data analytics to evaluate the numerical reasoning and information fusion capabilities of LLMs. These tasks involve providing LLMs with detailed, play-by-play sports game descriptions, then challenging them with adversarial scenarios such as new game rules, longer durations, scrambled narratives, and analyzing key statistics in game summaries. We conduct extensive experiments on NBA and NFL games to assess the performance of LLMs on these tasks. Our benchmark, SportsMetrics, introduces a new mechanism for assessing LLMs' numerical reasoning and fusion skills.
SPECTRUM: Speaker-Enhanced Pre-Training for Long Dialogue Summarization
Jan 31, 2024Multi-turn dialogues are characterized by their extended length and the presence of turn-taking conversations. Traditional language models often overlook the distinct features of these dialogues by treating them as regular text. In this paper, we propose a speaker-enhanced pre-training method for long dialogue summarization, which leverages the inherent structure of multiple-turn dialogues. To support our study, we curate a diverse dataset that includes transcripts from real-world scenarios, movie or TV show transcripts, and dialogues generated by a Large Language Model. We then perform a pre-training, which encompasses the detection of speaker changes, and masked utterance generation. Experimental results of fine-tuned models demonstrate that our model achieves state-of-the-art performance on downstream benchmarks with long context, surpassing baseline models and highlighting the effectiveness of our approach. Our findings highlight the importance of curating pre-training datasets that exhibit diversity and variations in length distribution to ensure effective alignment with downstream datasets.