 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhite Men Lead, Black Women Help: Uncovering Gender, Racial, and Intersectional Bias in Language Agency
Apr 16, 2024Social biases can manifest in language agency. For instance, White individuals and men are often described as "agentic" and achievement-oriented, whereas Black individuals and women are frequently described as "communal" and as assisting roles. This study establishes agency as an important aspect of studying social biases in both human-written and Large Language Model (LLM)-generated texts. To accurately measure "language agency" at sentence level, we propose a Language Agency Classification dataset to train reliable agency classifiers. We then use an agency classifier to reveal notable language agency biases in 6 datasets of human- or LLM-written texts, including biographies, professor reviews, and reference letters. While most prior NLP research on agency biases focused on single dimensions, we comprehensively explore language agency biases in gender, race, and intersectional identities. We observe that (1) language agency biases in human-written texts align with real-world social observations; (2) LLM-generated texts demonstrate remarkably higher levels of language agency bias than human-written texts; and (3) critical biases in language agency target people of minority groups -- for instance, languages used to describe Black females exhibit the lowest level of agency across datasets. Our findings reveal intricate social biases in human- and LLM-written texts through the lens of language agency, warning against using LLM generations in social contexts without scrutiny.
LLMs in Biomedicine: A study on clinical Named Entity Recognition
Apr 10, 2024



Large Language Models (LLMs) demonstrate remarkable versatility in various NLP tasks but encounter distinct challenges in biomedicine due to medical language complexities and data scarcity. This paper investigates the application of LLMs in the medical domain by exploring strategies to enhance their performance for the Named-Entity Recognition (NER) task. Specifically, our study reveals the importance of meticulously designed prompts in biomedicine. Strategic selection of in-context examples yields a notable improvement, showcasing ~15-20\% increase in F1 score across all benchmark datasets for few-shot clinical NER. Additionally, our findings suggest that integrating external resources through prompting strategies can bridge the gap between general-purpose LLM proficiency and the specialized demands of medical NER. Leveraging a medical knowledge base, our proposed method inspired by Retrieval-Augmented Generation (RAG) can boost the F1 score of LLMs for zero-shot clinical NER. We will release the code upon publication.
GenEARL: A Training-Free Generative Framework for Multimodal Event Argument Role Labeling
Apr 07, 2024



Multimodal event argument role labeling (EARL), a task that assigns a role for each event participant (object) in an image is a complex challenge. It requires reasoning over the entire image, the depicted event, and the interactions between various objects participating in the event. Existing models heavily rely on high-quality event-annotated training data to understand the event semantics and structures, and they fail to generalize to new event types and domains. In this paper, we propose GenEARL, a training-free generative framework that harness the power of the modern generative models to understand event task descriptions given image contexts to perform the EARL task. Specifically, GenEARL comprises two stages of generative prompting with a frozen vision-language model (VLM) and a frozen large language model (LLM). First, a generative VLM learns the semantics of the event argument roles and generates event-centric object descriptions based on the image. Subsequently, a LLM is prompted with the generated object descriptions with a predefined template for EARL (i.e., assign an object with an event argument role). We show that GenEARL outperforms the contrastive pretraining (CLIP) baseline by 9.4% and 14.2% accuracy for zero-shot EARL on the M2E2 and SwiG datasets, respectively. In addition, we outperform CLIP-Event by 22% precision on M2E2 dataset. The framework also allows flexible adaptation and generalization to unseen domains.
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Apr 04, 2024



We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., <1B) language model (LM) for guiding a black-box large (i.e., >10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
Survey of Bias In Text-to-Image Generation: Definition, Evaluation, and Mitigation
Apr 02, 2024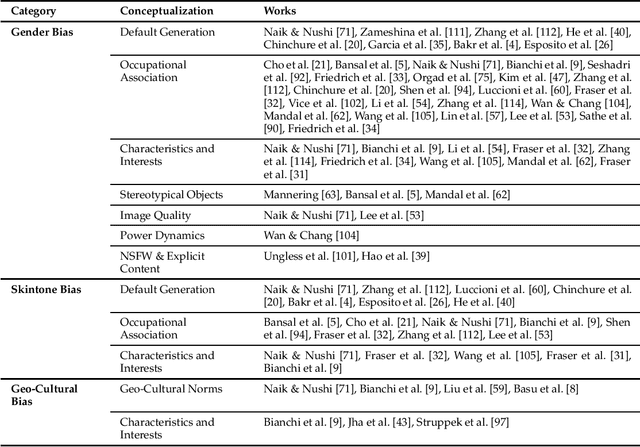
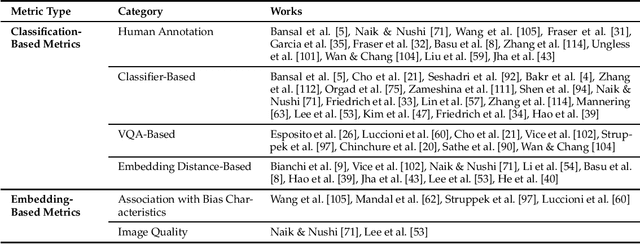
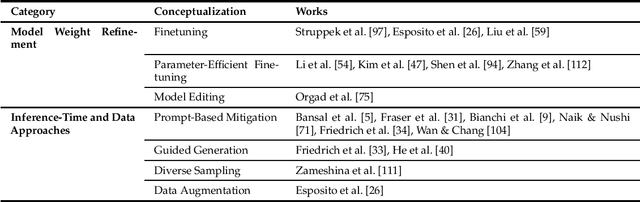
The recent advancement of large and powerful models with Text-to-Image (T2I) generation abilities -- such as OpenAI's DALLE-3 and Google's Gemini -- enables users to generate high-quality images from textual prompts. However, it has become increasingly evident that even simple prompts could cause T2I models to exhibit conspicuous social bias in generated images. Such bias might lead to both allocational and representational harms in society, further marginalizing minority groups. Noting this problem, a large body of recent works has been dedicated to investigating different dimensions of bias in T2I systems. However, an extensive review of these studies is lacking, hindering a systematic understanding of current progress and research gaps. We present the first extensive survey on bias in T2I generative models. In this survey, we review prior studies on dimensions of bias: Gender, Skintone, and Geo-Culture. Specifically, we discuss how these works define, evaluate, and mitigate different aspects of bias. We found that: (1) while gender and skintone biases are widely studied, geo-cultural bias remains under-explored; (2) most works on gender and skintone bias investigated occupational association, while other aspects are less frequently studied; (3) almost all gender bias works overlook non-binary identities in their studies; (4) evaluation datasets and metrics are scattered, with no unified framework for measuring biases; and (5) current mitigation methods fail to resolve biases comprehensively. Based on current limitations, we point out future research directions that contribute to human-centric definitions, evaluations, and mitigation of biases. We hope to highlight the importance of studying biases in T2I systems, as well as encourage future efforts to holistically understand and tackle biases, building fair and trustworthy T2I technologies for everyone.
Event Detection from Social Media for Epidemic Prediction
Apr 02, 2024



Social media is an easy-to-access platform providing timely updates about societal trends and events. Discussions regarding epidemic-related events such as infections, symptoms, and social interactions can be crucial for informing policymaking during epidemic outbreaks. In our work, we pioneer exploiting Event Detection (ED) for better preparedness and early warnings of any upcoming epidemic by developing a framework to extract and analyze epidemic-related events from social media posts. To this end, we curate an epidemic event ontology comprising seven disease-agnostic event types and construct a Twitter dataset SPEED with human-annotated events focused on the COVID-19 pandemic. Experimentation reveals how ED models trained on COVID-based SPEED can effectively detect epidemic events for three unseen epidemics of Monkeypox, Zika, and Dengue; while models trained on existing ED datasets fail miserably. Furthermore, we show that reporting sharp increases in the extracted events by our framework can provide warnings 4-9 weeks earlier than the WHO epidemic declaration for Monkeypox. This utility of our framework lays the foundations for better preparedness against emerging epidemics.
Comparing Bad Apples to Good Oranges: Aligning Large Language Models via Joint Preference Optimization
Mar 31, 2024A common technique for aligning large language models (LLMs) relies on acquiring human preferences by comparing multiple generations conditioned on a fixed context. This only leverages the pairwise comparisons when the generations are placed in an identical context. However, such conditional rankings often fail to capture the complex and multidimensional aspects of human preferences. In this work, we revisit the traditional paradigm of preference acquisition and propose a new axis that is based on eliciting preferences jointly over the instruction-response pairs. While prior preference optimizations are designed for conditional ranking protocols (e.g., DPO), our proposed preference acquisition protocol introduces DOVE, a new preference optimization objective that upweights the joint probability of the chosen instruction-response pair over the rejected instruction-response pair. Interestingly, we find that the LLM trained with joint instruction-response preference data using DOVE outperforms the LLM trained with DPO by 5.2% and 3.3% win-rate for the summarization and open-ended dialogue datasets, respectively. Our findings reveal that joint preferences over instruction and response pairs can significantly enhance the alignment of LLMs by tapping into a broader spectrum of human preference elicitation. The data and code is available at https://github.com/Hritikbansal/dove.
MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?
Mar 21, 2024



The remarkable progress of Multi-modal Large Language Models (MLLMs) has garnered unparalleled attention, due to their superior performance in visual contexts. However, their capabilities in visual math problem-solving remain insufficiently evaluated and understood. We investigate current benchmarks to incorporate excessive visual content within textual questions, which potentially assist MLLMs in deducing answers without truly interpreting the input diagrams. To this end, we introduce MathVerse, an all-around visual math benchmark designed for an equitable and in-depth evaluation of MLLMs. We meticulously collect 2,612 high-quality, multi-subject math problems with diagrams from publicly available sources. Each problem is then transformed by human annotators into six distinct versions, each offering varying degrees of information content in multi-modality, contributing to 15K test samples in total. This approach allows MathVerse to comprehensively assess whether and how much MLLMs can truly understand the visual diagrams for mathematical reasoning. In addition, we propose a Chain-of-Thought (CoT) evaluation strategy for a fine-grained assessment of the output answers. Rather than naively judging True or False, we employ GPT-4(V) to adaptively extract crucial reasoning steps, and then score each step with detailed error analysis, which can reveal the intermediate CoT reasoning quality by MLLMs. We hope the MathVerse benchmark may provide unique insights to guide the future development of MLLMs. Project page: https://mathverse-cuhk.github.io
DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation
Mar 04, 2024



Data analysis is a crucial analytical process to generate in-depth studies and conclusive insights to comprehensively answer a given user query for tabular data. In this work, we aim to propose new resources and benchmarks to inspire future research on this crucial yet challenging and under-explored task. However, collecting data analysis annotations curated by experts can be prohibitively expensive. We propose to automatically generate high-quality answer annotations leveraging the code-generation capabilities of LLMs with a multi-turn prompting technique. We construct the DACO dataset, containing (1) 440 databases (of tabular data) collected from real-world scenarios, (2) ~2k query-answer pairs that can serve as weak supervision for model training, and (3) a concentrated but high-quality test set with human refined annotations that serves as our main evaluation benchmark. We train a 6B supervised fine-tuning (SFT) model on DACO dataset, and find that the SFT model learns reasonable data analysis capabilities. To further align the models with human preference, we use reinforcement learning to encourage generating analysis perceived by human as helpful, and design a set of dense rewards to propagate the sparse human preference reward to intermediate code generation steps. Our DACO-RL algorithm is evaluated by human annotators to produce more helpful answers than SFT model in 57.72% cases, validating the effectiveness of our proposed algorithm. Data and code are released at https://github.com/shirley-wu/daco
Characterizing Truthfulness in Large Language Model Generations with Local Intrinsic Dimension
Feb 28, 2024



We study how to characterize and predict the truthfulness of texts generated from large language models (LLMs), which serves as a crucial step in building trust between humans and LLMs. Although several approaches based on entropy or verbalized uncertainty have been proposed to calibrate model predictions, these methods are often intractable, sensitive to hyperparameters, and less reliable when applied in generative tasks with LLMs. In this paper, we suggest investigating internal activations and quantifying LLM's truthfulness using the local intrinsic dimension (LID) of model activations. Through experiments on four question answering (QA) datasets, we demonstrate the effectiveness ohttps://info.arxiv.org/help/prep#abstractsf our proposed method. Additionally, we study intrinsic dimensions in LLMs and their relations with model layers, autoregressive language modeling, and the training of LLMs, revealing that intrinsic dimensions can be a powerful approach to understanding LLMs.