 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverting Neural Networks: New Methods to Generate Neural Network Inputs from Prescribed Outputs
Mar 20, 2026Neural network systems describe complex mappings that can be very difficult to understand. In this paper, we study the inverse problem of determining the input images that get mapped to specific neural network classes. Ultimately, we expect that these images contain recognizable features that are associated with their corresponding class classifications. We introduce two general methods for solving the inverse problem. In our forward pass method, we develop an inverse method based on a root-finding algorithm and the Jacobian with respect to the input image. In our backward pass method, we iteratively invert each layer, at the top. During the inversion process, we add random vectors sampled from the null-space of each linear layer. We demonstrate our new methods on both transformer architectures and sequential networks based on linear layers. Unlike previous methods, we show that our new methods are able to produce random-like input images that yield near perfect classification scores in all cases, revealing vulnerabilities in the underlying networks. Hence, we conclude that the proposed methods provide a more comprehensive coverage of the input image spaces that solve the inverse mapping problem.
Survey of Bias In Text-to-Image Generation: Definition, Evaluation, and Mitigation
Apr 02, 2024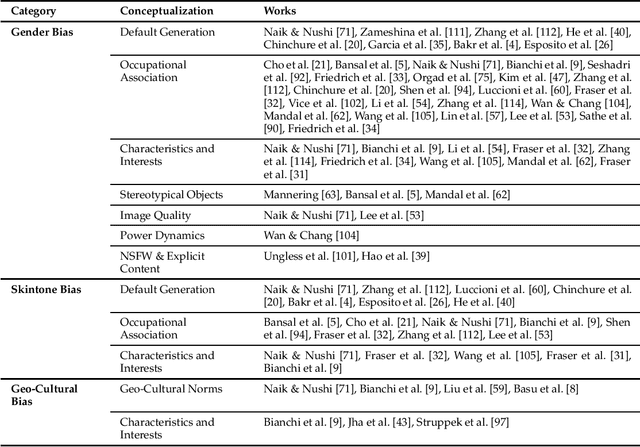
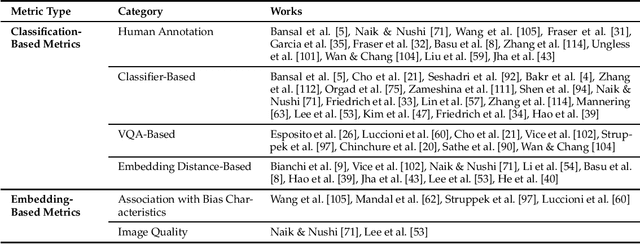
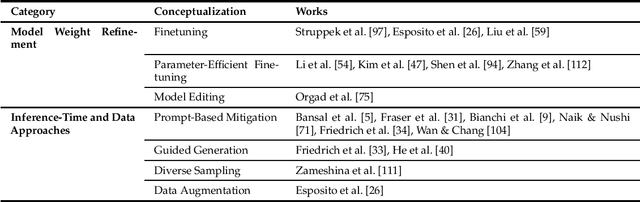
The recent advancement of large and powerful models with Text-to-Image (T2I) generation abilities -- such as OpenAI's DALLE-3 and Google's Gemini -- enables users to generate high-quality images from textual prompts. However, it has become increasingly evident that even simple prompts could cause T2I models to exhibit conspicuous social bias in generated images. Such bias might lead to both allocational and representational harms in society, further marginalizing minority groups. Noting this problem, a large body of recent works has been dedicated to investigating different dimensions of bias in T2I systems. However, an extensive review of these studies is lacking, hindering a systematic understanding of current progress and research gaps. We present the first extensive survey on bias in T2I generative models. In this survey, we review prior studies on dimensions of bias: Gender, Skintone, and Geo-Culture. Specifically, we discuss how these works define, evaluate, and mitigate different aspects of bias. We found that: (1) while gender and skintone biases are widely studied, geo-cultural bias remains under-explored; (2) most works on gender and skintone bias investigated occupational association, while other aspects are less frequently studied; (3) almost all gender bias works overlook non-binary identities in their studies; (4) evaluation datasets and metrics are scattered, with no unified framework for measuring biases; and (5) current mitigation methods fail to resolve biases comprehensively. Based on current limitations, we point out future research directions that contribute to human-centric definitions, evaluations, and mitigation of biases. We hope to highlight the importance of studying biases in T2I systems, as well as encourage future efforts to holistically understand and tackle biases, building fair and trustworthy T2I technologies for everyone.
Understanding Neural Network Systems for Image Analysis using Vector Spaces and Inverse Maps
Feb 01, 2024


There is strong interest in developing mathematical methods that can be used to understand complex neural networks used in image analysis. In this paper, we introduce techniques from Linear Algebra to model neural network layers as maps between signal spaces. First, we demonstrate how signal spaces can be used to visualize weight spaces and convolutional layer kernels. We also demonstrate how residual vector spaces can be used to further visualize information lost at each layer. Second, we introduce the concept of invertible networks and an algorithm for computing input images that yield specific outputs. We demonstrate our approach on two invertible networks and ResNet18.
Leveraging Language Models to Detect Greenwashing
Oct 30, 2023In recent years, climate change repercussions have increasingly captured public interest. Consequently, corporations are emphasizing their environmental efforts in sustainability reports to bolster their public image. Yet, the absence of stringent regulations in review of such reports allows potential greenwashing. In this study, we introduce a novel methodology to train a language model on generated labels for greenwashing risk. Our primary contributions encompass: developing a mathematical formulation to quantify greenwashing risk, a fine-tuned ClimateBERT model for this problem, and a comparative analysis of results. On a test set comprising of sustainability reports, our best model achieved an average accuracy score of 86.34% and F1 score of 0.67, demonstrating that our methods show a promising direction of exploration for this task.