 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Personalized Semantic Facial NeRF Models From Monocular Video
Oct 12, 2022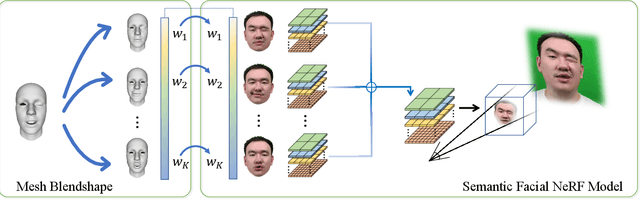

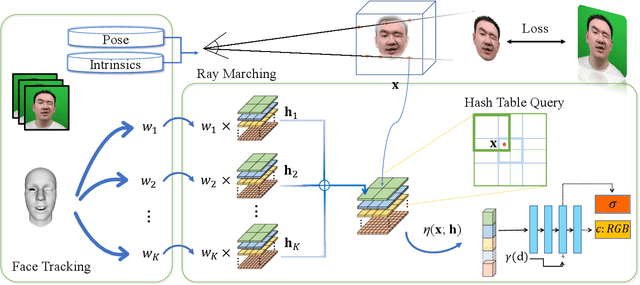
We present a novel semantic model for human head defined with neural radiance field. The 3D-consistent head model consist of a set of disentangled and interpretable bases, and can be driven by low-dimensional expression coefficients. Thanks to the powerful representation ability of neural radiance field, the constructed model can represent complex facial attributes including hair, wearings, which can not be represented by traditional mesh blendshape. To construct the personalized semantic facial model, we propose to define the bases as several multi-level voxel fields. With a short monocular RGB video as input, our method can construct the subject's semantic facial NeRF model with only ten to twenty minutes, and can render a photo-realistic human head image in tens of miliseconds with a given expression coefficient and view direction. With this novel representation, we apply it to many tasks like facial retargeting and expression editing. Experimental results demonstrate its strong representation ability and training/inference speed. Demo videos and released code are provided in our project page: https://ustc3dv.github.io/NeRFBlendShape/
* Accepted by SIGGRAPH Asia 2022 (Journal Track). Project page: https://ustc3dv.github.io/NeRFBlendShape/
SelfNeRF: Fast Training NeRF for Human from Monocular Self-rotating Video
Oct 04, 2022
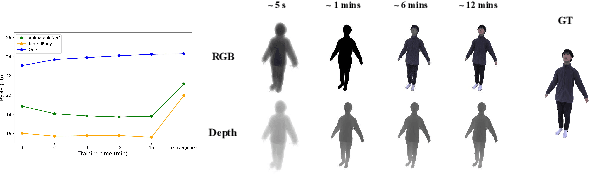
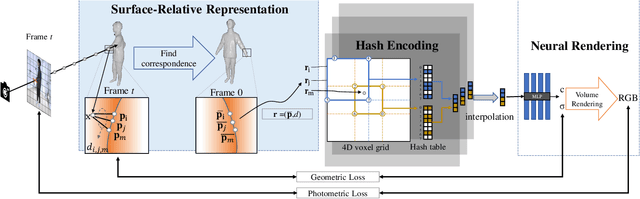
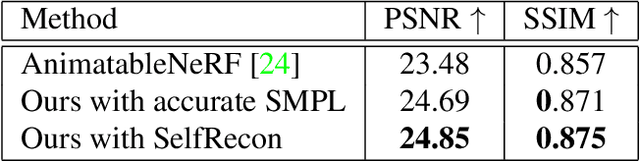
In this paper, we propose SelfNeRF, an efficient neural radiance field based novel view synthesis method for human performance. Given monocular self-rotating videos of human performers, SelfNeRF can train from scratch and achieve high-fidelity results in about twenty minutes. Some recent works have utilized the neural radiance field for dynamic human reconstruction. However, most of these methods need multi-view inputs and require hours of training, making it still difficult for practical use. To address this challenging problem, we introduce a surface-relative representation based on multi-resolution hash encoding that can greatly improve the training speed and aggregate inter-frame information. Extensive experimental results on several different datasets demonstrate the effectiveness and efficiency of SelfNeRF to challenging monocular videos.
Neural Surface Reconstruction of Dynamic Scenes with Monocular RGB-D Camera
Jun 30, 2022
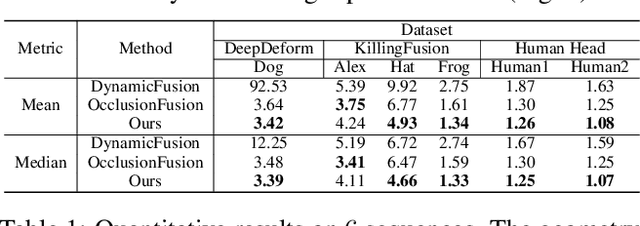
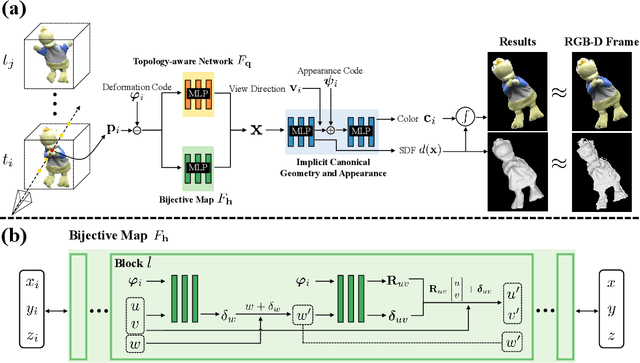

We propose Neural-DynamicReconstruction (NDR), a template-free method to recover high-fidelity geometry and motions of a dynamic scene from a monocular RGB-D camera. In NDR, we adopt the neural implicit function for surface representation and rendering such that the captured color and depth can be fully utilized to jointly optimize the surface and deformations. To represent and constrain the non-rigid deformations, we propose a novel neural invertible deforming network such that the cycle consistency between arbitrary two frames is automatically satisfied. Considering that the surface topology of dynamic scene might change over time, we employ a topology-aware strategy to construct the topology-variant correspondence for the fused frames. NDR also further refines the camera poses in a global optimization manner. Experiments on public datasets and our collected dataset demonstrate that NDR outperforms existing monocular dynamic reconstruction methods.
Fast and Robust Non-Rigid Registration Using Accelerated Majorization-Minimization
Jun 08, 2022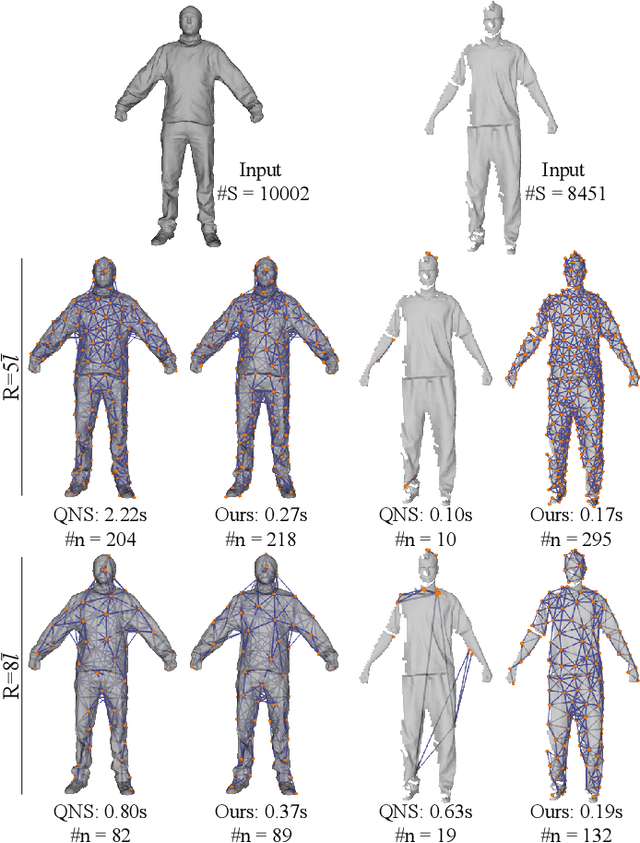
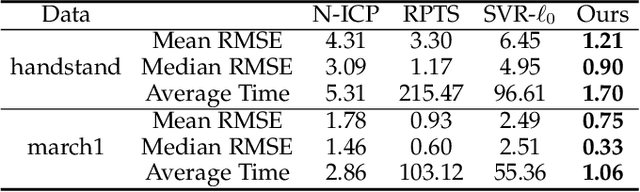
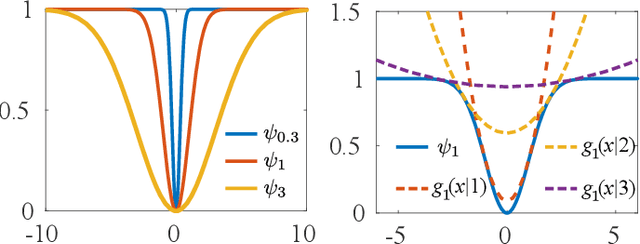
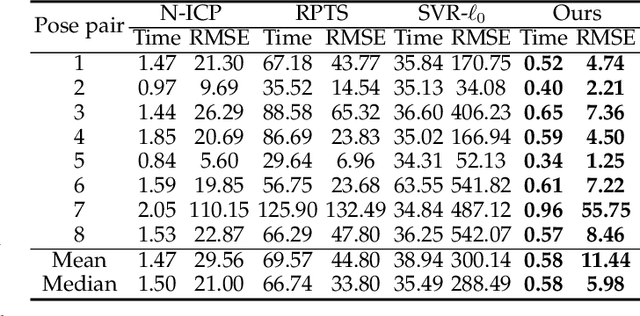
Non-rigid registration, which deforms a source shape in a non-rigid way to align with a target shape, is a classical problem in computer vision. Such problems can be challenging because of imperfect data (noise, outliers and partial overlap) and high degrees of freedom. Existing methods typically adopt the $\ell_{p}$ type robust norm to measure the alignment error and regularize the smoothness of deformation, and use a proximal algorithm to solve the resulting non-smooth optimization problem. However, the slow convergence of such algorithms limits their wide applications. In this paper, we propose a formulation for robust non-rigid registration based on a globally smooth robust norm for alignment and regularization, which can effectively handle outliers and partial overlaps. The problem is solved using the majorization-minimization algorithm, which reduces each iteration to a convex quadratic problem with a closed-form solution. We further apply Anderson acceleration to speed up the convergence of the solver, enabling the solver to run efficiently on devices with limited compute capability. Extensive experiments demonstrate the effectiveness of our method for non-rigid alignment between two shapes with outliers and partial overlaps, with quantitative evaluation showing that it outperforms state-of-the-art methods in terms of registration accuracy and computational speed. The source code is available at https://github.com/yaoyx689/AMM_NRR.
A Survey of Non-Rigid 3D Registration
Mar 16, 2022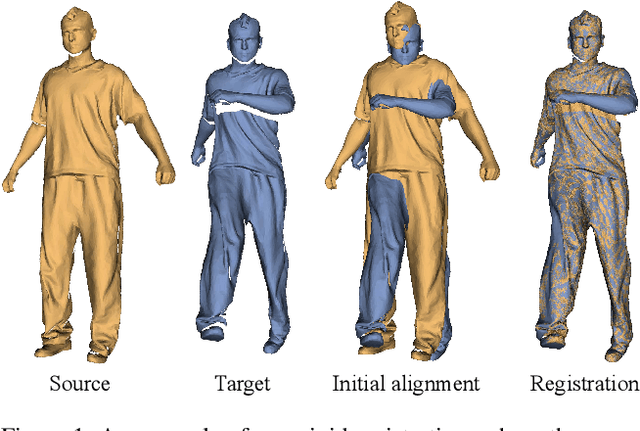
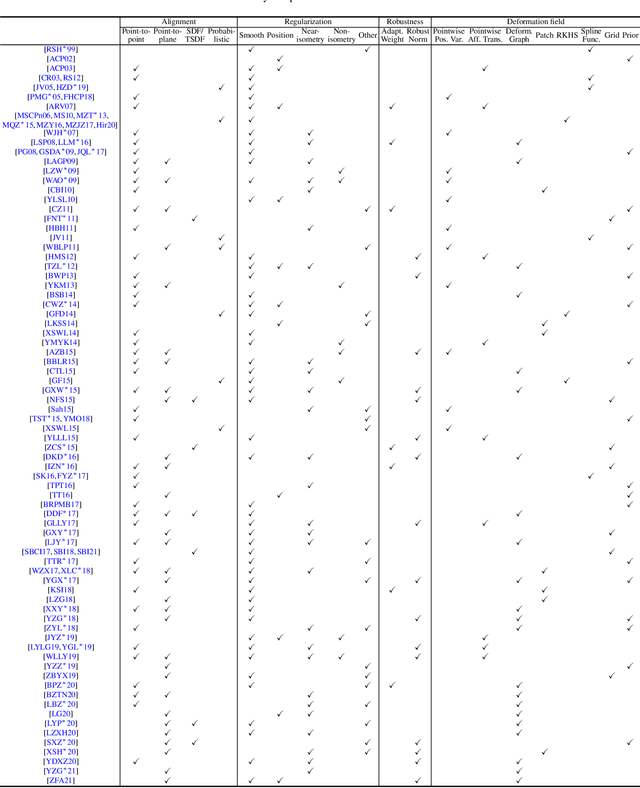
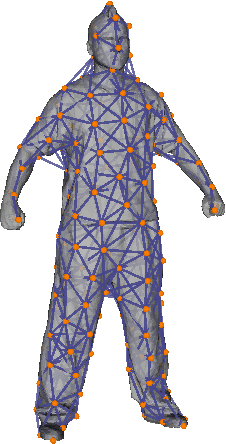

Non-rigid registration computes an alignment between a source surface with a target surface in a non-rigid manner. In the past decade, with the advances in 3D sensing technologies that can measure time-varying surfaces, non-rigid registration has been applied for the acquisition of deformable shapes and has a wide range of applications. This survey presents a comprehensive review of non-rigid registration methods for 3D shapes, focusing on techniques related to dynamic shape acquisition and reconstruction. In particular, we review different approaches for representing the deformation field, and the methods for computing the desired deformation. Both optimization-based and learning-based methods are covered. We also review benchmarks and datasets for evaluating non-rigid registration methods, and discuss potential future research directions.
SelfRecon: Self Reconstruction Your Digital Avatar from Monocular Video
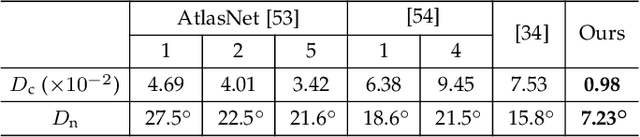
Jan 30, 2022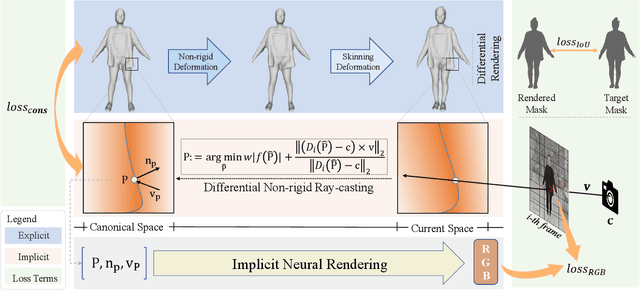
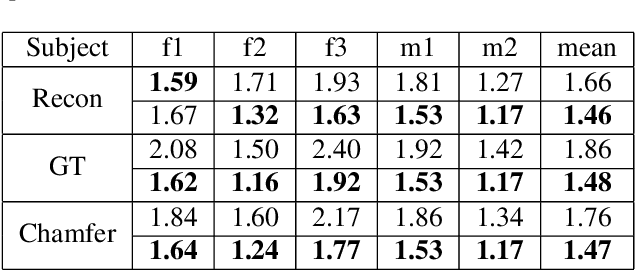
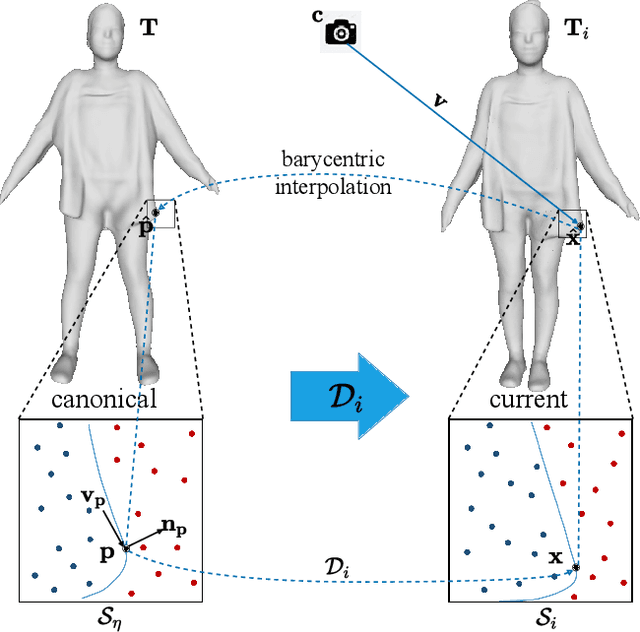

We propose SelfRecon, a clothed human body reconstruction method that combines implicit and explicit representations to recover space-time coherent geometries from a monocular self-rotating human video. Explicit methods require a predefined template mesh for a given sequence, while the template is hard to acquire for a specific subject. Meanwhile, the fixed topology limits the reconstruction accuracy and clothing types. Implicit methods support arbitrary topology and have high quality due to continuous geometric representation. However, it is difficult to integrate multi-frame information to produce a consistent registration sequence for downstream applications. We propose to combine the advantages of both representations. We utilize differential mask loss of the explicit mesh to obtain the coherent overall shape, while the details on the implicit surface are refined with the differentiable neural rendering. Meanwhile, the explicit mesh is updated periodically to adjust its topology changes, and a consistency loss is designed to match both representations closely. Compared with existing methods, SelfRecon can produce high-fidelity surfaces for arbitrary clothed humans with self-supervised optimization. Extensive experimental results demonstrate its effectiveness on real captured monocular videos.
Sketch2PQ: Freeform Planar Quadrilateral Mesh Design via a Single Sketch
Jan 23, 2022
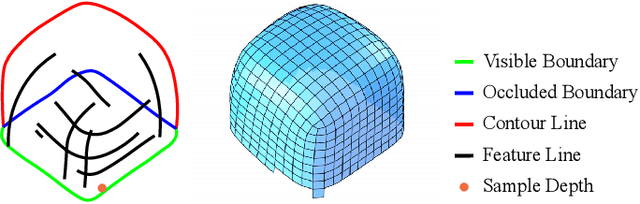
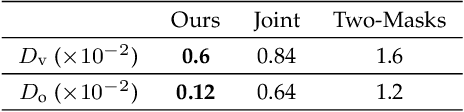
The freeform architectural modeling process often involves two important stages: concept design and digital modeling. In the first stage, architects usually sketch the overall 3D shape and the panel layout on a physical or digital paper briefly. In the second stage, a digital 3D model is created using the sketching as the reference. The digital model needs to incorporate geometric requirements for its components, such as planarity of panels due to consideration of construction costs, which can make the modeling process more challenging. In this work, we present a novel sketch-based system to bridge the concept design and digital modeling of freeform roof-like shapes represented as planar quadrilateral (PQ) meshes. Our system allows the user to sketch the surface boundary and contour lines under axonometric projection and supports the sketching of occluded regions. In addition, the user can sketch feature lines to provide directional guidance to the PQ mesh layout. Given the 2D sketch input, we propose a deep neural network to infer in real-time the underlying surface shape along with a dense conjugate direction field, both of which are used to extract the final PQ mesh. To train and validate our network, we generate a large synthetic dataset that mimics architect sketching of freeform quadrilateral patches. The effectiveness and usability of our system are demonstrated with quantitative and qualitative evaluation as well as user studies.
Audio-Driven Talking Face Video Generation with Dynamic Convolution Kernels
Jan 16, 2022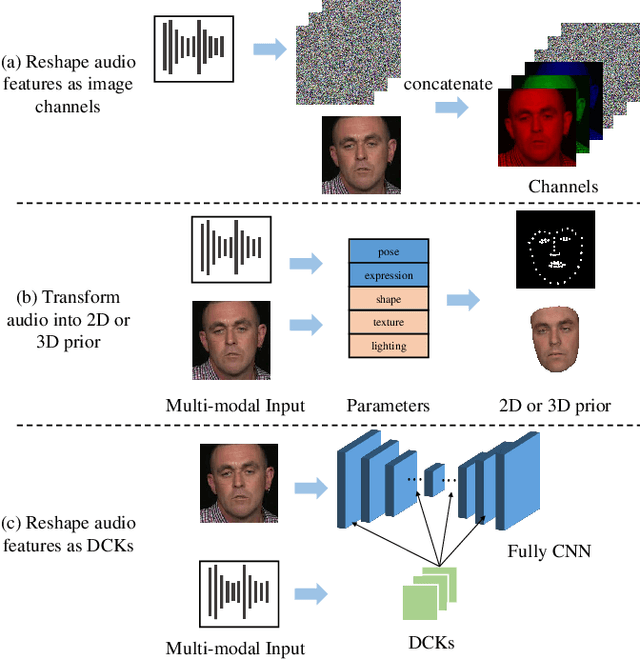
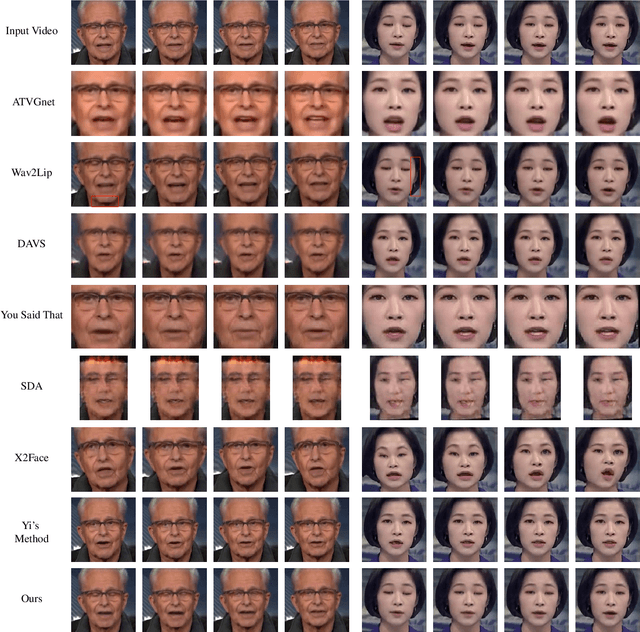
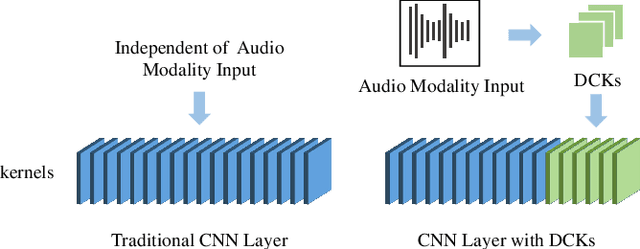
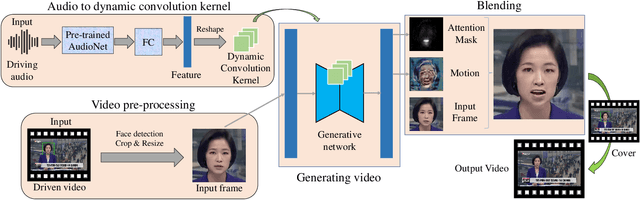
In this paper, we present a dynamic convolution kernel (DCK) strategy for convolutional neural networks. Using a fully convolutional network with the proposed DCKs, high-quality talking-face video can be generated from multi-modal sources (i.e., unmatched audio and video) in real time, and our trained model is robust to different identities, head postures, and input audios. Our proposed DCKs are specially designed for audio-driven talking face video generation, leading to a simple yet effective end-to-end system. We also provide a theoretical analysis to interpret why DCKs work. Experimental results show that our method can generate high-quality talking-face video with background at 60 fps. Comparison and evaluation between our method and the state-of-the-art methods demonstrate the superiority of our method.
Neural Points: Point Cloud Representation with Neural Fields
Dec 13, 2021
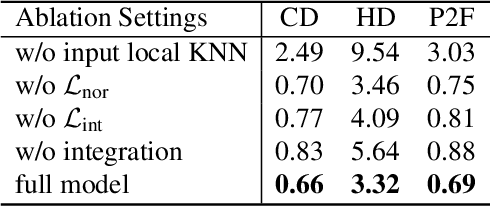
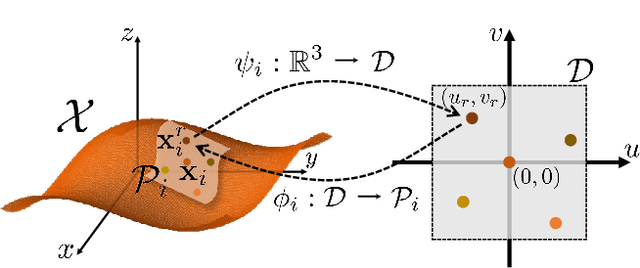
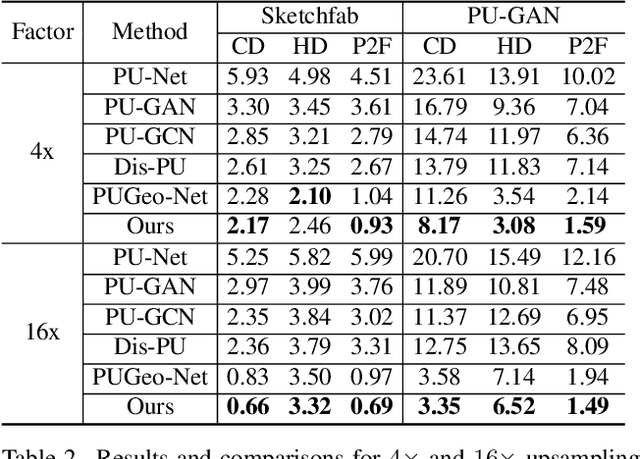
In this paper, we propose \emph{Neural Points}, a novel point cloud representation. Unlike traditional point cloud representation where each point only represents a position or a local plane in the 3D space, each point in Neural Points represents a local continuous geometric shape via neural fields. Therefore, Neural Points can express much more complex details and thus have a stronger representation ability. Neural Points is trained with high-resolution surface containing rich geometric details, such that the trained model has enough expression ability for various shapes. Specifically, we extract deep local features on the points and construct neural fields through the local isomorphism between the 2D parametric domain and the 3D local patch. In the final, local neural fields are integrated together to form the global surface. Experimental results show that Neural Points has powerful representation ability and demonstrate excellent robustness and generalization ability. With Neural Points, we can resample point cloud with arbitrary resolutions, and it outperforms state-of-the-art point cloud upsampling methods by a large margin.
HeadNeRF: A Real-time NeRF-based Parametric Head Model
Dec 13, 2021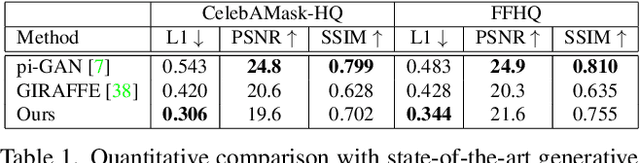
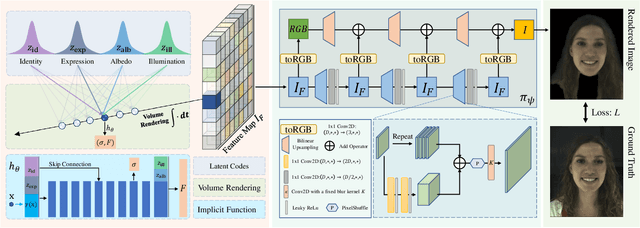


In this paper, we propose HeadNeRF, a novel NeRF-based parametric head model that integrates the neural radiance field to the parametric representation of the human head. It can render high fidelity head images in real-time, and supports directly controlling the generated images' rendering pose and various semantic attributes. Different from existing related parametric models, we use the neural radiance fields as a novel 3D proxy instead of the traditional 3D textured mesh, which makes that HeadNeRF is able to generate high fidelity images. However, the computationally expensive rendering process of the original NeRF hinders the construction of the parametric NeRF model. To address this issue, we adopt the strategy of integrating 2D neural rendering to the rendering process of NeRF and design novel loss terms. As a result, the rendering speed of HeadNeRF can be significantly accelerated, and the rendering time of one frame is reduced from 5s to 25ms. The novel-designed loss terms also improve the rendering accuracy, and the fine-level details of the human head, such as the gaps between teeth, wrinkles, and beards, can be represented and synthesized by HeadNeRF. Extensive experimental results and several applications demonstrate its effectiveness. We will release the code and trained model to the public.