 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpongeBob: Sync-Aware Harmonious Audio-Visual Generative Editing
May 24, 2026Visual and acoustic events in the physical world are inherently coupled, yet existing video editing methods typically adopt decoupled pipelines, lacking bidirectional modality interaction. This results in two key limitations: (i) audio-visual desynchronization and (ii) contextual conflicts between generated audio and preserved content. To address these, we propose SpongeBob, the first end-to-end audio-visual joint editing framework featuring bidirectional cross-modal interaction. For synchronization, a Sync-Aware Mechanism aligns visual edits with sound events via bidirectional attention, temporal alignment, and spatial constraints. For contextual consistency, a Context-Aware Module leverages acoustic and visual context attention to prevent semantic clashes. Additionally, we introduce Sync-Preserving Training and Guidance (SPTG) to enhance alignment without degrading quality. Due to the scarcity of paired data, we construct a scalable data pipeline and a large-scale subject-level dataset. We also propose SpongeBob-Bench for systematic evaluation. Experiments show SpongeBob significantly outperforms existing baselines, improving Sync-C by 30% and Ctx-F1 by 12.5%. Our project page is available at: https://hy-spongebob.github.io/.
FaithfulFaces: Pose-Faithful Facial Identity Preservation for Text-to-Video Generation
May 06, 2026Identity-preserving text-to-video generation (IPT2V) empowers users to produce diverse and imaginative videos with consistent human facial identity. Despite recent progress, existing methods often suffer from significant identity distortion under large facial pose variations or facial occlusions. In this paper, we propose \textit{FaithfulFaces}, a pose-faithful facial identity preservation learning framework to improve IPT2V in complex dynamic scenes. The key of FaithfulFaces is a pose-shared identity aligner that refines and aligns facial poses across distinct views via a pose-shared dictionary and a pose variation-identity invariance constraint. By mapping single-view inputs into a global facial pose representation with explicit Euler angle embeddings, FaithfulFaces provides a pose-faithful facial prior that guides generative foundations toward robust identity-preserving generation. In particular, we develop a specialized pipeline to curate a high-quality video dataset featuring substantial facial pose diversity. Extensive experiments demonstrate that FaithfulFaces achieves state-of-the-art performance, maintaining superior identity consistency and structural clarity even as pose changes and occlusions occur.
Making Avatars Interact: Towards Text-Driven Human-Object Interaction for Controllable Talking Avatars
Feb 02, 2026Generating talking avatars is a fundamental task in video generation. Although existing methods can generate full-body talking avatars with simple human motion, extending this task to grounded human-object interaction (GHOI) remains an open challenge, requiring the avatar to perform text-aligned interactions with surrounding objects. This challenge stems from the need for environmental perception and the control-quality dilemma in GHOI generation. To address this, we propose a novel dual-stream framework, InteractAvatar, which decouples perception and planning from video synthesis for grounded human-object interaction. Leveraging detection to enhance environmental perception, we introduce a Perception and Interaction Module (PIM) to generate text-aligned interaction motions. Additionally, an Audio-Interaction Aware Generation Module (AIM) is proposed to synthesize vivid talking avatars performing object interactions. With a specially designed motion-to-video aligner, PIM and AIM share a similar network structure and enable parallel co-generation of motions and plausible videos, effectively mitigating the control-quality dilemma. Finally, we establish a benchmark, GroundedInter, for evaluating GHOI video generation. Extensive experiments and comparisons demonstrate the effectiveness of our method in generating grounded human-object interactions for talking avatars. Project page: https://interactavatar.github.io
HunyuanVideo-Avatar: High-Fidelity Audio-Driven Human Animation for Multiple Characters
May 26, 2025Recent years have witnessed significant progress in audio-driven human animation. However, critical challenges remain in (i) generating highly dynamic videos while preserving character consistency, (ii) achieving precise emotion alignment between characters and audio, and (iii) enabling multi-character audio-driven animation. To address these challenges, we propose HunyuanVideo-Avatar, a multimodal diffusion transformer (MM-DiT)-based model capable of simultaneously generating dynamic, emotion-controllable, and multi-character dialogue videos. Concretely, HunyuanVideo-Avatar introduces three key innovations: (i) A character image injection module is designed to replace the conventional addition-based character conditioning scheme, eliminating the inherent condition mismatch between training and inference. This ensures the dynamic motion and strong character consistency; (ii) An Audio Emotion Module (AEM) is introduced to extract and transfer the emotional cues from an emotion reference image to the target generated video, enabling fine-grained and accurate emotion style control; (iii) A Face-Aware Audio Adapter (FAA) is proposed to isolate the audio-driven character with latent-level face mask, enabling independent audio injection via cross-attention for multi-character scenarios. These innovations empower HunyuanVideo-Avatar to surpass state-of-the-art methods on benchmark datasets and a newly proposed wild dataset, generating realistic avatars in dynamic, immersive scenarios.
HunyuanCustom: A Multimodal-Driven Architecture for Customized Video Generation
May 08, 2025Customized video generation aims to produce videos featuring specific subjects under flexible user-defined conditions, yet existing methods often struggle with identity consistency and limited input modalities. In this paper, we propose HunyuanCustom, a multi-modal customized video generation framework that emphasizes subject consistency while supporting image, audio, video, and text conditions. Built upon HunyuanVideo, our model first addresses the image-text conditioned generation task by introducing a text-image fusion module based on LLaVA for enhanced multi-modal understanding, along with an image ID enhancement module that leverages temporal concatenation to reinforce identity features across frames. To enable audio- and video-conditioned generation, we further propose modality-specific condition injection mechanisms: an AudioNet module that achieves hierarchical alignment via spatial cross-attention, and a video-driven injection module that integrates latent-compressed conditional video through a patchify-based feature-alignment network. Extensive experiments on single- and multi-subject scenarios demonstrate that HunyuanCustom significantly outperforms state-of-the-art open- and closed-source methods in terms of ID consistency, realism, and text-video alignment. Moreover, we validate its robustness across downstream tasks, including audio and video-driven customized video generation. Our results highlight the effectiveness of multi-modal conditioning and identity-preserving strategies in advancing controllable video generation. All the code and models are available at https://hunyuancustom.github.io.
Grounding 3D Scene Affordance From Egocentric Interactions
Sep 29, 2024



Grounding 3D scene affordance aims to locate interactive regions in 3D environments, which is crucial for embodied agents to interact intelligently with their surroundings. Most existing approaches achieve this by mapping semantics to 3D instances based on static geometric structure and visual appearance. This passive strategy limits the agent's ability to actively perceive and engage with the environment, making it reliant on predefined semantic instructions. In contrast, humans develop complex interaction skills by observing and imitating how others interact with their surroundings. To empower the model with such abilities, we introduce a novel task: grounding 3D scene affordance from egocentric interactions, where the goal is to identify the corresponding affordance regions in a 3D scene based on an egocentric video of an interaction. This task faces the challenges of spatial complexity and alignment complexity across multiple sources. To address these challenges, we propose the Egocentric Interaction-driven 3D Scene Affordance Grounding (Ego-SAG) framework, which utilizes interaction intent to guide the model in focusing on interaction-relevant sub-regions and aligns affordance features from different sources through a bidirectional query decoder mechanism. Furthermore, we introduce the Egocentric Video-3D Scene Affordance Dataset (VSAD), covering a wide range of common interaction types and diverse 3D environments to support this task. Extensive experiments on VSAD validate both the feasibility of the proposed task and the effectiveness of our approach.
TIER: Text-Image Encoder-based Regression for AIGC Image Quality Assessment
Jan 11, 2024Recently, AIGC image quality assessment (AIGCIQA), which aims to assess the quality of AI-generated images (AIGIs) from a human perception perspective, has emerged as a new topic in computer vision. Unlike common image quality assessment tasks where images are derived from original ones distorted by noise, blur, and compression, \textit{etc.}, in AIGCIQA tasks, images are typically generated by generative models using text prompts. Considerable efforts have been made in the past years to advance AIGCIQA. However, most existing AIGCIQA methods regress predicted scores directly from individual generated images, overlooking the information contained in the text prompts of these images. This oversight partially limits the performance of these AIGCIQA methods. To address this issue, we propose a text-image encoder-based regression (TIER) framework. Specifically, we process the generated images and their corresponding text prompts as inputs, utilizing a text encoder and an image encoder to extract features from these text prompts and generated images, respectively. To demonstrate the effectiveness of our proposed TIER method, we conduct extensive experiments on several mainstream AIGCIQA databases, including AGIQA-1K, AGIQA-3K, and AIGCIQA2023. The experimental results indicate that our proposed TIER method generally demonstrates superior performance compared to baseline in most cases.
AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis
Mar 20, 2021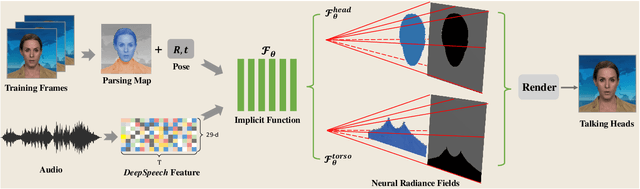
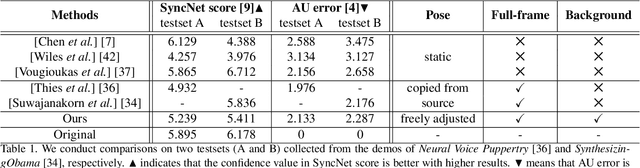
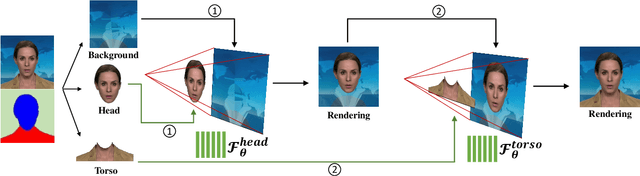
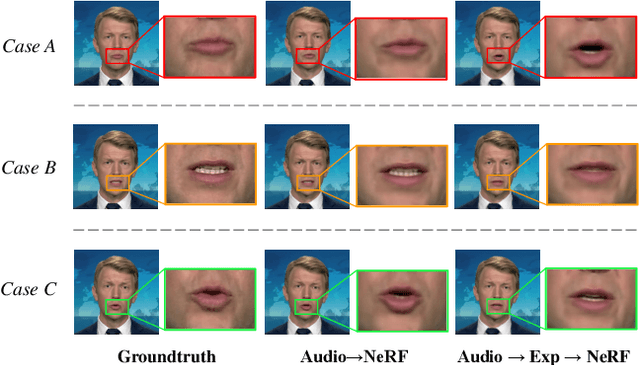
Generating high-fidelity talking head video by fitting with the input audio sequence is a challenging problem that receives considerable attentions recently. In this paper, we address this problem with the aid of neural scene representation networks. Our method is completely different from existing methods that rely on intermediate representations like 2D landmarks or 3D face models to bridge the gap between audio input and video output. Specifically, the feature of input audio signal is directly fed into a conditional implicit function to generate a dynamic neural radiance field, from which a high-fidelity talking-head video corresponding to the audio signal is synthesized using volume rendering. Another advantage of our framework is that not only the head (with hair) region is synthesized as previous methods did, but also the upper body is generated via two individual neural radiance fields. Experimental results demonstrate that our novel framework can (1) produce high-fidelity and natural results, and (2) support free adjustment of audio signals, viewing directions, and background images.
Cross-view Relation Networks for Mammogram Mass Detection
Jul 01, 2019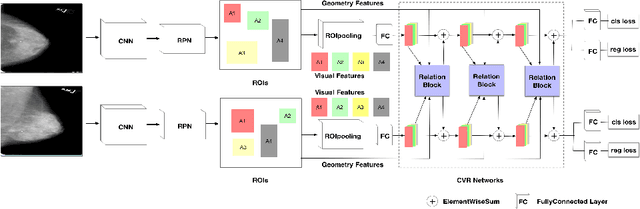
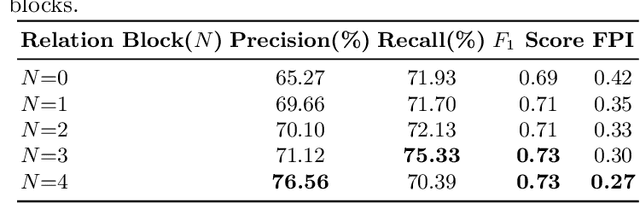
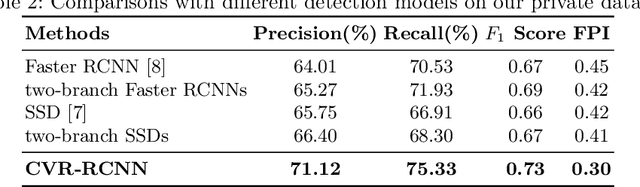
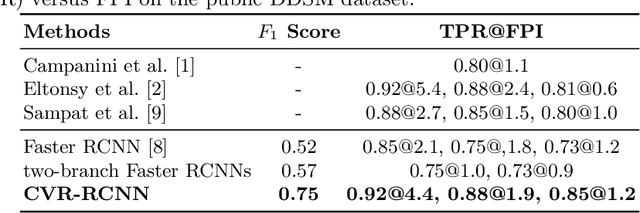
Mammogram is the most effective imaging modality for the mass lesion detection of breast cancer at the early stage. The information from the two paired views (i.e., medio-lateral oblique and cranio-caudal) are highly relational and complementary, and this is crucial for doctors' decisions in clinical practice. However, existing mass detection methods do not consider jointly learning effective features from the two relational views. To address this issue, this paper proposes a novel mammogram mass detection framework, termed Cross-View Relation Region-based Convolutional Neural Networks (CVR-RCNN). The proposed CVR-RCNN is expected to capture the latent relation information between the corresponding mass region of interests (ROIs) from the two paired views. Evaluations on a new large-scale private dataset and a public mammogram dataset show that the proposed CVR-RCNN outperforms existing state-of-the-art mass detection methods. Meanwhile, our experimental results suggest that incorporating the relation information across two views helps to train a superior detection model, which is a promising avenue for mammogram mass detection.
Group-Attention Single-Shot Detector (GA-SSD): Finding Pulmonary Nodules in Large-Scale CT Images
Dec 18, 2018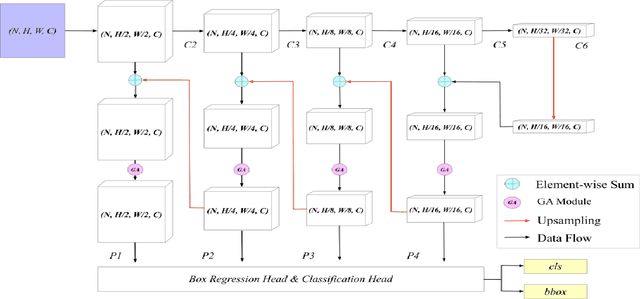
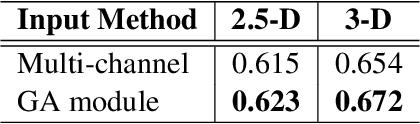
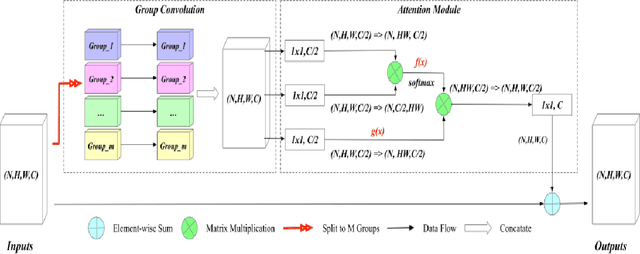

Early diagnosis of pulmonary nodules (PNs) can improve the survival rate of patients and yet is a challenging task for radiologists due to the image noise and artifacts in computed tomography (CT) images. In this paper, we propose a novel and effective abnormality detector implementing the attention mechanism and group convolution on 3D single-shot detector (SSD) called group-attention SSD (GA-SSD). We find that group convolution is effective in extracting rich context information between continuous slices, and attention network can learn the target features automatically. We collected a large-scale dataset that contained 4146 CT scans with annotations of varying types and sizes of PNs (even PNs smaller than 3mm were annotated). To the best of our knowledge, this dataset is the largest cohort with relatively complete annotations for PNs detection. Our experimental results show that the proposed group-attention SSD outperforms the classic SSD framework as well as the state-of-the-art 3DCNN, especially on some challenging lesion types.