 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples Are a Natural Consequence of Test Error in Noise
Jan 29, 2019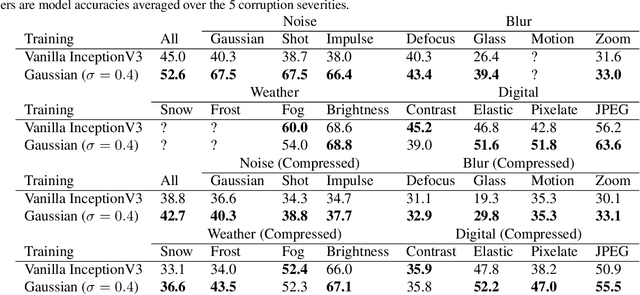
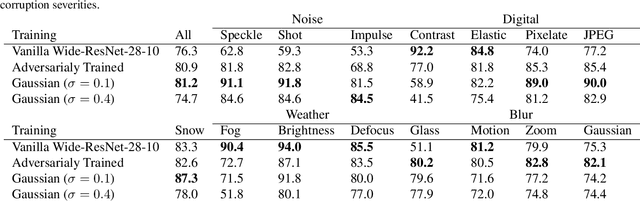
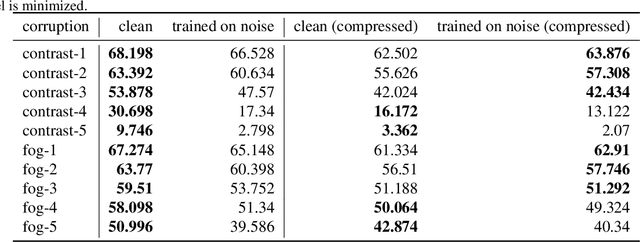
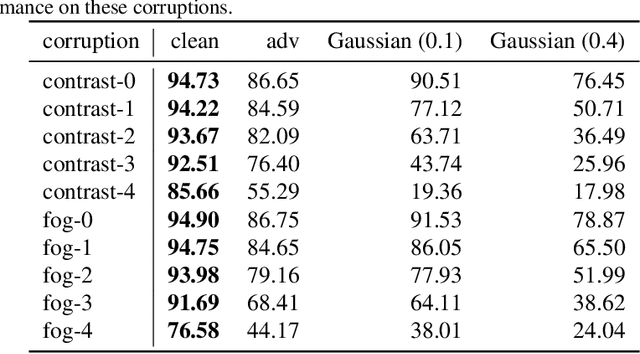
Over the last few years, the phenomenon of adversarial examples --- maliciously constructed inputs that fool trained machine learning models --- has captured the attention of the research community, especially when the adversary is restricted to small modifications of a correctly handled input. Less surprisingly, image classifiers also lack human-level performance on randomly corrupted images, such as images with additive Gaussian noise. In this paper we provide both empirical and theoretical evidence that these are two manifestations of the same underlying phenomenon, establishing close connections between the adversarial robustness and corruption robustness research programs. This suggests that improving adversarial robustness should go hand in hand with improving performance in the presence of more general and realistic image corruptions. Based on our results we recommend that future adversarial defenses consider evaluating the robustness of their methods to distributional shift with benchmarks such as Imagenet-C.
Sanity Checks for Saliency Maps
Oct 28, 2018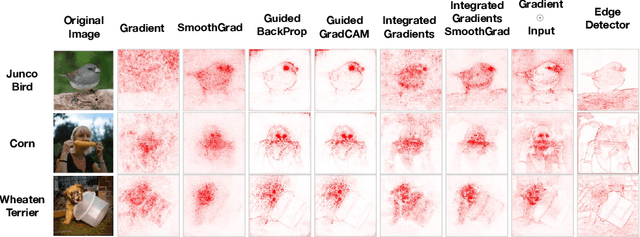
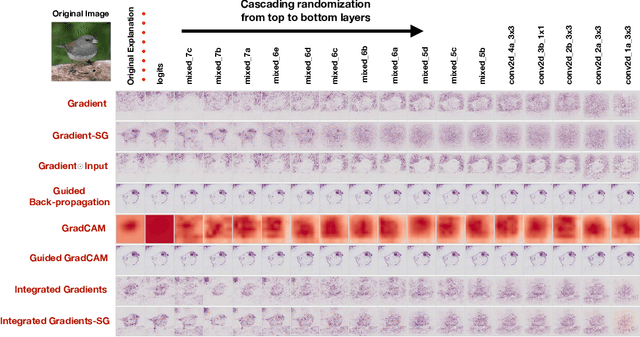
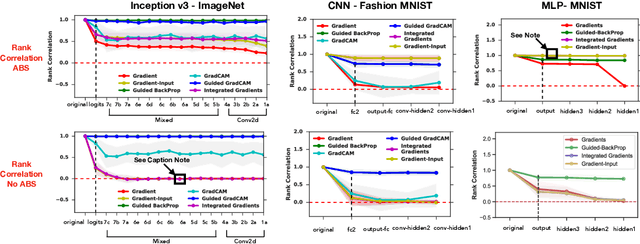
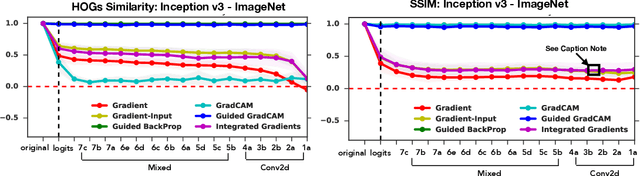
Saliency methods have emerged as a popular tool to highlight features in an input deemed relevant for the prediction of a learned model. Several saliency methods have been proposed, often guided by visual appeal on image data. In this work, we propose an actionable methodology to evaluate what kinds of explanations a given method can and cannot provide. We find that reliance, solely, on visual assessment can be misleading. Through extensive experiments we show that some existing saliency methods are independent both of the model and of the data generating process. Consequently, methods that fail the proposed tests are inadequate for tasks that are sensitive to either data or model, such as, finding outliers in the data, explaining the relationship between inputs and outputs that the model learned, and debugging the model. We interpret our findings through an analogy with edge detection in images, a technique that requires neither training data nor model. Theory in the case of a linear model and a single-layer convolutional neural network supports our experimental findings.
Relational inductive biases, deep learning, and graph networks
Oct 17, 2018
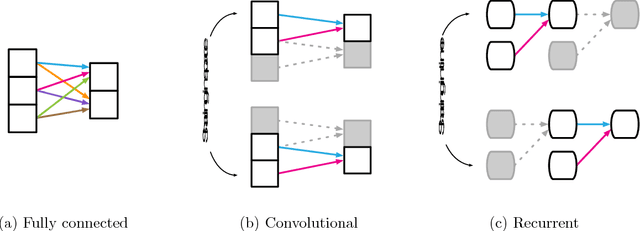
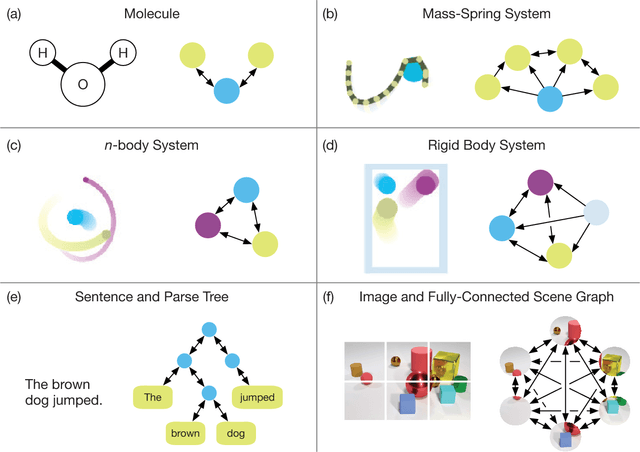
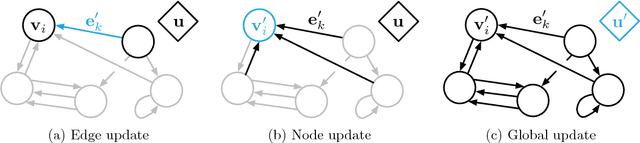
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.
Local Explanation Methods for Deep Neural Networks Lack Sensitivity to Parameter Values
Oct 08, 2018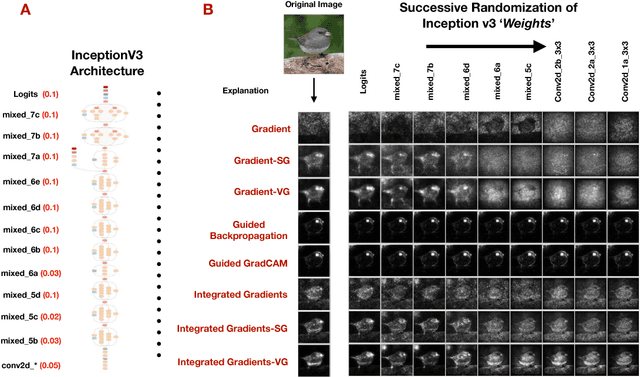
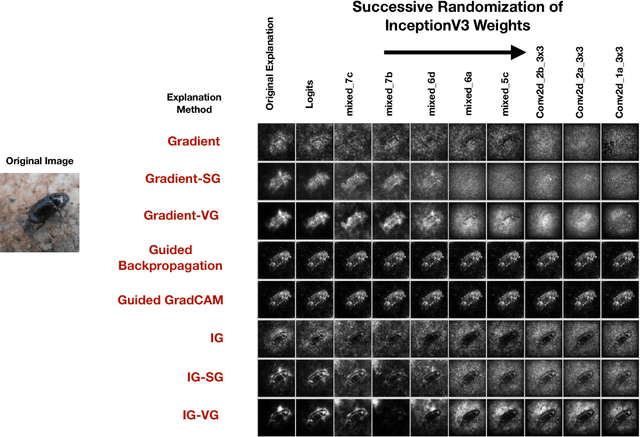
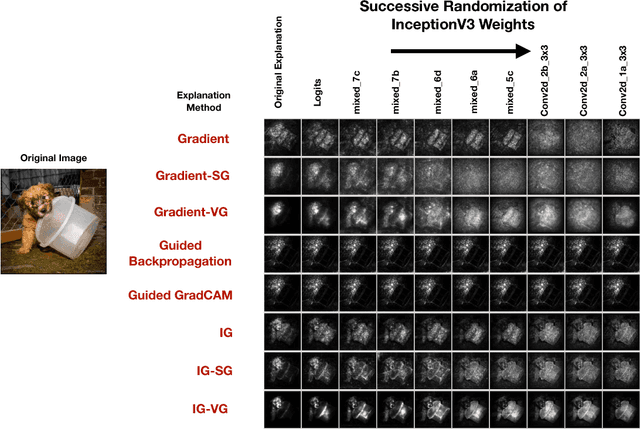
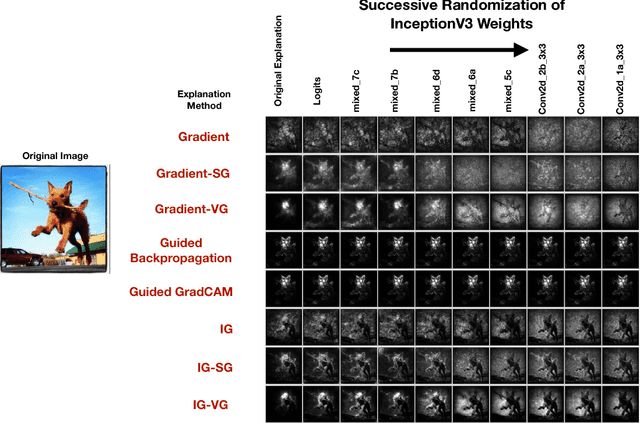
Explaining the output of a complicated machine learning model like a deep neural network (DNN) is a central challenge in machine learning. Several proposed local explanation methods address this issue by identifying what dimensions of a single input are most responsible for a DNN's output. The goal of this work is to assess the sensitivity of local explanations to DNN parameter values. Somewhat surprisingly, we find that DNNs with randomly-initialized weights produce explanations that are both visually and quantitatively similar to those produced by DNNs with learned weights. Our conjecture is that this phenomenon occurs because these explanations are dominated by the lower level features of a DNN, and that a DNN's architecture provides a strong prior which significantly affects the representations learned at these lower layers. NOTE: This work is now subsumed by our recent manuscript, Sanity Checks for Saliency Maps (to appear NIPS 2018), where we expand on findings and address concerns raised in Sundararajan et. al. (2018).
Adversarial Spheres
Sep 10, 2018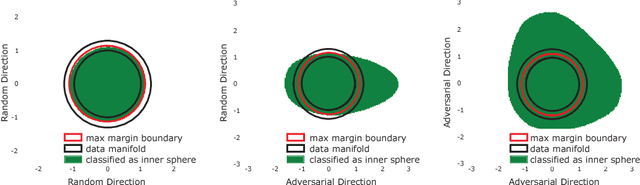
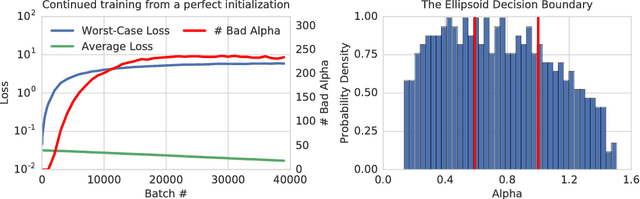
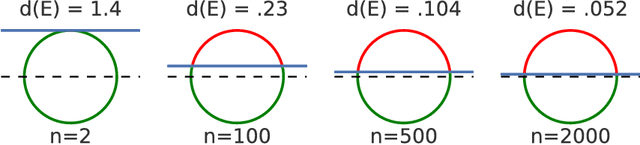
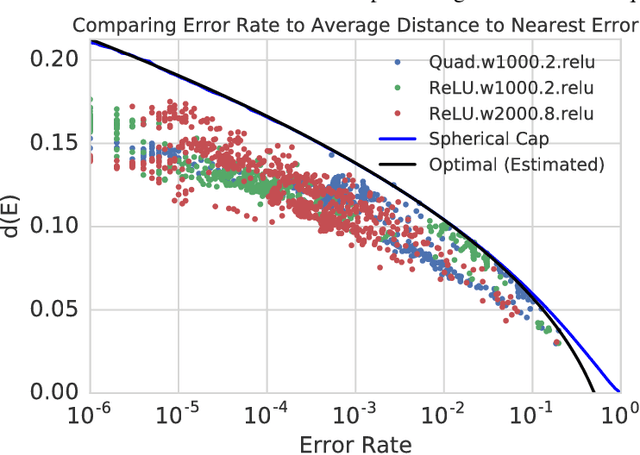
State of the art computer vision models have been shown to be vulnerable to small adversarial perturbations of the input. In other words, most images in the data distribution are both correctly classified by the model and are very close to a visually similar misclassified image. Despite substantial research interest, the cause of the phenomenon is still poorly understood and remains unsolved. We hypothesize that this counter intuitive behavior is a naturally occurring result of the high dimensional geometry of the data manifold. As a first step towards exploring this hypothesis, we study a simple synthetic dataset of classifying between two concentric high dimensional spheres. For this dataset we show a fundamental tradeoff between the amount of test error and the average distance to nearest error. In particular, we prove that any model which misclassifies a small constant fraction of a sphere will be vulnerable to adversarial perturbations of size $O(1/\sqrt{d})$. Surprisingly, when we train several different architectures on this dataset, all of their error sets naturally approach this theoretical bound. As a result of the theory, the vulnerability of neural networks to small adversarial perturbations is a logical consequence of the amount of test error observed. We hope that our theoretical analysis of this very simple case will point the way forward to explore how the geometry of complex real-world data sets leads to adversarial examples.
Motivating the Rules of the Game for Adversarial Example Research
Jul 20, 2018
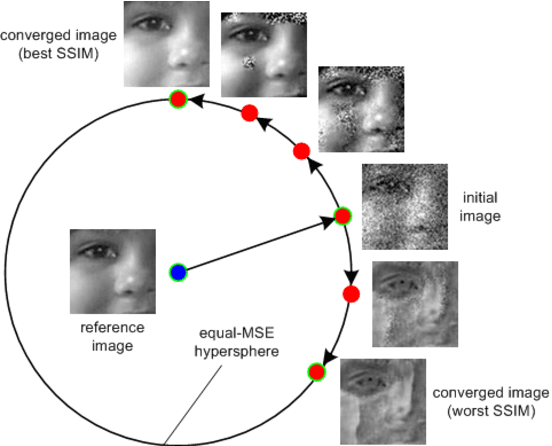

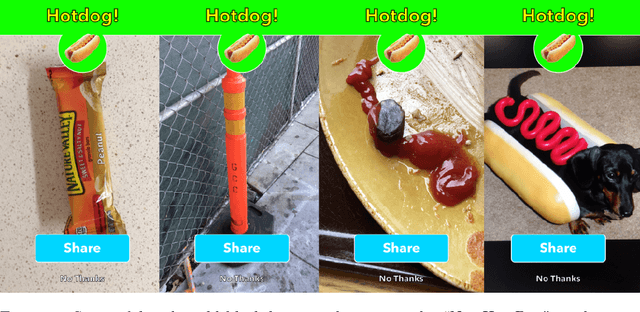
Advances in machine learning have led to broad deployment of systems with impressive performance on important problems. Nonetheless, these systems can be induced to make errors on data that are surprisingly similar to examples the learned system handles correctly. The existence of these errors raises a variety of questions about out-of-sample generalization and whether bad actors might use such examples to abuse deployed systems. As a result of these security concerns, there has been a flurry of recent papers proposing algorithms to defend against such malicious perturbations of correctly handled examples. It is unclear how such misclassifications represent a different kind of security problem than other errors, or even other attacker-produced examples that have no specific relationship to an uncorrupted input. In this paper, we argue that adversarial example defense papers have, to date, mostly considered abstract, toy games that do not relate to any specific security concern. Furthermore, defense papers have not yet precisely described all the abilities and limitations of attackers that would be relevant in practical security. Towards this end, we establish a taxonomy of motivations, constraints, and abilities for more plausible adversaries. Finally, we provide a series of recommendations outlining a path forward for future work to more clearly articulate the threat model and perform more meaningful evaluation.
Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV)
Jun 07, 2018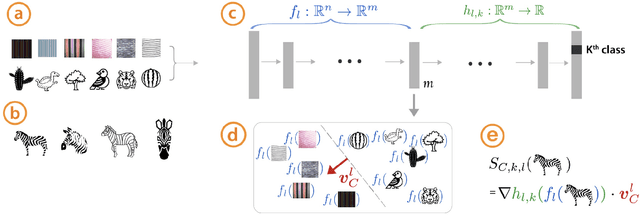


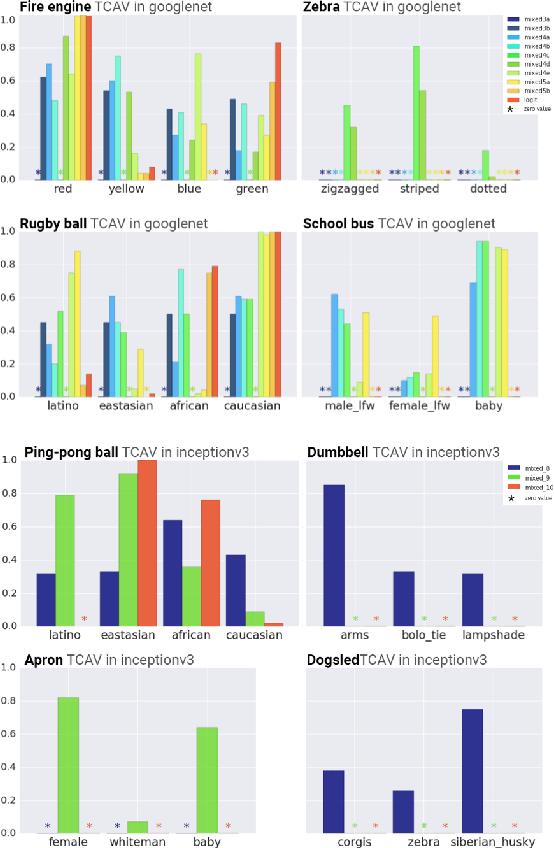
The interpretation of deep learning models is a challenge due to their size, complexity, and often opaque internal state. In addition, many systems, such as image classifiers, operate on low-level features rather than high-level concepts. To address these challenges, we introduce Concept Activation Vectors (CAVs), which provide an interpretation of a neural net's internal state in terms of human-friendly concepts. The key idea is to view the high-dimensional internal state of a neural net as an aid, not an obstacle. We show how to use CAVs as part of a technique, Testing with CAVs (TCAV), that uses directional derivatives to quantify the degree to which a user-defined concept is important to a classification result--for example, how sensitive a prediction of "zebra" is to the presence of stripes. Using the domain of image classification as a testing ground, we describe how CAVs may be used to explore hypotheses and generate insights for a standard image classification network as well as a medical application.
Adversarial Patch
May 17, 2018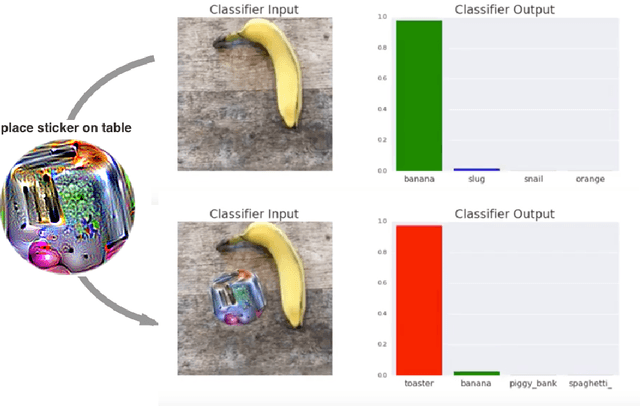

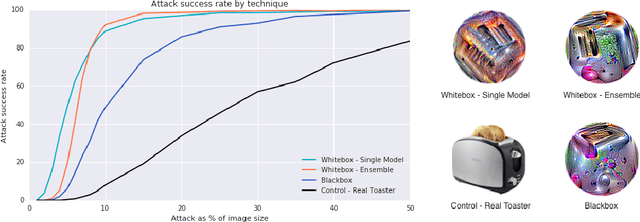
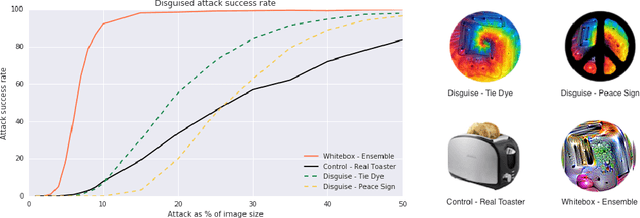
We present a method to create universal, robust, targeted adversarial image patches in the real world. The patches are universal because they can be used to attack any scene, robust because they work under a wide variety of transformations, and targeted because they can cause a classifier to output any target class. These adversarial patches can be printed, added to any scene, photographed, and presented to image classifiers; even when the patches are small, they cause the classifiers to ignore the other items in the scene and report a chosen target class. To reproduce the results from the paper, our code is available at https://github.com/tensorflow/cleverhans/tree/master/examples/adversarial_patch
SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability
Nov 08, 2017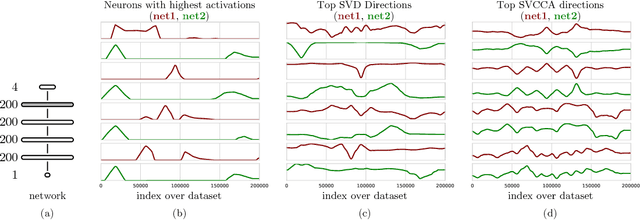
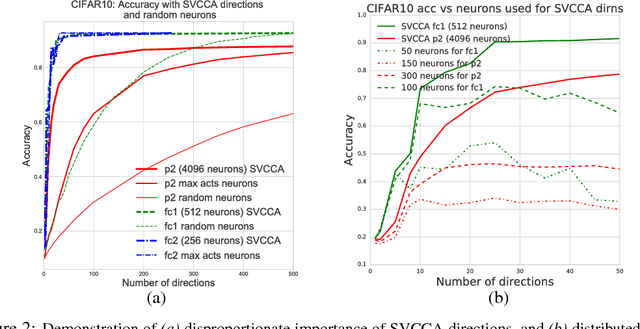
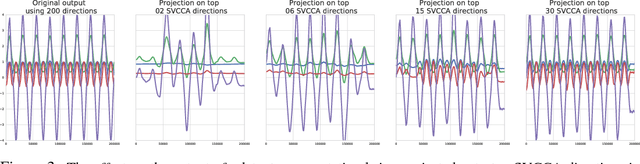

We propose a new technique, Singular Vector Canonical Correlation Analysis (SVCCA), a tool for quickly comparing two representations in a way that is both invariant to affine transform (allowing comparison between different layers and networks) and fast to compute (allowing more comparisons to be calculated than with previous methods). We deploy this tool to measure the intrinsic dimensionality of layers, showing in some cases needless over-parameterization; to probe learning dynamics throughout training, finding that networks converge to final representations from the bottom up; to show where class-specific information in networks is formed; and to suggest new training regimes that simultaneously save computation and overfit less. Code: https://github.com/google/svcca/
Neural Message Passing for Quantum Chemistry
Jun 12, 2017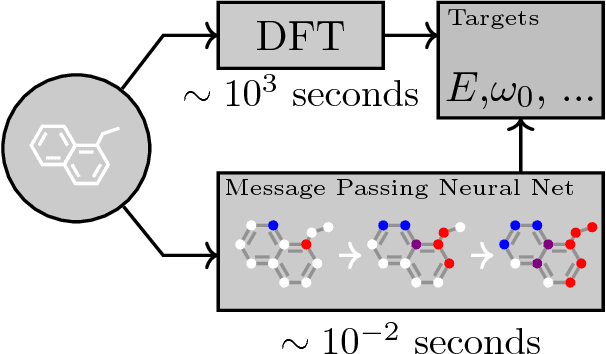

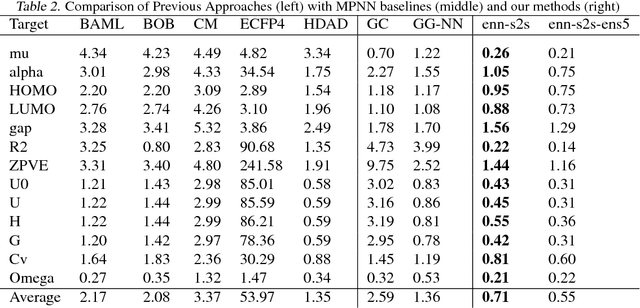
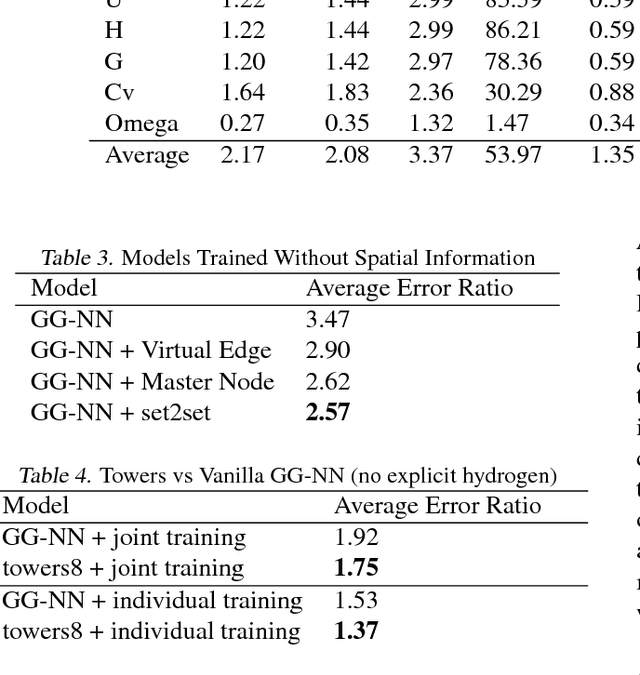
Supervised learning on molecules has incredible potential to be useful in chemistry, drug discovery, and materials science. Luckily, several promising and closely related neural network models invariant to molecular symmetries have already been described in the literature. These models learn a message passing algorithm and aggregation procedure to compute a function of their entire input graph. At this point, the next step is to find a particularly effective variant of this general approach and apply it to chemical prediction benchmarks until we either solve them or reach the limits of the approach. In this paper, we reformulate existing models into a single common framework we call Message Passing Neural Networks (MPNNs) and explore additional novel variations within this framework. Using MPNNs we demonstrate state of the art results on an important molecular property prediction benchmark; these results are strong enough that we believe future work should focus on datasets with larger molecules or more accurate ground truth labels.