 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoose Your Agent: Tradeoffs in Adopting AI Advisors, Coaches, and Delegates in Multi-Party Negotiation
Feb 13, 2026As AI usage becomes more prevalent in social contexts, understanding agent-user interaction is critical to designing systems that improve both individual and group outcomes. We present an online behavioral experiment (N = 243) in which participants play three multi-turn bargaining games in groups of three. Each game, presented in randomized order, grants access to a single LLM assistance modality: proactive recommendations from an Advisor, reactive feedback from a Coach, or autonomous execution by a Delegate; all modalities are powered by an underlying LLM that achieves superhuman performance in an all-agent environment. On each turn, participants privately decide whether to act manually or use the AI modality available in that game. Despite preferring the Advisor modality, participants achieve the highest mean individual gains with the Delegate, demonstrating a preference-performance misalignment. Moreover, delegation generates positive externalities; even non-adopting users in access-to-delegate treatment groups benefit by receiving higher-quality offers. Mechanism analysis reveals that the Delegate agent acts as a market maker, injecting rational, Pareto-improving proposals that restructure the trading environment. Our research reveals a gap between agent capabilities and realized group welfare. While autonomous agents can exhibit super-human strategic performance, their impact on realized welfare gains can be constrained by interfaces, user perceptions, and adoption barriers. Assistance modalities should be designed as mechanisms with endogenous participation; adoption-compatible interaction rules are a prerequisite to improving human welfare with automated assistance.
Understanding Economic Tradeoffs Between Human and AI Agents in Bargaining Games
Sep 11, 2025



Coordination tasks traditionally performed by humans are increasingly being delegated to autonomous agents. As this pattern progresses, it becomes critical to evaluate not only these agents' performance but also the processes through which they negotiate in dynamic, multi-agent environments. Furthermore, different agents exhibit distinct advantages: traditional statistical agents, such as Bayesian models, may excel under well-specified conditions, whereas large language models (LLMs) can generalize across contexts. In this work, we compare humans (N = 216), LLMs (GPT-4o, Gemini 1.5 Pro), and Bayesian agents in a dynamic negotiation setting that enables direct, identical-condition comparisons across populations, capturing both outcomes and behavioral dynamics. Bayesian agents extract the highest surplus through aggressive optimization, at the cost of frequent trade rejections. Humans and LLMs can achieve similar overall surplus, but through distinct behaviors: LLMs favor conservative, concessionary trades with few rejections, while humans employ more strategic, risk-taking, and fairness-oriented behaviors. Thus, we find that performance parity -- a common benchmark in agent evaluation -- can conceal fundamental differences in process and alignment, which are critical for practical deployment in real-world coordination tasks.
The Evolution of LLM Adoption in Industry Data Curation Practices
Dec 20, 2024



As large language models (LLMs) grow increasingly adept at processing unstructured text data, they offer new opportunities to enhance data curation workflows. This paper explores the evolution of LLM adoption among practitioners at a large technology company, evaluating the impact of LLMs in data curation tasks through participants' perceptions, integration strategies, and reported usage scenarios. Through a series of surveys, interviews, and user studies, we provide a timely snapshot of how organizations are navigating a pivotal moment in LLM evolution. In Q2 2023, we conducted a survey to assess LLM adoption in industry for development tasks (N=84), and facilitated expert interviews to assess evolving data needs (N=10) in Q3 2023. In Q2 2024, we explored practitioners' current and anticipated LLM usage through a user study involving two LLM-based prototypes (N=12). While each study addressed distinct research goals, they revealed a broader narrative about evolving LLM usage in aggregate. We discovered an emerging shift in data understanding from heuristic-first, bottom-up approaches to insights-first, top-down workflows supported by LLMs. Furthermore, to respond to a more complex data landscape, data practitioners now supplement traditional subject-expert-created 'golden datasets' with LLM-generated 'silver' datasets and rigorously validated 'super golden' datasets curated by diverse experts. This research sheds light on the transformative role of LLMs in large-scale analysis of unstructured data and highlights opportunities for further tool development.
ConstitutionalExperts: Training a Mixture of Principle-based Prompts
Mar 07, 2024



Large language models (LLMs) are highly capable at a variety of tasks given the right prompt, but writing one is still a difficult and tedious process. In this work, we introduce ConstitutionalExperts, a method for learning a prompt consisting of constitutional principles (i.e. rules), given a training dataset. Unlike prior methods that optimize the prompt as a single entity, our method incrementally improves the prompt by surgically editing individual principles. We also show that we can improve overall performance by learning unique prompts for different semantic regions of the training data and using a mixture-of-experts (MoE) architecture to route inputs at inference time. We compare our method to other state of the art prompt-optimization techniques across six benchmark datasets. We also investigate whether MoE improves these other techniques. Our results suggest that ConstitutionalExperts outperforms other prompt optimization techniques by 10.9% (F1) and that mixture-of-experts improves all techniques, suggesting its broad applicability.
Automatic Histograms: Leveraging Language Models for Text Dataset Exploration
Feb 21, 2024Making sense of unstructured text datasets is perennially difficult, yet increasingly relevant with Large Language Models. Data workers often rely on dataset summaries, especially distributions of various derived features. Some features, like toxicity or topics, are relevant to many datasets, but many interesting features are domain specific: instruments and genres for a music dataset, or diseases and symptoms for a medical dataset. Accordingly, data workers often run custom analyses for each dataset, which is cumbersome and difficult. We present AutoHistograms, a visualization tool leveragingLLMs. AutoHistograms automatically identifies relevant features, visualizes them with histograms, and allows the user to interactively query the dataset for categories of entities and create new histograms. In a user study with 10 data workers (n=10), we observe that participants can quickly identify insights and explore the data using AutoHistograms, and conceptualize a broad range of applicable use cases. Together, this tool and user study contributeto the growing field of LLM-assisted sensemaking tools.
LLM Comparator: Visual Analytics for Side-by-Side Evaluation of Large Language Models
Feb 16, 2024


Automatic side-by-side evaluation has emerged as a promising approach to evaluating the quality of responses from large language models (LLMs). However, analyzing the results from this evaluation approach raises scalability and interpretability challenges. In this paper, we present LLM Comparator, a novel visual analytics tool for interactively analyzing results from automatic side-by-side evaluation. The tool supports interactive workflows for users to understand when and why a model performs better or worse than a baseline model, and how the responses from two models are qualitatively different. We iteratively designed and developed the tool by closely working with researchers and engineers at a large technology company. This paper details the user challenges we identified, the design and development of the tool, and an observational study with participants who regularly evaluate their models.
ConstitutionMaker: Interactively Critiquing Large Language Models by Converting Feedback into Principles
Oct 24, 2023



Large language model (LLM) prompting is a promising new approach for users to create and customize their own chatbots. However, current methods for steering a chatbot's outputs, such as prompt engineering and fine-tuning, do not support users in converting their natural feedback on the model's outputs to changes in the prompt or model. In this work, we explore how to enable users to interactively refine model outputs through their feedback, by helping them convert their feedback into a set of principles (i.e. a constitution) that dictate the model's behavior. From a formative study, we (1) found that users needed support converting their feedback into principles for the chatbot and (2) classified the different principle types desired by users. Inspired by these findings, we developed ConstitutionMaker, an interactive tool for converting user feedback into principles, to steer LLM-based chatbots. With ConstitutionMaker, users can provide either positive or negative feedback in natural language, select auto-generated feedback, or rewrite the chatbot's response; each mode of feedback automatically generates a principle that is inserted into the chatbot's prompt. In a user study with 14 participants, we compare ConstitutionMaker to an ablated version, where users write their own principles. With ConstitutionMaker, participants felt that their principles could better guide the chatbot, that they could more easily convert their feedback into principles, and that they could write principles more efficiently, with less mental demand. ConstitutionMaker helped users identify ways to improve the chatbot, formulate their intuitive responses to the model into feedback, and convert this feedback into specific and clear principles. Together, these findings inform future tools that support the interactive critiquing of LLM outputs.
Analyzing a Caching Model
Dec 13, 2021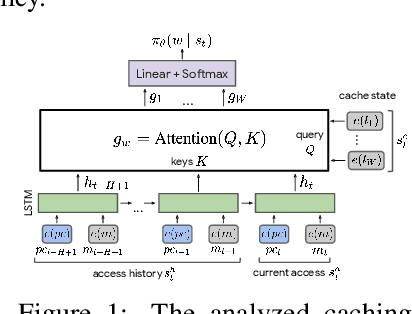

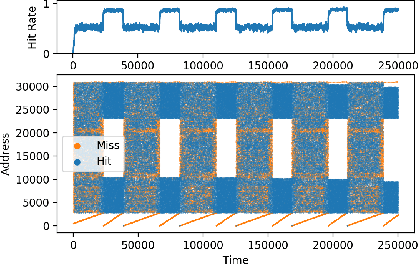
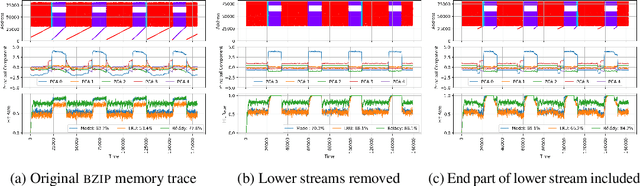
Machine Learning has been successfully applied in systems applications such as memory prefetching and caching, where learned models have been shown to outperform heuristics. However, the lack of understanding the inner workings of these models -- interpretability -- remains a major obstacle for adoption in real-world deployments. Understanding a model's behavior can help system administrators and developers gain confidence in the model, understand risks, and debug unexpected behavior in production. Interpretability for models used in computer systems poses a particular challenge: Unlike ML models trained on images or text, the input domain (e.g., memory access patterns, program counters) is not immediately interpretable. A major challenge is therefore to explain the model in terms of concepts that are approachable to a human practitioner. By analyzing a state-of-the-art caching model, we provide evidence that the model has learned concepts beyond simple statistics that can be leveraged for explanations. Our work provides a first step towards explanability of system ML models and highlights both promises and challenges of this emerging research area.
Best of both worlds: local and global explanations with human-understandable concepts
Jun 16, 2021



Interpretability techniques aim to provide the rationale behind a model's decision, typically by explaining either an individual prediction (local explanation, e.g. `why is this patient diagnosed with this condition') or a class of predictions (global explanation, e.g. `why are patients diagnosed with this condition in general'). While there are many methods focused on either one, few frameworks can provide both local and global explanations in a consistent manner. In this work, we combine two powerful existing techniques, one local (Integrated Gradients, IG) and one global (Testing with Concept Activation Vectors), to provide local, and global concept-based explanations. We first validate our idea using two synthetic datasets with a known ground truth, and further demonstrate with a benchmark natural image dataset. We test our method with various concepts, target classes, model architectures and IG baselines. We show that our method improves global explanations over TCAV when compared to ground truth, and provides useful insights. We hope our work provides a step towards building bridges between many existing local and global methods to get the best of both worlds.
The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models
Aug 12, 2020



We present the Language Interpretability Tool (LIT), an open-source platform for visualization and understanding of NLP models. We focus on core questions about model behavior: Why did my model make this prediction? When does it perform poorly? What happens under a controlled change in the input? LIT integrates local explanations, aggregate analysis, and counterfactual generation into a streamlined, browser-based interface to enable rapid exploration and error analysis. We include case studies for a diverse set of workflows, including exploring counterfactuals for sentiment analysis, measuring gender bias in coreference systems, and exploring local behavior in text generation. LIT supports a wide range of models--including classification, seq2seq, and structured prediction--and is highly extensible through a declarative, framework-agnostic API. LIT is under active development, with code and full documentation available at https://github.com/pair-code/lit.