 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuGER$^2$: Multi-Granularity Evidence Retrieval and Reasoning for Hybrid Question Answering
Oct 19, 2022
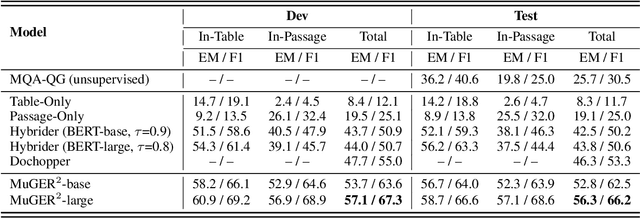
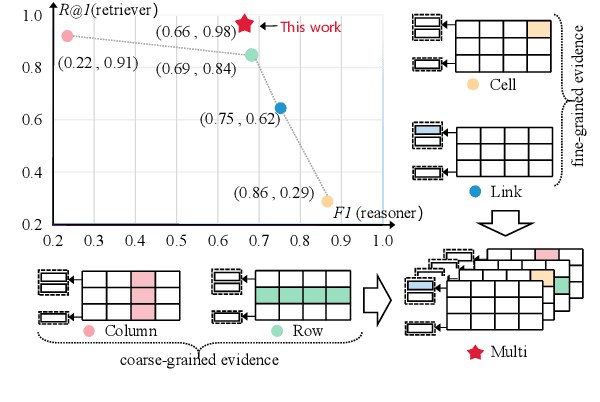
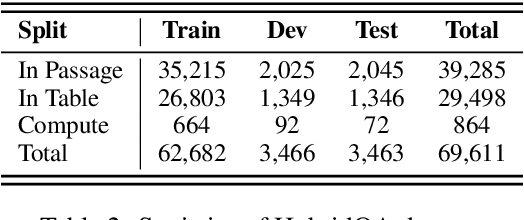
Hybrid question answering (HQA) aims to answer questions over heterogeneous data, including tables and passages linked to table cells. The heterogeneous data can provide different granularity evidence to HQA models, e.t., column, row, cell, and link. Conventional HQA models usually retrieve coarse- or fine-grained evidence to reason the answer. Through comparison, we find that coarse-grained evidence is easier to retrieve but contributes less to the reasoner, while fine-grained evidence is the opposite. To preserve the advantage and eliminate the disadvantage of different granularity evidence, we propose MuGER$^2$, a Multi-Granularity Evidence Retrieval and Reasoning approach. In evidence retrieval, a unified retriever is designed to learn the multi-granularity evidence from the heterogeneous data. In answer reasoning, an evidence selector is proposed to navigate the fine-grained evidence for the answer reader based on the learned multi-granularity evidence. Experiment results on the HybridQA dataset show that MuGER$^2$ significantly boosts the HQA performance. Further ablation analysis verifies the effectiveness of both the retrieval and reasoning designs.
Mars: Semantic-aware Contrastive Learning for End-to-End Task-Oriented Dialog
Oct 17, 2022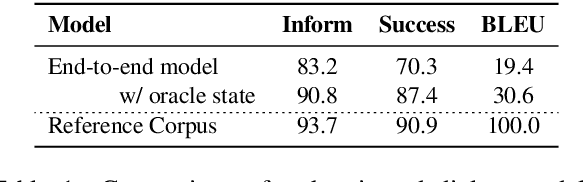
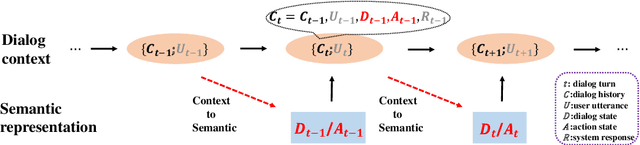
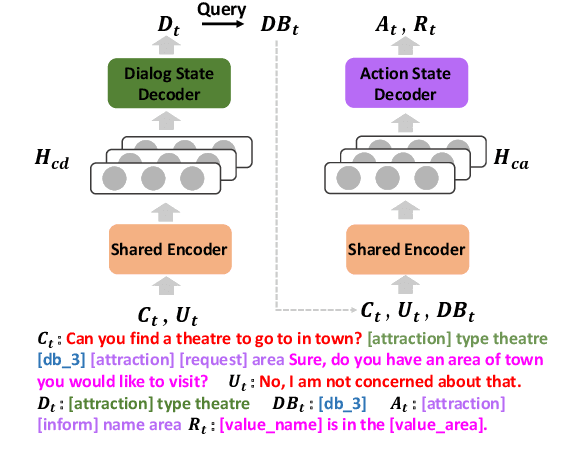
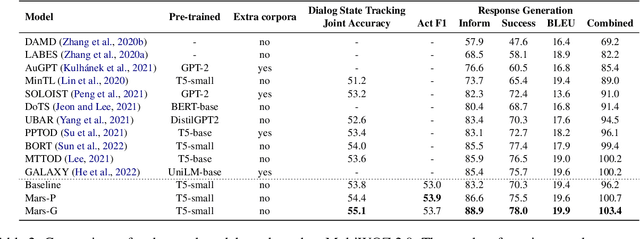
Traditional end-to-end task-oriented dialog systems first convert dialog context into dialog state and action state, before generating the system response. In this paper, we first empirically investigate the relationship between dialog/action state and generated system response. The empirical exploration shows that the system response performance is significantly affected by the quality of dialog state and action state. Based on these findings, we argue that enhancing the relationship modeling between dialog context and dialog/action state is beneficial to improving the quality of the dialog state and action state, which further improves the generated response quality. Therefore, we propose Mars, an end-to-end task-oriented dialog system with semantic-aware contrastive learning strategies to model the relationship between dialog context and dialog/action state. Empirical results show our proposed Mars achieves state-of-the-art performance on the MultiWOZ 2.0, CamRest676, and CrossWOZ.
UniRPG: Unified Discrete Reasoning over Table and Text as Program Generation
Oct 15, 2022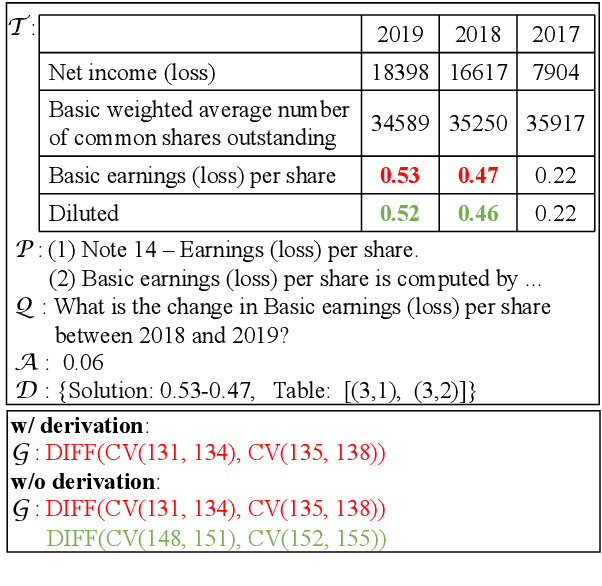
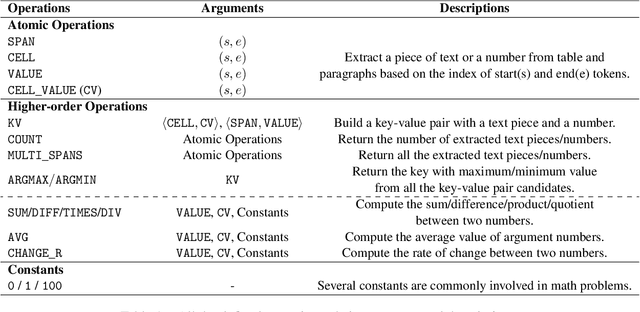
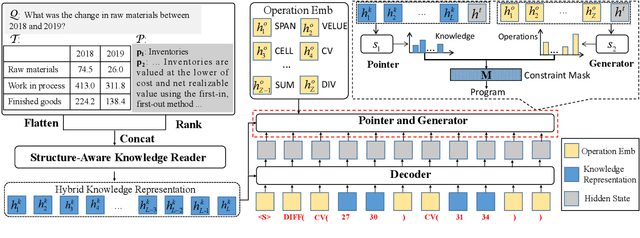
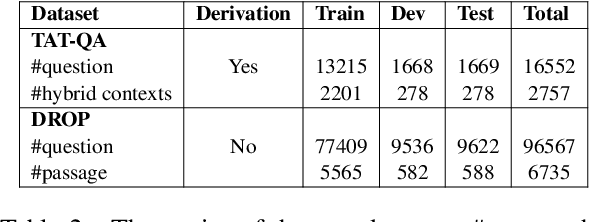
Question answering requiring discrete reasoning, e.g., arithmetic computing, comparison, and counting, over knowledge is a challenging task. In this paper, we propose UniRPG, a semantic-parsing-based approach advanced in interpretability and scalability, to perform unified discrete reasoning over heterogeneous knowledge resources, i.e., table and text, as program generation. Concretely, UniRPG consists of a neural programmer and a symbolic program executor, where a program is the composition of a set of pre-defined general atomic and higher-order operations and arguments extracted from table and text. First, the programmer parses a question into a program by generating operations and copying arguments, and then the executor derives answers from table and text based on the program. To alleviate the costly program annotation issue, we design a distant supervision approach for programmer learning, where pseudo programs are automatically constructed without annotated derivations. Extensive experiments on the TAT-QA dataset show that UniRPG achieves tremendous improvements and enhances interpretability and scalability compared with state-of-the-art methods, even without derivation annotation. Moreover, it achieves promising performance on the textual dataset DROP without derivations.
CSS: Combining Self-training and Self-supervised Learning for Few-shot Dialogue State Tracking
Oct 11, 2022
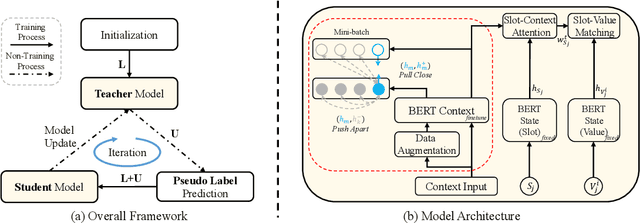
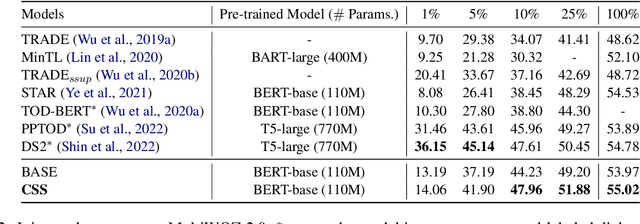
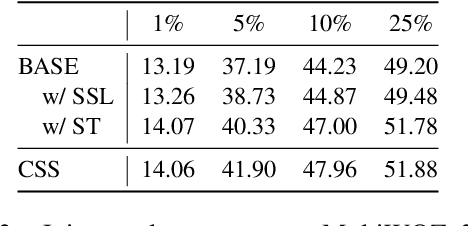
Few-shot dialogue state tracking (DST) is a realistic problem that trains the DST model with limited labeled data. Existing few-shot methods mainly transfer knowledge learned from external labeled dialogue data (e.g., from question answering, dialogue summarization, machine reading comprehension tasks, etc.) into DST, whereas collecting a large amount of external labeled data is laborious, and the external data may not effectively contribute to the DST-specific task. In this paper, we propose a few-shot DST framework called CSS, which Combines Self-training and Self-supervised learning methods. The unlabeled data of the DST task is incorporated into the self-training iterations, where the pseudo labels are predicted by a DST model trained on limited labeled data in advance. Besides, a contrastive self-supervised method is used to learn better representations, where the data is augmented by the dropout operation to train the model. Experimental results on the MultiWOZ dataset show that our proposed CSS achieves competitive performance in several few-shot scenarios.
Channel Modeling for UAV-to-Ground Communications with Posture Variation and Fuselage Scattering Effect
Oct 11, 2022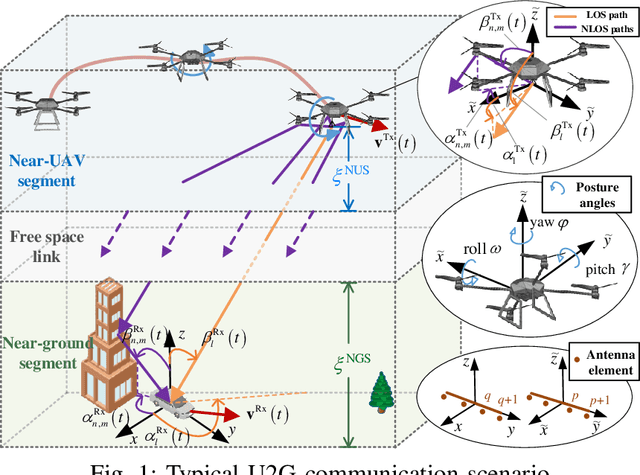
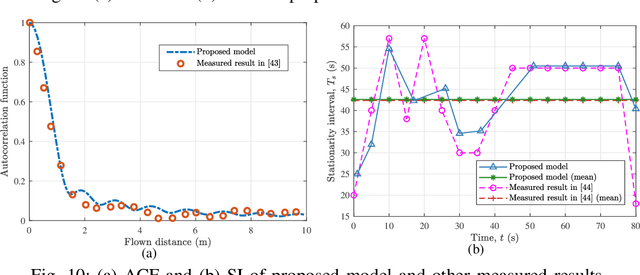
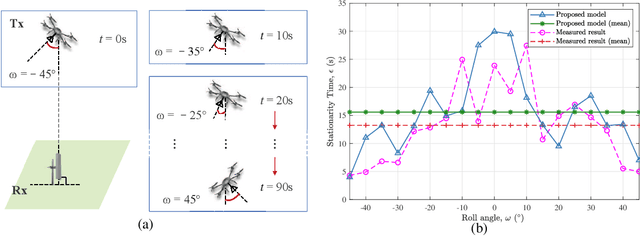
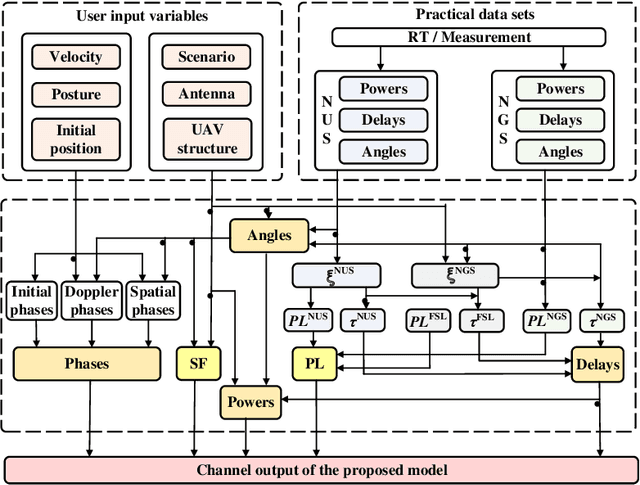
Unmanned aerial vehicle (UAV)-to-ground (U2G) channel models play a pivotal role for reliable communications between UAV and ground terminal. This paper proposes a three-dimensional (3D) non-stationary hybrid model including both large-scale and small-scale fading for U2G multiple-input-multiple-output (MIMO) channels. Distinctive channel characteristics under U2G scenarios, i.e., 3D trajectory and posture of UAV, fuselage scattering effect (FSE), and posture variation fading (PVF), are incorporated into the proposed model. The channel parameters, i.e., path loss (PL), shadow fading (SF), path delay, and path angle, are generated incorporating machine learning (ML) and ray tracing (RT) techniques to capture the structure-related characteristics. In order to guarantee the physical continuity of channel parameters such as Doppler phase and path power, the time evolution methods of inter- and intra- stationary intervals are proposed. Key statistical properties , i.e., temporal autocorrection function (ACF), power delay profile (PDP), level crossing rate (LCR), average fading duration (AFD), and stationary interval (SI) are given, and the impact of the change of fuselage and posture variation is analyzed. It is demonstrated that both posture variation and fuselage scattering have crucial effects on channel characteristics. The validity and practicability of the proposed model are verified by comparing the simulation results with the measured ones.
A Realistic 3D Non-Stationary Channel Model for UAV-to-Vehicle Communications Incorporating Fuselage Posture
Sep 19, 2022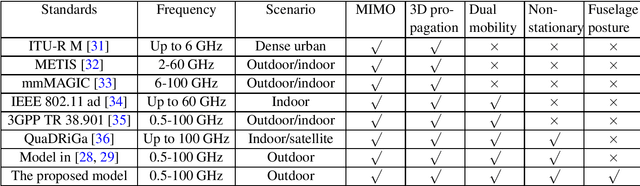
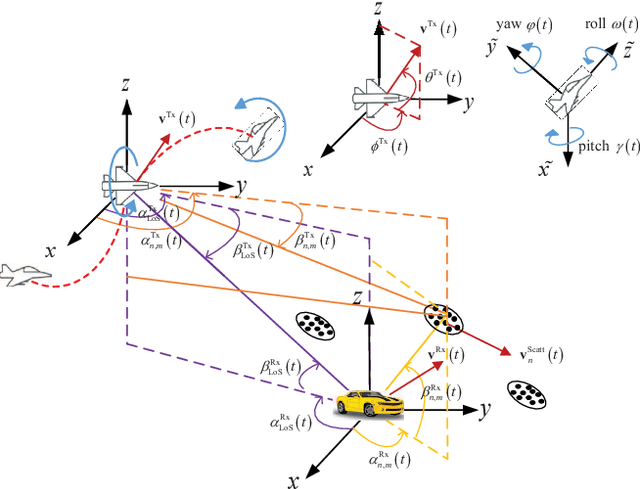
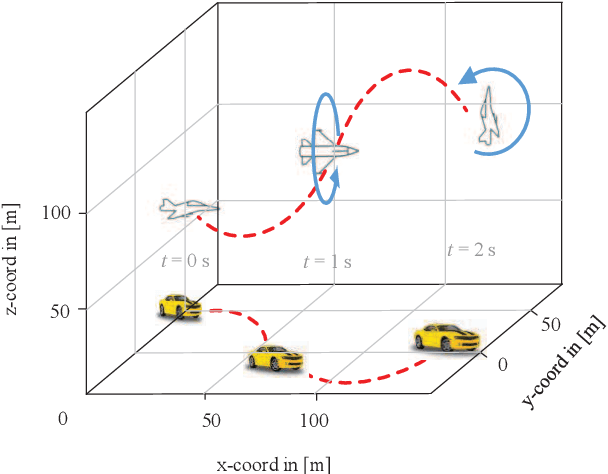
Considering the unmanned aerial vehicle (UAV) three-dimensional (3D) posture, a novel 3D non-stationary geometry-based stochastic model (GBSM) is proposed for multiple-input multiple-output (MIMO) UAV-to-vehicle (U2V) channels. It consists of a line-of-sight (LoS) and non-line-of-sight (NLoS) components. The factor of fuselage posture is considered by introducing a time-variant 3D posture matrix. Some important statistical properties, i.e. the temporal autocorrelation function (ACF) and spatial cross correlation function (CCF), are derived and investigated. Simulation results show that the fuselage posture has significant impact on the U2V channel characteristic and aggravate the non-stationarity. The agreements between analytical, simulated, and measured results verify the correctness of proposed model and derivations. Moreover, it is demonstrated that the proposed model is also compatible to the existing GBSM without considering fuselage posture.
AutoQGS: Auto-Prompt for Low-Resource Knowledge-based Question Generation from SPARQL
Aug 26, 2022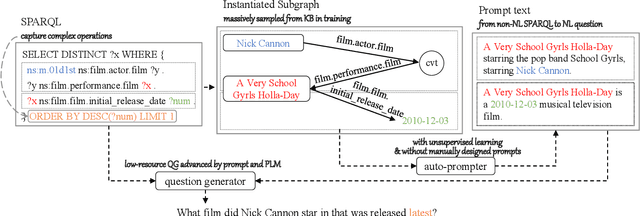
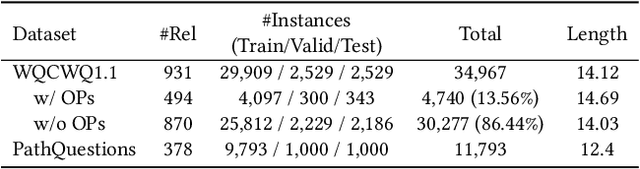
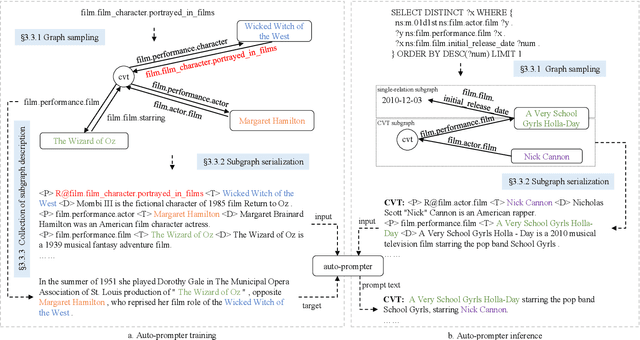
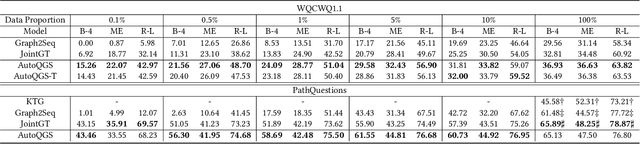
This study investigates the task of knowledge-based question generation (KBQG). Conventional KBQG works generated questions from fact triples in the knowledge graph, which could not express complex operations like aggregation and comparison in SPARQL. Moreover, due to the costly annotation of large-scale SPARQL-question pairs, KBQG from SPARQL under low-resource scenarios urgently needs to be explored. Recently, since the generative pre-trained language models (PLMs) typically trained in natural language (NL)-to-NL paradigm have been proven effective for low-resource generation, e.g., T5 and BART, how to effectively utilize them to generate NL-question from non-NL SPARQL is challenging. To address these challenges, AutoQGS, an auto-prompt approach for low-resource KBQG from SPARQL, is proposed. Firstly, we put forward to generate questions directly from SPARQL for the KBQG task to handle complex operations. Secondly, we propose an auto-prompter trained on large-scale unsupervised data to rephrase SPARQL into NL description, smoothing the low-resource transformation from non-NL SPARQL to NL question with PLMs. Experimental results on the WebQuestionsSP, ComlexWebQuestions 1.1, and PathQuestions show that our model achieves state-of-the-art performance, especially in low-resource settings. Furthermore, a corpus of 330k factoid complex question-SPARQL pairs is generated for further KBQG research.
Composable Text Control Operations in Latent Space with Ordinary Differential Equations
Aug 01, 2022


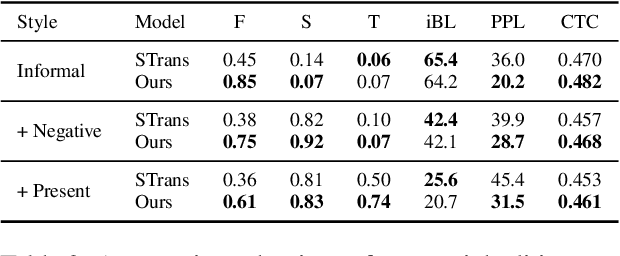
Real-world text applications often involve composing a wide range of text control operations, such as editing the text w.r.t. an attribute, manipulating keywords and structure, and generating new text of desired properties. Prior work typically learns/finetunes a language model (LM) to perform individual or specific subsets of operations. Recent research has studied combining operations in a plug-and-play manner, often with costly search or optimization in the complex sequence space. This paper proposes a new efficient approach for composable text operations in the compact latent space of text. The low-dimensionality and differentiability of the text latent vector allow us to develop an efficient sampler based on ordinary differential equations (ODEs) given arbitrary plug-in operators (e.g., attribute classifiers). By connecting pretrained LMs (e.g., GPT2) to the latent space through efficient adaption, we then decode the sampled vectors into desired text sequences. The flexible approach permits diverse control operators (sentiment, tense, formality, keywords, etc.) acquired using any relevant data from different domains. Experiments show that composing those operators within our approach manages to generate or edit high-quality text, substantially improving over previous methods in terms of generation quality and efficiency.
LUNA: Learning Slot-Turn Alignment for Dialogue State Tracking
May 05, 2022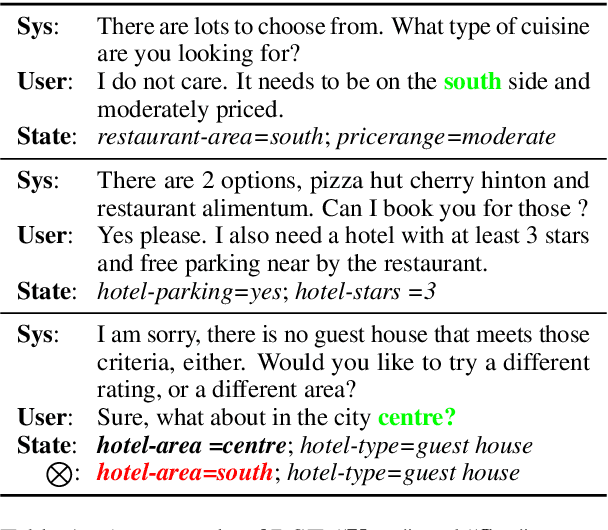
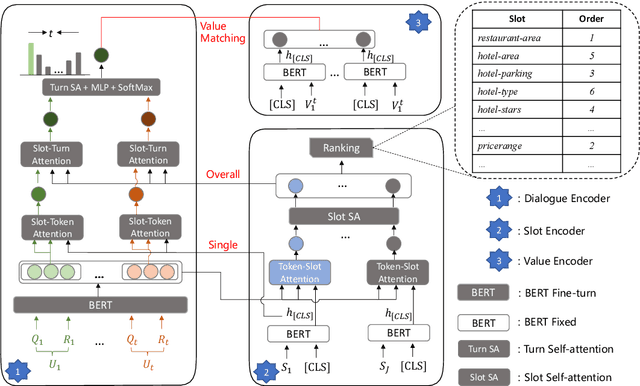
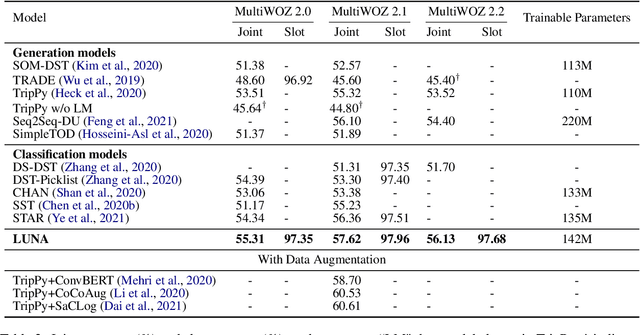
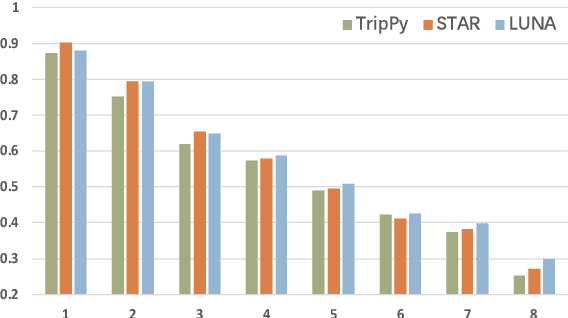
Dialogue state tracking (DST) aims to predict the current dialogue state given the dialogue history. Existing methods generally exploit the utterances of all dialogue turns to assign value for each slot. This could lead to suboptimal results due to the information introduced from irrelevant utterances in the dialogue history, which may be useless and can even cause confusion. To address this problem, we propose LUNA, a sLot-tUrN Alignment enhanced approach. It first explicitly aligns each slot with its most relevant utterance, then further predicts the corresponding value based on this aligned utterance instead of all dialogue utterances. Furthermore, we design a slot ranking auxiliary task to learn the temporal correlation among slots which could facilitate the alignment. Comprehensive experiments are conducted on multi-domain task-oriented dialogue datasets, i.e., MultiWOZ 2.0, MultiWOZ 2.1, and MultiWOZ 2.2. The results show that LUNA achieves new state-of-the-art results on these datasets.
BORT: Back and Denoising Reconstruction for End-to-End Task-Oriented Dialog
May 05, 2022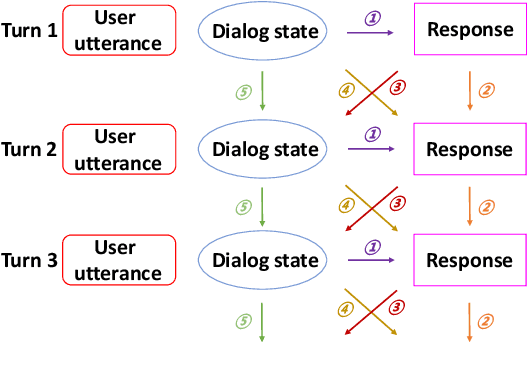
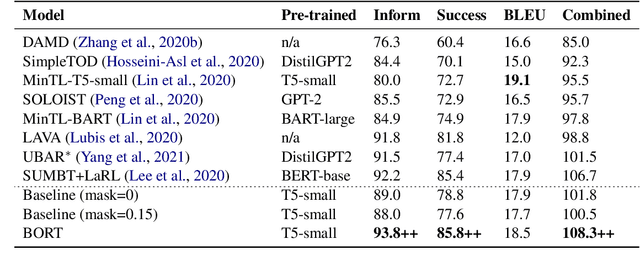
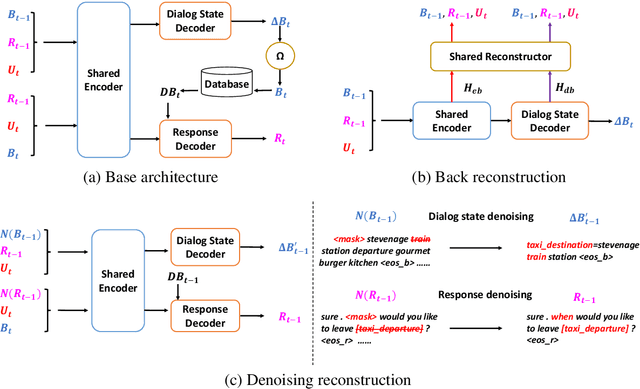
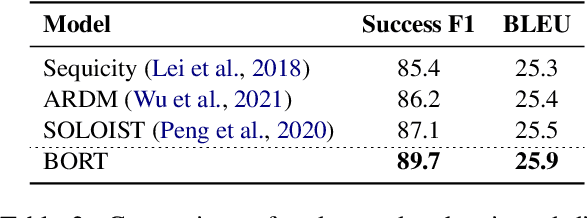
A typical end-to-end task-oriented dialog system transfers context into dialog state, and upon which generates a response, which usually faces the problem of error propagation from both previously generated inaccurate dialog states and responses, especially in low-resource scenarios. To alleviate these issues, we propose BORT, a back and denoising reconstruction approach for end-to-end task-oriented dialog system. Squarely, to improve the accuracy of dialog states, back reconstruction is used to reconstruct the original input context from the generated dialog states since inaccurate dialog states cannot recover the corresponding input context. To enhance the denoising capability of the model to reduce the impact of error propagation, denoising reconstruction is used to reconstruct the corrupted dialog state and response. Extensive experiments conducted on MultiWOZ 2.0 and CamRest676 show the effectiveness of BORT. Furthermore, BORT demonstrates its advanced capabilities in the zero-shot domain and low-resource scenarios.