 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
Hölder Policy Optimisation
May 12, 2026Group Relative Policy Optimisation (GRPO) enhances large language models by estimating advantages across a group of sampled trajectories. However, mapping these trajectory-level advantages to policy updates requires aggregating token-level probabilities within each sequence. Relying on a fixed aggregation mechanism for this step fundamentally limits the algorithm's adaptability. Empirically, we observe a critical trade-off: certain fixed aggregations frequently suffer from training collapse, while others fail to yield satisfactory performance. To resolve this, we propose \textbf{HölderPO}, a generalised policy optimisation framework unifying token-level probability aggregation via the Hölder mean. By explicitly modulating the parameter $p$, our framework provides continuous control over the trade-off between gradient concentration and variance bounds. Theoretically, we prove that a larger $p$ concentrates the gradient to amplify sparse learning signals, whereas a smaller $p$ strictly bounds gradient variance. Because no static configuration can universally resolve this concentration-stability trade-off, we instantiate the framework with a dynamic annealing algorithm that progressively schedules $p$ across the training lifecycle. Extensive evaluations demonstrate superior stability and convergence over existing baselines. Specifically, our approach achieves a state-of-the-art average accuracy of $54.9\%$ across multiple mathematical benchmarks, yielding a substantial $7.2\%$ relative gain over standard GRPO and secures an exceptional $93.8\%$ success rate on ALFWorld.
AcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Neural Machine Translation with Dynamic Graph Convolutional Decoder
May 28, 2023



Existing wisdom demonstrates the significance of syntactic knowledge for the improvement of neural machine translation models. However, most previous works merely focus on leveraging the source syntax in the well-known encoder-decoder framework. In sharp contrast, this paper proposes an end-to-end translation architecture from the (graph \& sequence) structural inputs to the (graph \& sequence) outputs, where the target translation and its corresponding syntactic graph are jointly modeled and generated. We propose a customized Dynamic Spatial-Temporal Graph Convolutional Decoder (Dyn-STGCD), which is designed for consuming source feature representations and their syntactic graph, and auto-regressively generating the target syntactic graph and tokens simultaneously. We conduct extensive experiments on five widely acknowledged translation benchmarks, verifying that our proposal achieves consistent improvements over baselines and other syntax-aware variants.
HHF: Hashing-guided Hinge Function for Deep Hashing Retrieval
Dec 04, 2021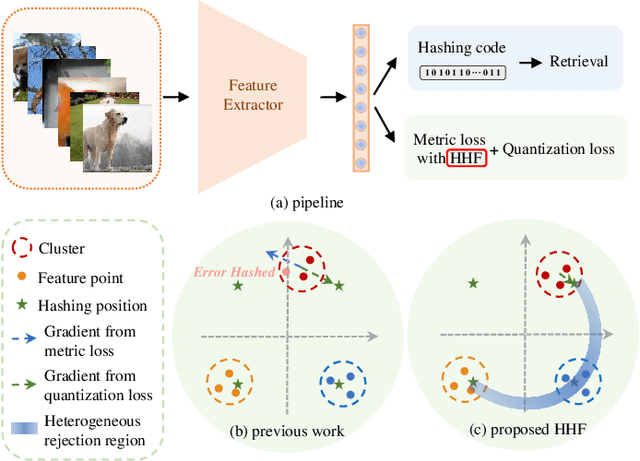

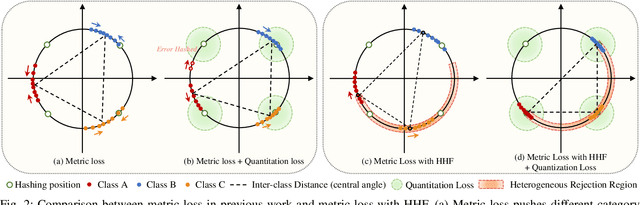
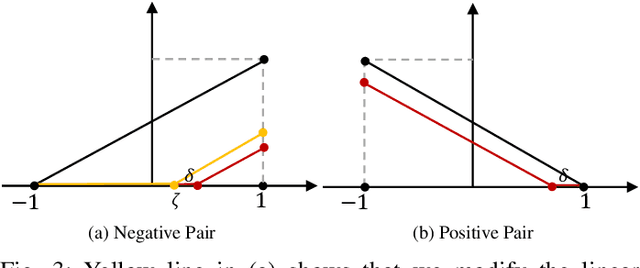
Deep hashing has shown promising performance in large-scale image retrieval. However, latent codes extracted by \textbf{D}eep \textbf{N}eural \textbf{N}etwork (DNN) will inevitably lose semantic information during the binarization process, which damages the retrieval efficiency and make it challenging. Although many existing approaches perform regularization to alleviate quantization errors, we figure out an incompatible conflict between the metric and quantization losses. The metric loss penalizes the inter-class distances to push different classes unconstrained far away. Worse still, it tends to map the latent code deviate from ideal binarization point and generate severe ambiguity in the binarization process. Based on the minimum distance of the binary linear code, \textbf{H}ashing-guided \textbf{H}inge \textbf{F}unction (HHF) is proposed to avoid such conflict. In detail, we carefully design a specific inflection point, which relies on the hash bit length and category numbers to balance metric learning and quantization learning. Such a modification prevents the network from falling into local metric optimal minima in deep hashing. Extensive experiments in CIFAR-10, CIFAR-100, ImageNet, and MS-COCO show that HHF consistently outperforms existing techniques, and is robust and flexible to transplant into other methods.
Acoustic anomaly detection via latent regularized gaussian mixture generative adversarial networks
Feb 05, 2020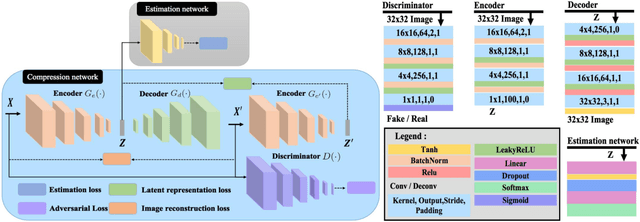
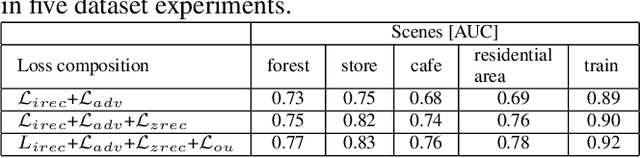
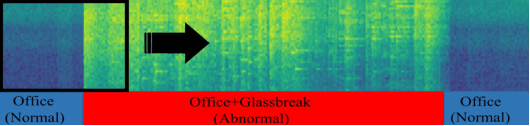
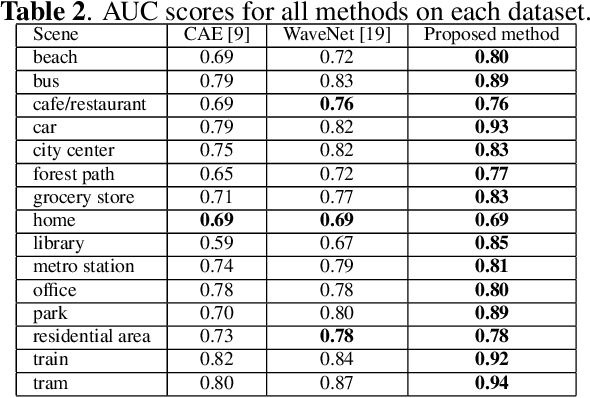
Acoustic anomaly detection aims at distinguishing abnormal acoustic signals from the normal ones. It suffers from the class imbalance issue and the lacking in the abnormal instances. In addition, collecting all kinds of abnormal or unknown samples for training purpose is impractical and timeconsuming. In this paper, a novel Gaussian Mixture Generative Adversarial Network (GMGAN) is proposed under semi-supervised learning framework, in which the underlying structure of training data is not only captured in spectrogram reconstruction space, but also can be further restricted in the space of latent representation in a discriminant manner. Experiments show that our model has clear superiority over previous methods, and achieves the state-of-the-art results on DCASE dataset.