 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
Lemon Agent Technical Report
Feb 06, 2026Recent advanced LLM-powered agent systems have exhibited their remarkable capabilities in tackling complex, long-horizon tasks. Nevertheless, they still suffer from inherent limitations in resource efficiency, context management, and multimodal perception. Based on these observations, Lemon Agent is introduced, a multi-agent orchestrator-worker system built on a newly proposed AgentCortex framework, which formalizes the classic Planner-Executor-Memory paradigm through an adaptive task execution mechanism. Our system integrates a hierarchical self-adaptive scheduling mechanism that operates at both the overall orchestrator layer and workers layer. This mechanism can dynamically adjust computational intensity based on task complexity. It enables orchestrator to allocate one or more workers for parallel subtask execution, while workers can further improve operational efficiency by invoking tools concurrently. By virtue of this two-tier architecture, the system achieves synergistic balance between global task coordination and local task execution, thereby optimizing resource utilization and task processing efficiency in complex scenarios. To reduce context redundancy and increase information density during parallel steps, we adopt a three-tier progressive context management strategy. To make fuller use of historical information, we propose a self-evolving memory system, which can extract multi-dimensional valid information from all historical experiences to assist in completing similar tasks. Furthermore, we provide an enhanced MCP toolset. Empirical evaluations on authoritative benchmarks demonstrate that our Lemon Agent can achieve a state-of-the-art 91.36% overall accuracy on GAIA and secures the top position on the xbench-DeepSearch leaderboard with a score of 77+.
MAGI-1: Autoregressive Video Generation at Scale
May 19, 2025



We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
FDA: Feature Decomposition and Aggregation for Robust Airway Segmentation
Sep 07, 2021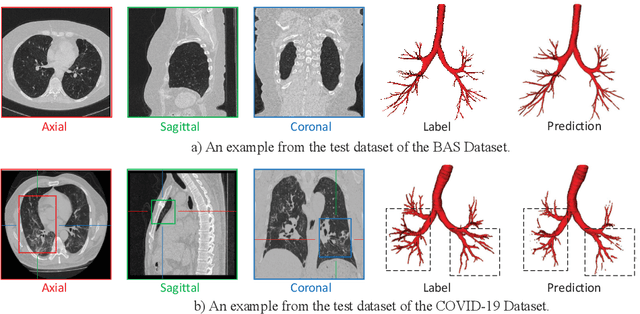
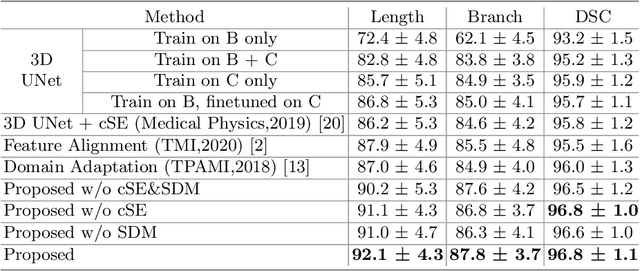
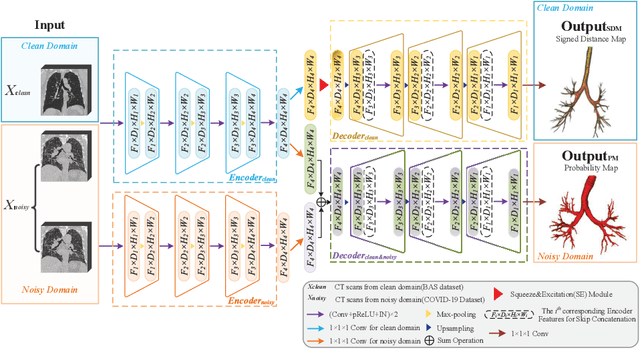
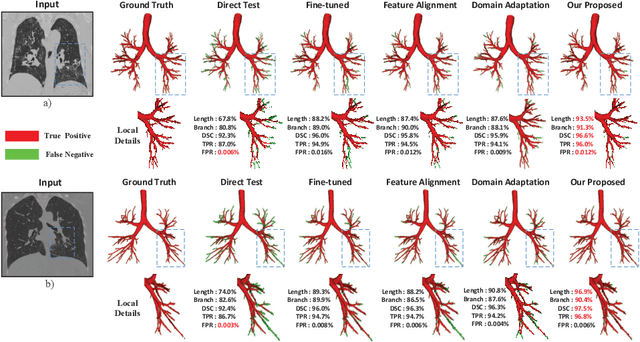
3D Convolutional Neural Networks (CNNs) have been widely adopted for airway segmentation. The performance of 3D CNNs is greatly influenced by the dataset while the public airway datasets are mainly clean CT scans with coarse annotation, thus difficult to be generalized to noisy CT scans (e.g. COVID-19 CT scans). In this work, we proposed a new dual-stream network to address the variability between the clean domain and noisy domain, which utilizes the clean CT scans and a small amount of labeled noisy CT scans for airway segmentation. We designed two different encoders to extract the transferable clean features and the unique noisy features separately, followed by two independent decoders. Further on, the transferable features are refined by the channel-wise feature recalibration and Signed Distance Map (SDM) regression. The feature recalibration module emphasizes critical features and the SDM pays more attention to the bronchi, which is beneficial to extracting the transferable topological features robust to the coarse labels. Extensive experimental results demonstrated the obvious improvement brought by our proposed method. Compared to other state-of-the-art transfer learning methods, our method accurately segmented more bronchi in the noisy CT scans.
Condition Assessment of Stay Cables through Enhanced Time Series Classification Using a Deep Learning Approach
Jan 11, 2021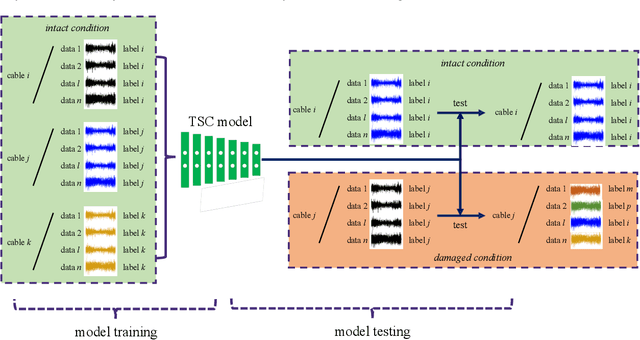

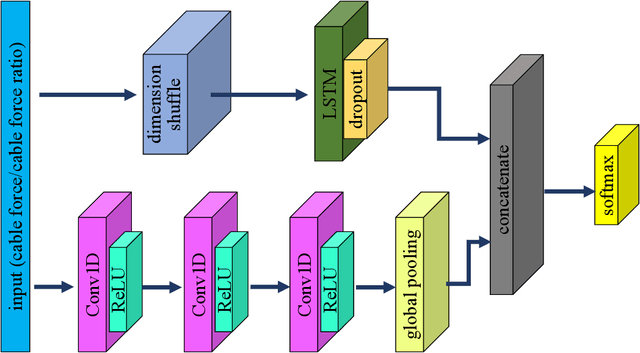

This study proposes a data-driven method that detects cable damage from measured cable forces by recognizing biased patterns from the intact conditions. The proposed method solves the pattern recognition problem for cable damage detection through time series classification (TSC) in deep learning, considering that the cable's behavior can be implicitly represented by the measured cable force series. A deep learning model, long short term memory fully convolutional network (LSTM-FCN), is leveraged by assigning appropriate inputs and representative class labels for the TSC problem, First, a TSC classifier is trained and validated using the data collected under intact conditions of stay cables, setting the segmented data series as input and the cable (or cable pair) ID as class labels. Subsequently, the classifier is tested using the data collected under possible damaged conditions. Finally, the cable or cable pair corresponding to the least classification accuracy is recommended as the most probable damaged cable or cable pair. The proposed method was tested on an in-service cable-stayed bridge with damaged stay cables. Two scenarios in the proposed TSC scheme were investigated: 1) raw time series of cable forces were fed into the classifiers; and 2) cable force ratios were inputted in the classifiers considering the possible variation of force distribution between cable pairs due to cable damage. Combining the results of TSC testing in these two scenarios, the cable with rupture was correctly identified. This study proposes a data-driven methodology for cable damage detection that requires the least data preprocessing and feature engineering, which enables fast and convenient early detection in real applications.
A Novel DNN Training Framework via Data Sampling and Multi-Task Optimization
Jul 02, 2020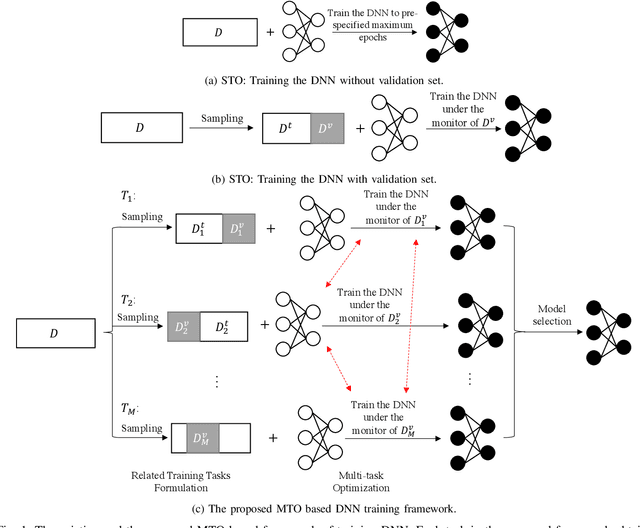
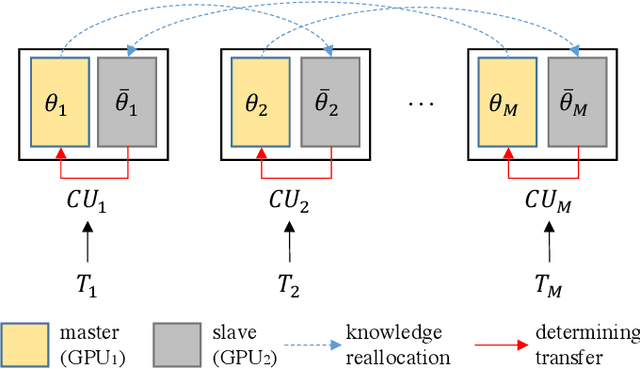
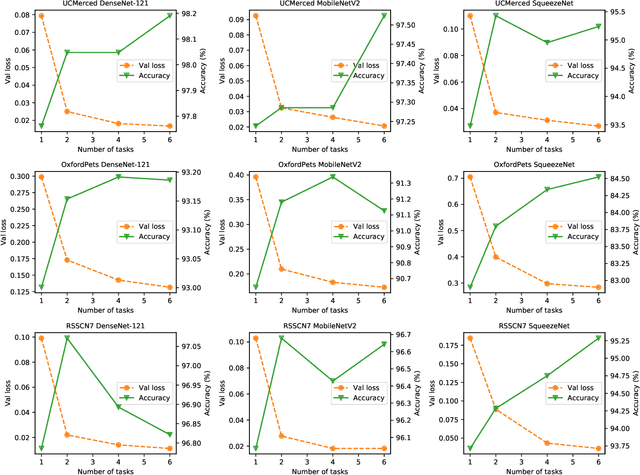
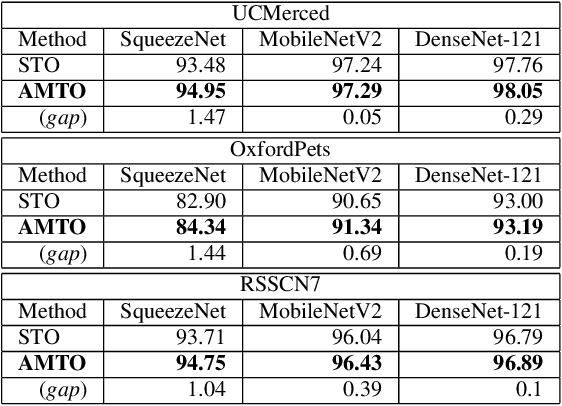
Conventional DNN training paradigms typically rely on one training set and one validation set, obtained by partitioning an annotated dataset used for training, namely gross training set, in a certain way. The training set is used for training the model while the validation set is used to estimate the generalization performance of the trained model as the training proceeds to avoid over-fitting. There exist two major issues in this paradigm. Firstly, the validation set may hardly guarantee an unbiased estimate of generalization performance due to potential mismatching with test data. Secondly, training a DNN corresponds to solve a complex optimization problem, which is prone to getting trapped into inferior local optima and thus leads to undesired training results. To address these issues, we propose a novel DNN training framework. It generates multiple pairs of training and validation sets from the gross training set via random splitting, trains a DNN model of a pre-specified structure on each pair while making the useful knowledge (e.g., promising network parameters) obtained from one model training process to be transferred to other model training processes via multi-task optimization, and outputs the best, among all trained models, which has the overall best performance across the validation sets from all pairs. The knowledge transfer mechanism featured in this new framework can not only enhance training effectiveness by helping the model training process to escape from local optima but also improve on generalization performance via implicit regularization imposed on one model training process from other model training processes. We implement the proposed framework, parallelize the implementation on a GPU cluster, and apply it to train several widely used DNN models. Experimental results demonstrate the superiority of the proposed framework over the conventional training paradigm.
PGD-UNet: A Position-Guided Deformable Network for Simultaneous Segmentation of Organs and Tumors
Jul 02, 2020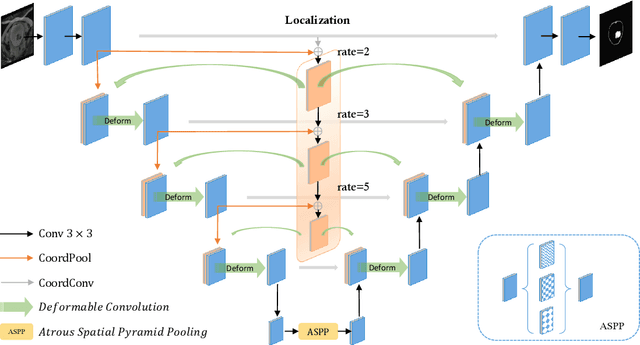
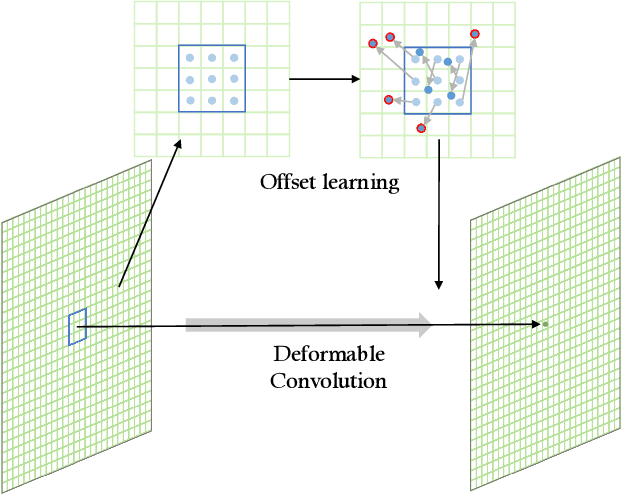
Precise segmentation of organs and tumors plays a crucial role in clinical applications. It is a challenging task due to the irregular shapes and various sizes of organs and tumors as well as the significant class imbalance between the anatomy of interest (AOI) and the background region. In addition, in most situation tumors and normal organs often overlap in medical images, but current approaches fail to delineate both tumors and organs accurately. To tackle such challenges, we propose a position-guided deformable UNet, namely PGD-UNet, which exploits the spatial deformation capabilities of deformable convolution to deal with the geometric transformation of both organs and tumors. Position information is explicitly encoded into the network to enhance the capabilities of deformation. Meanwhile, we introduce a new pooling module to preserve position information lost in conventional max-pooling operation. Besides, due to unclear boundaries between different structures as well as the subjectivity of annotations, labels are not necessarily accurate for medical image segmentation tasks. It may cause the overfitting of the trained network due to label noise. To address this issue, we formulate a novel loss function to suppress the influence of potential label noise on the training process. Our method was evaluated on two challenging segmentation tasks and achieved very promising segmentation accuracy in both tasks.
A comprehensive study of sparse codes on abnormality detection
Mar 13, 2016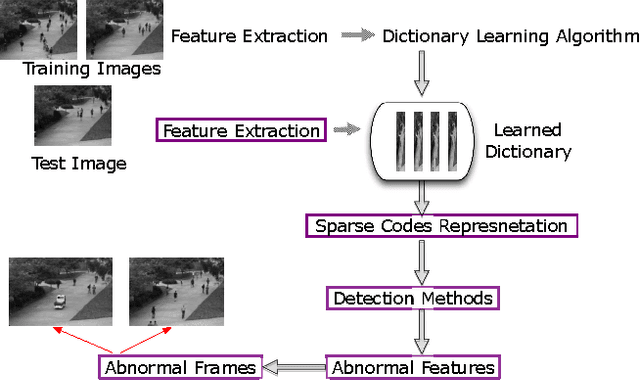


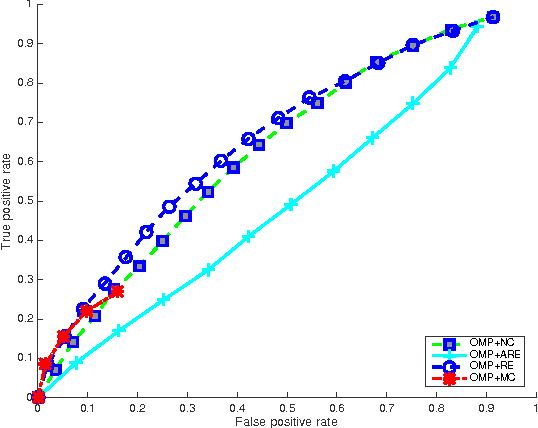
Sparse representation has been applied successfully in abnormal event detection, in which the baseline is to learn a dictionary accompanied by sparse codes. While much emphasis is put on discriminative dictionary construction, there are no comparative studies of sparse codes regarding abnormality detection. We comprehensively study two types of sparse codes solutions - greedy algorithms and convex L1-norm solutions - and their impact on abnormality detection performance. We also propose our framework of combining sparse codes with different detection methods. Our comparative experiments are carried out from various angles to better understand the applicability of sparse codes, including computation time, reconstruction error, sparsity, detection accuracy, and their performance combining various detection methods. Experiments show that combining OMP codes with maximum coordinate detection could achieve state-of-the-art performance on the UCSD dataset [14].