 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Divergence Measures for Bayesian Pseudocoresets
Oct 12, 2022



A Bayesian pseudocoreset is a small synthetic dataset for which the posterior over parameters approximates that of the original dataset. While promising, the scalability of Bayesian pseudocoresets is not yet validated in realistic problems such as image classification with deep neural networks. On the other hand, dataset distillation methods similarly construct a small dataset such that the optimization using the synthetic dataset converges to a solution with performance competitive with optimization using full data. Although dataset distillation has been empirically verified in large-scale settings, the framework is restricted to point estimates, and their adaptation to Bayesian inference has not been explored. This paper casts two representative dataset distillation algorithms as approximations to methods for constructing pseudocoresets by minimizing specific divergence measures: reverse KL divergence and Wasserstein distance. Furthermore, we provide a unifying view of such divergence measures in Bayesian pseudocoreset construction. Finally, we propose a novel Bayesian pseudocoreset algorithm based on minimizing forward KL divergence. Our empirical results demonstrate that the pseudocoresets constructed from these methods reflect the true posterior even in high-dimensional Bayesian inference problems.
AlphaTuning: Quantization-Aware Parameter-Efficient Adaptation of Large-Scale Pre-Trained Language Models
Oct 08, 2022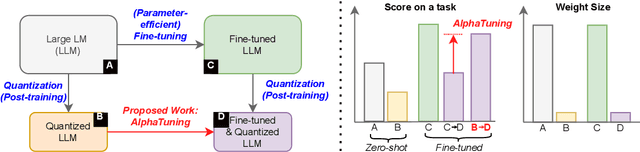

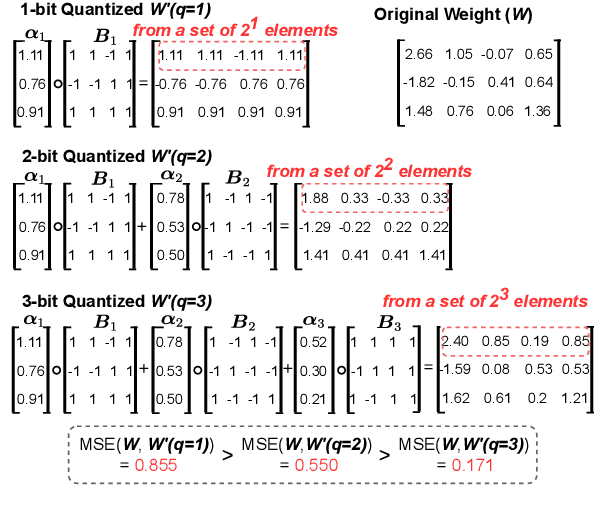
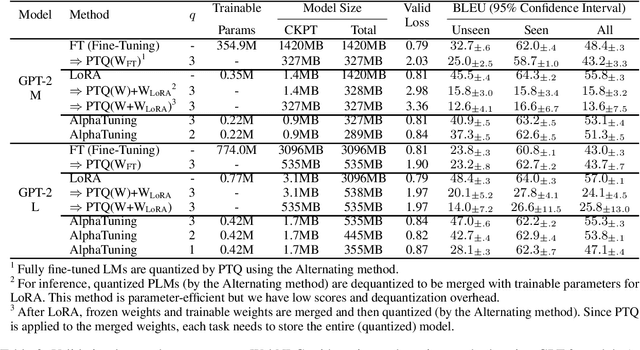
There are growing interests in adapting large-scale language models using parameter-efficient fine-tuning methods. However, accelerating the model itself and achieving better inference efficiency through model compression has not been thoroughly explored yet. Model compression could provide the benefits of reducing memory footprints, enabling low-precision computations, and ultimately achieving cost-effective inference. To combine parameter-efficient adaptation and model compression, we propose AlphaTuning consisting of post-training quantization of the pre-trained language model and fine-tuning only some parts of quantized parameters for a target task. Specifically, AlphaTuning works by employing binary-coding quantization, which factorizes the full-precision parameters into binary parameters and a separate set of scaling factors. During the adaptation phase, the binary values are frozen for all tasks, while the scaling factors are fine-tuned for the downstream task. We demonstrate that AlphaTuning, when applied to GPT-2 and OPT, performs competitively with full fine-tuning on a variety of downstream tasks while achieving >10x compression ratio under 4-bit quantization and >1,000x reduction in the number of trainable parameters.
Continuous Decomposition of Granularity for Neural Paraphrase Generation
Sep 16, 2022
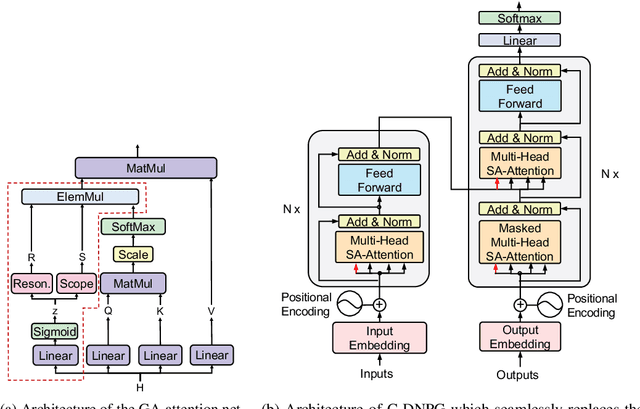

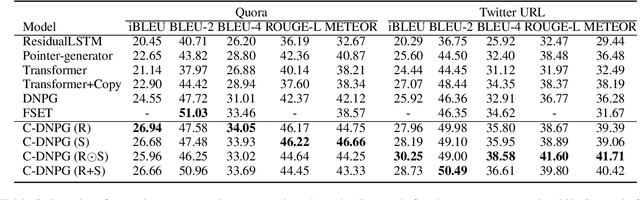
While Transformers have had significant success in paragraph generation, they treat sentences as linear sequences of tokens and often neglect their hierarchical information. Prior work has shown that decomposing the levels of granularity~(e.g., word, phrase, or sentence) for input tokens has produced substantial improvements, suggesting the possibility of enhancing Transformers via more fine-grained modeling of granularity. In this work, we propose a continuous decomposition of granularity for neural paraphrase generation (C-DNPG). In order to efficiently incorporate granularity into sentence encoding, C-DNPG introduces a granularity-aware attention (GA-Attention) mechanism which extends the multi-head self-attention with: 1) a granularity head that automatically infers the hierarchical structure of a sentence by neurally estimating the granularity level of each input token; and 2) two novel attention masks, namely, granularity resonance and granularity scope, to efficiently encode granularity into attention. Experiments on two benchmarks, including Quora question pairs and Twitter URLs have shown that C-DNPG outperforms baseline models by a remarkable margin and achieves state-of-the-art results in terms of many metrics. Qualitative analysis reveals that C-DNPG indeed captures fine-grained levels of granularity with effectiveness.
Generator Knows What Discriminator Should Learn in Unconditional GANs
Jul 27, 2022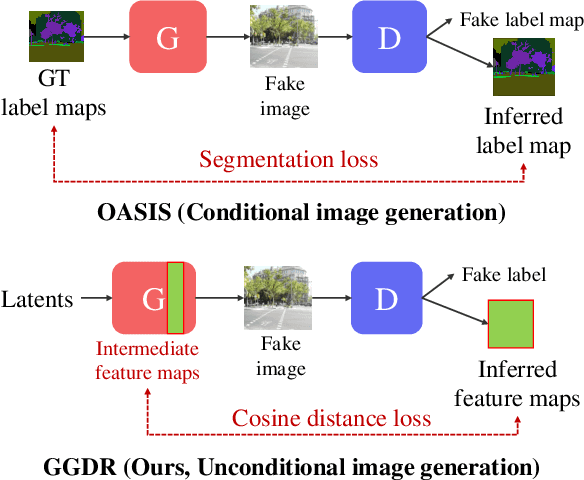
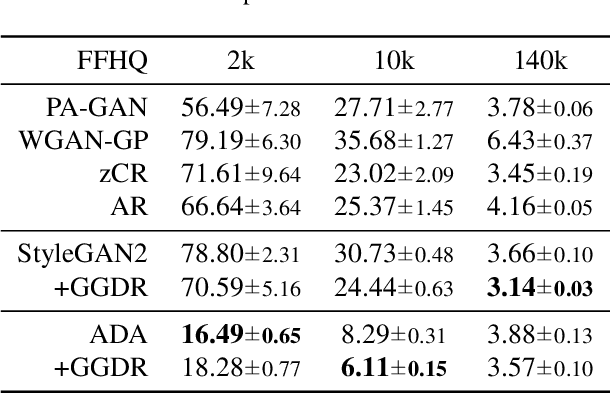
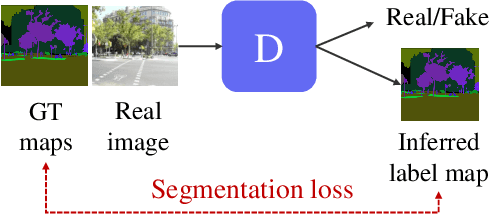
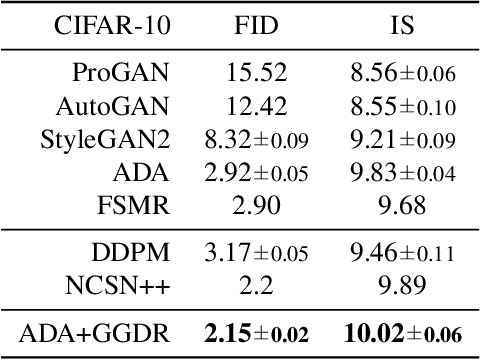
Recent methods for conditional image generation benefit from dense supervision such as segmentation label maps to achieve high-fidelity. However, it is rarely explored to employ dense supervision for unconditional image generation. Here we explore the efficacy of dense supervision in unconditional generation and find generator feature maps can be an alternative of cost-expensive semantic label maps. From our empirical evidences, we propose a new generator-guided discriminator regularization(GGDR) in which the generator feature maps supervise the discriminator to have rich semantic representations in unconditional generation. In specific, we employ an U-Net architecture for discriminator, which is trained to predict the generator feature maps given fake images as inputs. Extensive experiments on mulitple datasets show that our GGDR consistently improves the performance of baseline methods in terms of quantitative and qualitative aspects. Code is available at https://github.com/naver-ai/GGDR
Time Is MattEr: Temporal Self-supervision for Video Transformers
Jul 19, 2022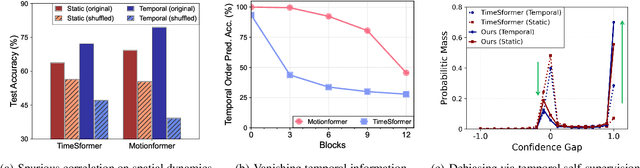
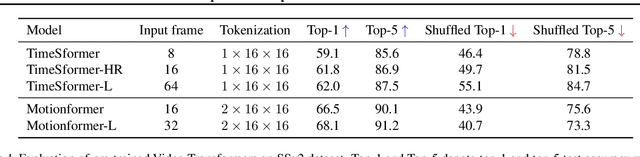
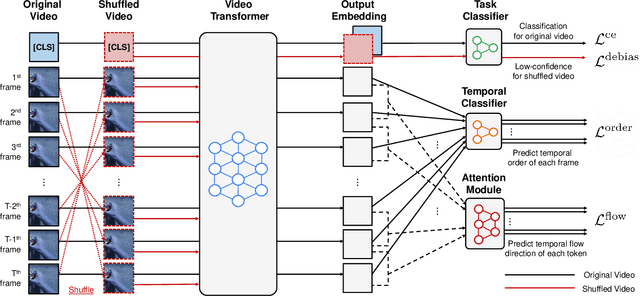
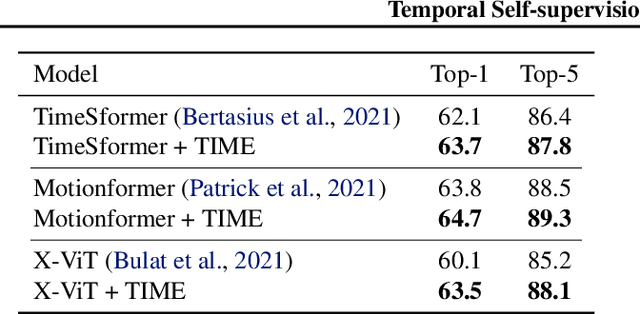
Understanding temporal dynamics of video is an essential aspect of learning better video representations. Recently, transformer-based architectural designs have been extensively explored for video tasks due to their capability to capture long-term dependency of input sequences. However, we found that these Video Transformers are still biased to learn spatial dynamics rather than temporal ones, and debiasing the spurious correlation is critical for their performance. Based on the observations, we design simple yet effective self-supervised tasks for video models to learn temporal dynamics better. Specifically, for debiasing the spatial bias, our method learns the temporal order of video frames as extra self-supervision and enforces the randomly shuffled frames to have low-confidence outputs. Also, our method learns the temporal flow direction of video tokens among consecutive frames for enhancing the correlation toward temporal dynamics. Under various video action recognition tasks, we demonstrate the effectiveness of our method and its compatibility with state-of-the-art Video Transformers.
Rarity Score : A New Metric to Evaluate the Uncommonness of Synthesized Images
Jun 26, 2022
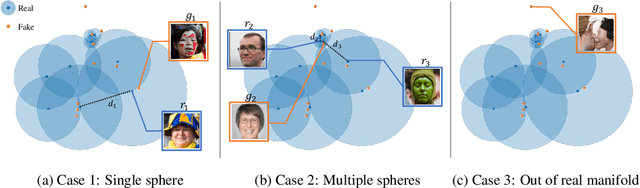
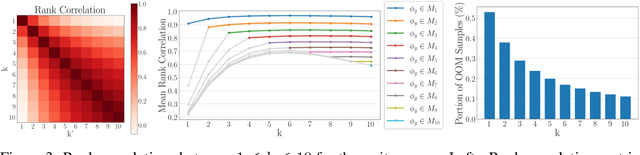

Evaluation metrics in image synthesis play a key role to measure performances of generative models. However, most metrics mainly focus on image fidelity. Existing diversity metrics are derived by comparing distributions, and thus they cannot quantify the diversity or rarity degree of each generated image. In this work, we propose a new evaluation metric, called `rarity score', to measure the individual rarity of each image synthesized by generative models. We first show empirical observation that common samples are close to each other and rare samples are far from each other in nearest-neighbor distances of feature space. We then use our metric to demonstrate that the extent to which different generative models produce rare images can be effectively compared. We also propose a method to compare rarities between datasets that share the same concept such as CelebA-HQ and FFHQ. Finally, we analyze the use of metrics in different designs of feature spaces to better understand the relationship between feature spaces and resulting sparse images. Code will be publicly available online for the research community.
Dataset Condensation via Efficient Synthetic-Data Parameterization
Jun 02, 2022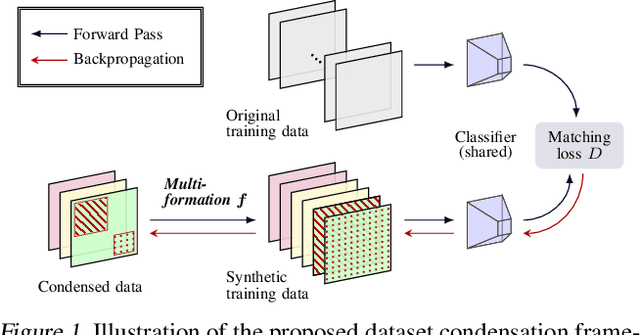
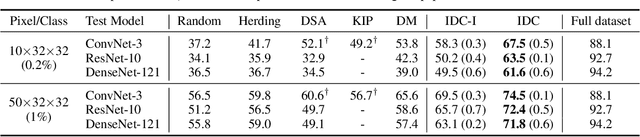
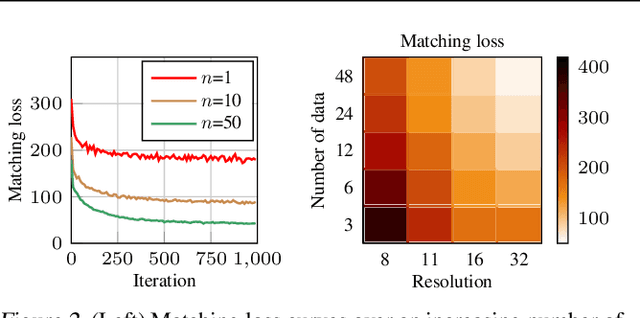
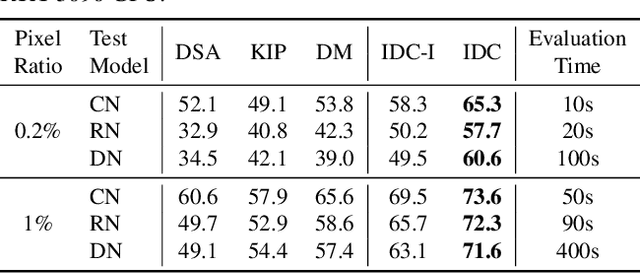
The great success of machine learning with massive amounts of data comes at a price of huge computation costs and storage for training and tuning. Recent studies on dataset condensation attempt to reduce the dependence on such massive data by synthesizing a compact training dataset. However, the existing approaches have fundamental limitations in optimization due to the limited representability of synthetic datasets without considering any data regularity characteristics. To this end, we propose a novel condensation framework that generates multiple synthetic data with a limited storage budget via efficient parameterization considering data regularity. We further analyze the shortcomings of the existing gradient matching-based condensation methods and develop an effective optimization technique for improving the condensation of training data information. We propose a unified algorithm that drastically improves the quality of condensed data against the current state-of-the-art on CIFAR-10, ImageNet, and Speech Commands.
Two-Step Question Retrieval for Open-Domain QA
May 19, 2022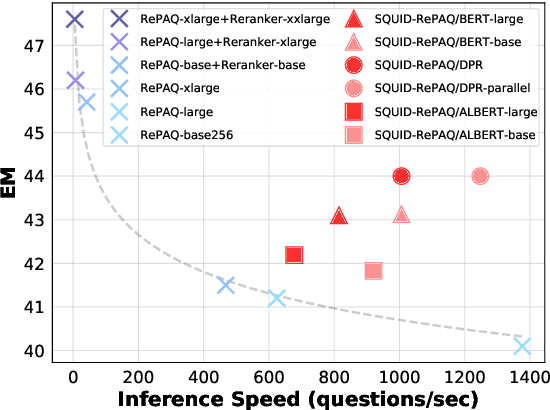
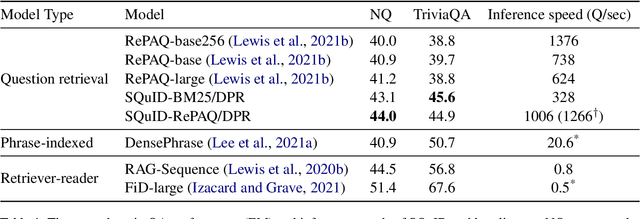
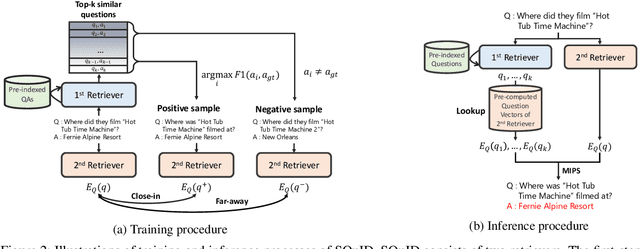
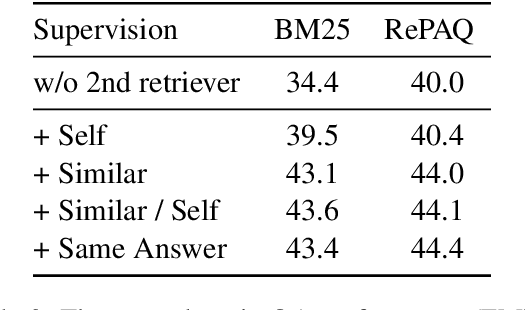
The retriever-reader pipeline has shown promising performance in open-domain QA but suffers from a very slow inference speed. Recently proposed question retrieval models tackle this problem by indexing question-answer pairs and searching for similar questions. These models have shown a significant increase in inference speed, but at the cost of lower QA performance compared to the retriever-reader models. This paper proposes a two-step question retrieval model, SQuID (Sequential Question-Indexed Dense retrieval) and distant supervision for training. SQuID uses two bi-encoders for question retrieval. The first-step retriever selects top-k similar questions, and the second-step retriever finds the most similar question from the top-k questions. We evaluate the performance and the computational efficiency of SQuID. The results show that SQuID significantly increases the performance of existing question retrieval models with a negligible loss on inference speed.
On the Effect of Pretraining Corpora on In-context Learning by a Large-scale Language Model
Apr 28, 2022
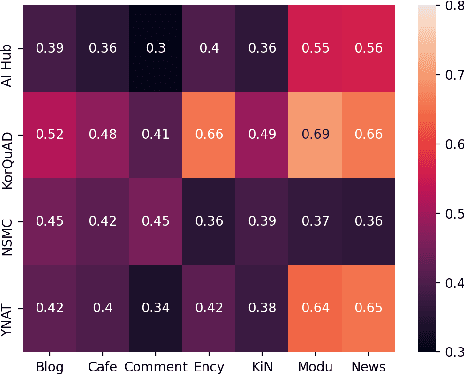
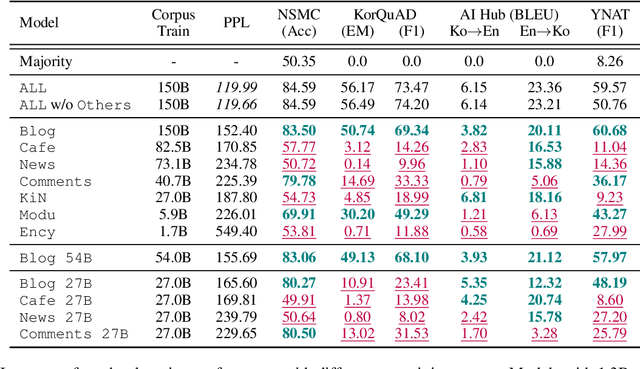
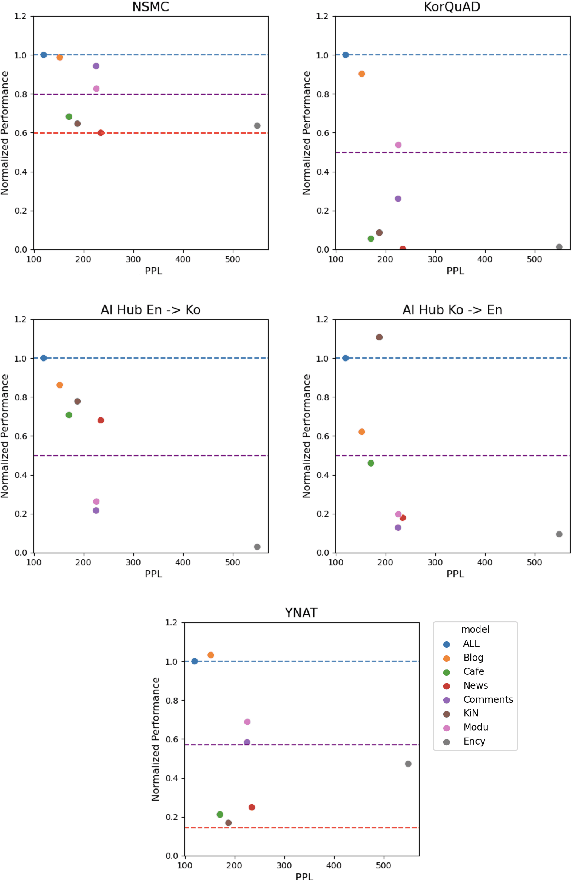
Many recent studies on large-scale language models have reported successful in-context zero- and few-shot learning ability. However, the in-depth analysis of when in-context learning occurs is still lacking. For example, it is unknown how in-context learning performance changes as the training corpus varies. Here, we investigate the effects of the source and size of the pretraining corpus on in-context learning in HyperCLOVA, a Korean-centric GPT-3 model. From our in-depth investigation, we introduce the following observations: (1) in-context learning performance heavily depends on the corpus domain source, and the size of the pretraining corpus does not necessarily determine the emergence of in-context learning, (2) in-context learning ability can emerge when a language model is trained on a combination of multiple corpora, even when each corpus does not result in in-context learning on its own, (3) pretraining with a corpus related to a downstream task does not always guarantee the competitive in-context learning performance of the downstream task, especially in the few-shot setting, and (4) the relationship between language modeling (measured in perplexity) and in-context learning does not always correlate: e.g., low perplexity does not always imply high in-context few-shot learning performance.
Online Continual Learning on a Contaminated Data Stream with Blurry Task Boundaries
Mar 30, 2022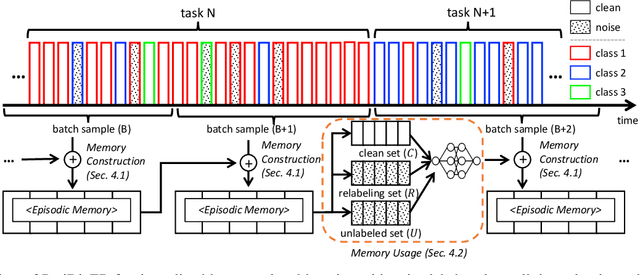
Learning under a continuously changing data distribution with incorrect labels is a desirable real-world problem yet challenging. A large body of continual learning (CL) methods, however, assumes data streams with clean labels, and online learning scenarios under noisy data streams are yet underexplored. We consider a more practical CL task setup of an online learning from blurry data stream with corrupted labels, where existing CL methods struggle. To address the task, we first argue the importance of both diversity and purity of examples in the episodic memory of continual learning models. To balance diversity and purity in the episodic memory, we propose a novel strategy to manage and use the memory by a unified approach of label noise aware diverse sampling and robust learning with semi-supervised learning. Our empirical validations on four real-world or synthetic noise datasets (CIFAR10 and 100, mini-WebVision, and Food-101N) exhibit that our method significantly outperforms prior arts in this realistic and challenging continual learning scenario. Code and data splits are available in https://github.com/clovaai/puridiver.