 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffine-Scaled Attention: Towards Flexible and Stable Transformer Attention
Feb 26, 2026Transformer attention is typically implemented using softmax normalization, which enforces attention weights with unit sum normalization. While effective in many settings, this constraint can limit flexibility in controlling attention magnitudes and may contribute to overly concentrated or unstable attention patterns during training. Prior work has explored modifications such as attention sinks or gating mechanisms, but these approaches provide only limited or indirect control over attention reweighting. We propose Affine-Scaled Attention, a simple extension to standard attention that introduces input-dependent scaling and a corresponding bias term applied to softmax-normalized attention weights. This design relaxes the strict normalization constraint while maintaining aggregation of value representations, allowing the model to adjust both the relative distribution and the scale of attention in a controlled manner. We empirically evaluate Affine-Scaled Attention in large-scale language model pretraining across multiple model sizes. Experimental results show consistent improvements in training stability, optimization behavior, and downstream task performance compared to standard softmax attention and attention sink baselines. These findings suggest that modest reweighting of attention outputs provides a practical and effective way to improve attention behavior in Transformer models.
CodeGEMM: A Codebook-Centric Approach to Efficient GEMM in Quantized LLMs
Dec 19, 2025Weight-only quantization is widely used to mitigate the memory-bound nature of LLM inference. Codebook-based methods extend this trend by achieving strong accuracy in the extremely low-bit regime (e.g., 2-bit). However, current kernels rely on dequantization, which repeatedly fetches centroids and reconstructs weights, incurring substantial latency and cache pressure. We present CodeGEMM, a codebook-centric GEMM kernel that replaces dequantization with precomputed inner products between centroids and activations stored in a lightweight Psumbook. At inference, code indices directly gather these partial sums, eliminating per-element lookups and reducing the on-chip footprint. The kernel supports the systematic exploration of latency-memory-accuracy trade-offs under a unified implementation. On Llama-3 models, CodeGEMM delivers 1.83x (8B) and 8.93x (70B) speedups in the 2-bit configuration compared to state-of-the-art codebook-based quantization at comparable accuracy and further improves computing efficiency and memory subsystem utilization.
Unifying Uniform and Binary-coding Quantization for Accurate Compression of Large Language Models
Jun 04, 2025How can we quantize large language models while preserving accuracy? Quantization is essential for deploying large language models (LLMs) efficiently. Binary-coding quantization (BCQ) and uniform quantization (UQ) are promising quantization schemes that have strong expressiveness and optimizability, respectively. However, neither scheme leverages both advantages. In this paper, we propose UniQuanF (Unified Quantization with Flexible Mapping), an accurate quantization method for LLMs. UniQuanF harnesses both strong expressiveness and optimizability by unifying the flexible mapping technique in UQ and non-uniform quantization levels of BCQ. We propose unified initialization, and local and periodic mapping techniques to optimize the parameters in UniQuanF precisely. After optimization, our unification theorem removes computational and memory overhead, allowing us to utilize the superior accuracy of UniQuanF without extra deployment costs induced by the unification. Experimental results demonstrate that UniQuanF outperforms existing UQ and BCQ methods, achieving up to 4.60% higher accuracy on GSM8K benchmark.
To FP8 and Back Again: Quantifying the Effects of Reducing Precision on LLM Training Stability
May 29, 2024



The massive computational costs associated with large language model (LLM) pretraining have spurred great interest in reduced-precision floating-point representations to accelerate the process. As a result, the BrainFloat16 (BF16) precision has become the de facto standard for LLM training, with hardware support included in recent accelerators. This trend has gone even further in the latest processors, where FP8 has recently been introduced. However, prior experience with FP16, which was found to be less stable than BF16, raises concerns as to whether FP8, with even fewer bits than FP16, can be a cost-effective option for LLM training. We argue that reduced-precision training schemes must have similar training stability and hyperparameter sensitivities to their higher-precision counterparts in order to be cost-effective. However, we find that currently available methods for FP8 training are not robust enough to allow their use as economical replacements. This prompts us to investigate the stability of reduced-precision LLM training in terms of robustness across random seeds and learning rates. To this end, we propose new evaluation techniques and a new metric for quantifying loss landscape sharpness in autoregressive language models. By simulating incremental bit reductions in floating-point representations, we analyze the relationship between representational power and training stability with the intent of aiding future research into the field.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
No Token Left Behind: Reliable KV Cache Compression via Importance-Aware Mixed Precision Quantization
Feb 28, 2024



Key-Value (KV) Caching has become an essential technique for accelerating the inference speed and throughput of generative Large Language Models~(LLMs). However, the memory footprint of the KV cache poses a critical bottleneck in LLM deployment as the cache size grows with batch size and sequence length, often surpassing even the size of the model itself. Although recent methods were proposed to select and evict unimportant KV pairs from the cache to reduce memory consumption, the potential ramifications of eviction on the generative process are yet to be thoroughly examined. In this paper, we examine the detrimental impact of cache eviction and observe that unforeseen risks arise as the information contained in the KV pairs is exhaustively discarded, resulting in safety breaches, hallucinations, and context loss. Surprisingly, we find that preserving even a small amount of information contained in the evicted KV pairs via reduced precision quantization substantially recovers the incurred degradation. On the other hand, we observe that the important KV pairs must be kept at a relatively higher precision to safeguard the generation quality. Motivated by these observations, we propose \textit{Mixed-precision KV cache}~(MiKV), a reliable cache compression method that simultaneously preserves the context details by retaining the evicted KV pairs in low-precision and ensure generation quality by keeping the important KV pairs in high-precision. Experiments on diverse benchmarks and LLM backbones show that our proposed method offers a state-of-the-art trade-off between compression ratio and performance, compared to other baselines.
AlphaTuning: Quantization-Aware Parameter-Efficient Adaptation of Large-Scale Pre-Trained Language Models
Oct 08, 2022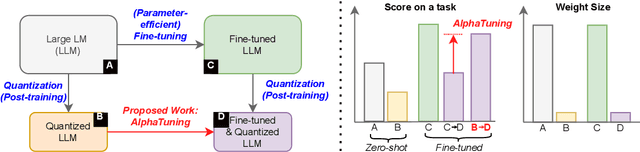

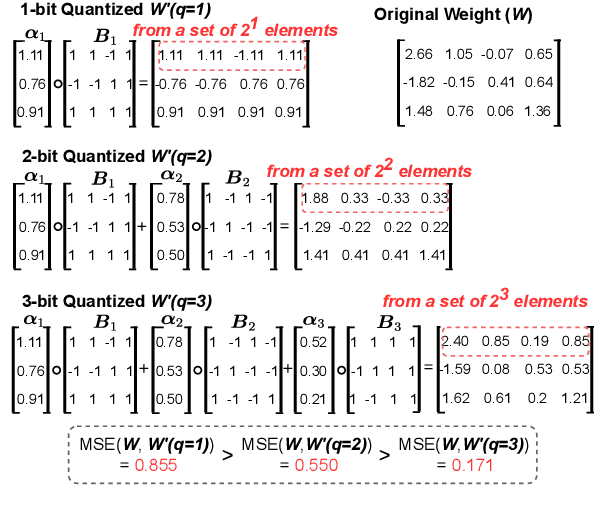
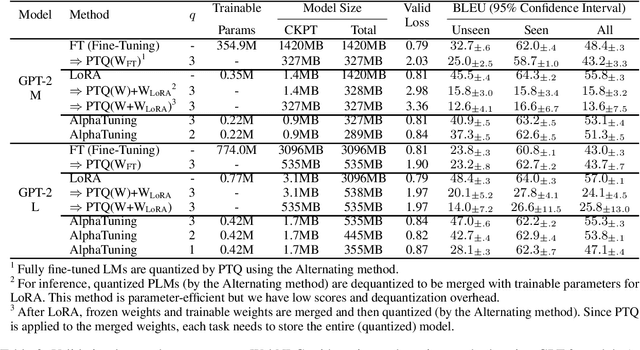
There are growing interests in adapting large-scale language models using parameter-efficient fine-tuning methods. However, accelerating the model itself and achieving better inference efficiency through model compression has not been thoroughly explored yet. Model compression could provide the benefits of reducing memory footprints, enabling low-precision computations, and ultimately achieving cost-effective inference. To combine parameter-efficient adaptation and model compression, we propose AlphaTuning consisting of post-training quantization of the pre-trained language model and fine-tuning only some parts of quantized parameters for a target task. Specifically, AlphaTuning works by employing binary-coding quantization, which factorizes the full-precision parameters into binary parameters and a separate set of scaling factors. During the adaptation phase, the binary values are frozen for all tasks, while the scaling factors are fine-tuned for the downstream task. We demonstrate that AlphaTuning, when applied to GPT-2 and OPT, performs competitively with full fine-tuning on a variety of downstream tasks while achieving >10x compression ratio under 4-bit quantization and >1,000x reduction in the number of trainable parameters.