 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2AF: A Dual-Driven Annotation and Filtering Framework for Visual Grounding
May 30, 2025



Visual Grounding is a task that aims to localize a target region in an image based on a free-form natural language description. With the rise of Transformer architectures, there is an increasing need for larger datasets to boost performance. However, the high cost of manual annotation poses a challenge, hindering the scale of data and the ability of large models to enhance their effectiveness. Previous pseudo label generation methods heavily rely on human-labeled captions of the original dataset, limiting scalability and diversity. To address this, we propose D2AF, a robust annotation framework for visual grounding using only input images. This approach overcomes dataset size limitations and enriches both the quantity and diversity of referring expressions. Our approach leverages multimodal large models and object detection models. By implementing dual-driven annotation strategies, we effectively generate detailed region-text pairs using both closed-set and open-set approaches. We further conduct an in-depth analysis of data quantity and data distribution. Our findings demonstrate that increasing data volume enhances model performance. However, the degree of improvement depends on how well the pseudo labels broaden the original data distribution. Based on these insights, we propose a consistency and distribution aware filtering method to further improve data quality by effectively removing erroneous and redundant data. This approach effectively eliminates noisy data, leading to improved performance. Experiments on three visual grounding tasks demonstrate that our method significantly improves the performance of existing models and achieves state-of-the-art results.
SageAttention2++: A More Efficient Implementation of SageAttention2
May 28, 2025
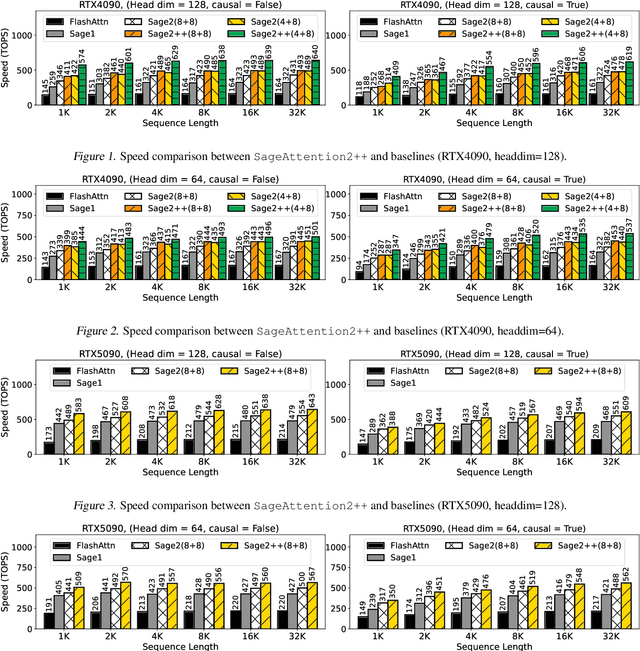
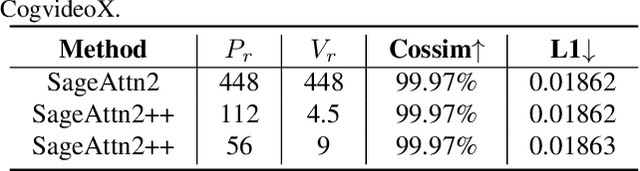
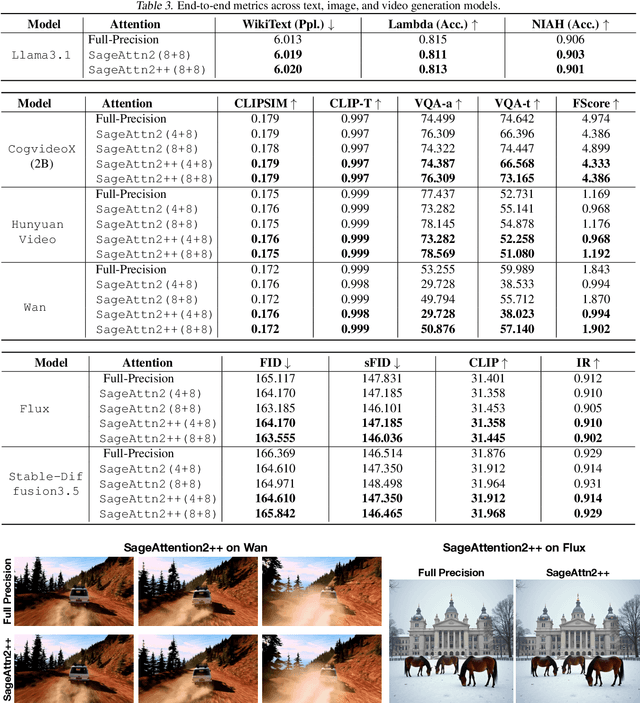
The efficiency of attention is critical because its time complexity grows quadratically with sequence length. SageAttention2 addresses this by utilizing quantization to accelerate matrix multiplications (Matmul) in attention. To further accelerate SageAttention2, we propose to utilize the faster instruction of FP8 Matmul accumulated in FP16. The instruction is 2x faster than the FP8 Matmul used in SageAttention2. Our experiments show that SageAttention2++ achieves a 3.9x speedup over FlashAttention while maintaining the same attention accuracy as SageAttention2. This means SageAttention2++ effectively accelerates various models, including those for language, image, and video generation, with negligible end-to-end metrics loss. The code will be available at https://github.com/thu-ml/SageAttention.
Versatile Cardiovascular Signal Generation with a Unified Diffusion Transformer
May 28, 2025Cardiovascular signals such as photoplethysmography (PPG), electrocardiography (ECG), and blood pressure (BP) are inherently correlated and complementary, together reflecting the health of cardiovascular system. However, their joint utilization in real-time monitoring is severely limited by diverse acquisition challenges from noisy wearable recordings to burdened invasive procedures. Here we propose UniCardio, a multi-modal diffusion transformer that reconstructs low-quality signals and synthesizes unrecorded signals in a unified generative framework. Its key innovations include a specialized model architecture to manage the signal modalities involved in generation tasks and a continual learning paradigm to incorporate varying modality combinations. By exploiting the complementary nature of cardiovascular signals, UniCardio clearly outperforms recent task-specific baselines in signal denoising, imputation, and translation. The generated signals match the performance of ground-truth signals in detecting abnormal health conditions and estimating vital signs, even in unseen domains, while ensuring interpretability for human experts. These advantages position UniCardio as a promising avenue for advancing AI-assisted healthcare.
Understanding Pre-training and Fine-tuning from Loss Landscape Perspectives
May 23, 2025



Recent studies have revealed that the loss landscape of large language models resembles a basin, within which the models perform nearly identically, and outside of which they lose all their capabilities. In this work, we conduct further studies on the loss landscape of large language models. We discover that pre-training creates a "basic capability" basin, and subsequent fine-tuning creates "specific capability" basins (e.g., math, safety, coding) within the basic capability basin. We further investigate two types of loss landscapes: the most-case landscape (i.e., the landscape along most directions) and the worst-case landscape (i.e., the landscape along the worst direction). We argue that as long as benign fine-tuning remains within the most-case basin, it will not compromise previous capabilities. Similarly, any fine-tuning (including the adversarial one) that stays within the worst-case basin would not compromise previous capabilities. Finally, we theoretically demonstrate that the size of the most-case basin can bound the size of the worst-case basin and the robustness with respect to input perturbations. We also show that, due to the over-parameterization property of current large language models, one can easily enlarge the basins by five times.
Bridging Supervised Learning and Reinforcement Learning in Math Reasoning
May 23, 2025Reinforcement Learning (RL) has played a central role in the recent surge of LLMs' math abilities by enabling self-improvement through binary verifier signals. In contrast, Supervised Learning (SL) is rarely considered for such verification-driven training, largely due to its heavy reliance on reference answers and inability to reflect on mistakes. In this work, we challenge the prevailing notion that self-improvement is exclusive to RL and propose Negative-aware Fine-Tuning (NFT) -- a supervised approach that enables LLMs to reflect on their failures and improve autonomously with no external teachers. In online training, instead of throwing away self-generated negative answers, NFT constructs an implicit negative policy to model them. This implicit policy is parameterized with the same positive LLM we target to optimize on positive data, enabling direct policy optimization on all LLMs' generations. We conduct experiments on 7B and 32B models in math reasoning tasks. Results consistently show that through the additional leverage of negative feedback, NFT significantly improves over SL baselines like Rejection sampling Fine-Tuning, matching or even surpassing leading RL algorithms like GRPO and DAPO. Furthermore, we demonstrate that NFT and GRPO are actually equivalent in strict-on-policy training, even though they originate from entirely different theoretical foundations. Our experiments and theoretical findings bridge the gap between SL and RL methods in binary-feedback learning systems.
Scaling Diffusion Transformers Efficiently via $μ$P
May 21, 2025Diffusion Transformers have emerged as the foundation for vision generative models, but their scalability is limited by the high cost of hyperparameter (HP) tuning at large scales. Recently, Maximal Update Parametrization ($\mu$P) was proposed for vanilla Transformers, which enables stable HP transfer from small to large language models, and dramatically reduces tuning costs. However, it remains unclear whether $\mu$P of vanilla Transformers extends to diffusion Transformers, which differ architecturally and objectively. In this work, we generalize standard $\mu$P to diffusion Transformers and validate its effectiveness through large-scale experiments. First, we rigorously prove that $\mu$P of mainstream diffusion Transformers, including DiT, U-ViT, PixArt-$\alpha$, and MMDiT, aligns with that of the vanilla Transformer, enabling the direct application of existing $\mu$P methodologies. Leveraging this result, we systematically demonstrate that DiT-$\mu$P enjoys robust HP transferability. Notably, DiT-XL-2-$\mu$P with transferred learning rate achieves 2.9 times faster convergence than the original DiT-XL-2. Finally, we validate the effectiveness of $\mu$P on text-to-image generation by scaling PixArt-$\alpha$ from 0.04B to 0.61B and MMDiT from 0.18B to 18B. In both cases, models under $\mu$P outperform their respective baselines while requiring small tuning cost, only 5.5% of one training run for PixArt-$\alpha$ and 3% of consumption by human experts for MMDiT-18B. These results establish $\mu$P as a principled and efficient framework for scaling diffusion Transformers.
SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training
May 16, 2025The efficiency of attention is important due to its quadratic time complexity. We enhance the efficiency of attention through two key contributions: First, we leverage the new FP4 Tensor Cores in Blackwell GPUs to accelerate attention computation. Our implementation achieves 1038 TOPS on RTX5090, which is a 5x speedup over the fastest FlashAttention on RTX5090. Experiments show that our FP4 attention can accelerate inference of various models in a plug-and-play way. Second, we pioneer low-bit attention to training tasks. Existing low-bit attention works like FlashAttention3 and SageAttention focus only on inference. However, the efficiency of training large models is also important. To explore whether low-bit attention can be effectively applied to training tasks, we design an accurate and efficient 8-bit attention for both forward and backward propagation. Experiments indicate that 8-bit attention achieves lossless performance in fine-tuning tasks but exhibits slower convergence in pretraining tasks. The code will be available at https://github.com/thu-ml/SageAttention.
Video4DGen: Enhancing Video and 4D Generation through Mutual Optimization
Apr 05, 2025The advancement of 4D (i.e., sequential 3D) generation opens up new possibilities for lifelike experiences in various applications, where users can explore dynamic objects or characters from any viewpoint. Meanwhile, video generative models are receiving particular attention given their ability to produce realistic and imaginative frames. These models are also observed to exhibit strong 3D consistency, indicating the potential to act as world simulators. In this work, we present Video4DGen, a novel framework that excels in generating 4D representations from single or multiple generated videos as well as generating 4D-guided videos. This framework is pivotal for creating high-fidelity virtual contents that maintain both spatial and temporal coherence. The 4D outputs generated by Video4DGen are represented using our proposed Dynamic Gaussian Surfels (DGS), which optimizes time-varying warping functions to transform Gaussian surfels (surface elements) from a static state to a dynamically warped state. We design warped-state geometric regularization and refinements on Gaussian surfels, to preserve the structural integrity and fine-grained appearance details. To perform 4D generation from multiple videos and capture representation across spatial, temporal, and pose dimensions, we design multi-video alignment, root pose optimization, and pose-guided frame sampling strategies. The leveraging of continuous warping fields also enables a precise depiction of pose, motion, and deformation over per-video frames. Further, to improve the overall fidelity from the observation of all camera poses, Video4DGen performs novel-view video generation guided by the 4D content, with the proposed confidence-filtered DGS to enhance the quality of generated sequences. With the ability of 4D and video generation, Video4DGen offers a powerful tool for applications in virtual reality, animation, and beyond.
DeepMesh: Auto-Regressive Artist-mesh Creation with Reinforcement Learning
Mar 19, 2025



Triangle meshes play a crucial role in 3D applications for efficient manipulation and rendering. While auto-regressive methods generate structured meshes by predicting discrete vertex tokens, they are often constrained by limited face counts and mesh incompleteness. To address these challenges, we propose DeepMesh, a framework that optimizes mesh generation through two key innovations: (1) an efficient pre-training strategy incorporating a novel tokenization algorithm, along with improvements in data curation and processing, and (2) the introduction of Reinforcement Learning (RL) into 3D mesh generation to achieve human preference alignment via Direct Preference Optimization (DPO). We design a scoring standard that combines human evaluation with 3D metrics to collect preference pairs for DPO, ensuring both visual appeal and geometric accuracy. Conditioned on point clouds and images, DeepMesh generates meshes with intricate details and precise topology, outperforming state-of-the-art methods in both precision and quality. Project page: https://zhaorw02.github.io/DeepMesh/
DiffGAP: A Lightweight Diffusion Module in Contrastive Space for Bridging Cross-Model Gap
Mar 15, 2025



Recent works in cross-modal understanding and generation, notably through models like CLAP (Contrastive Language-Audio Pretraining) and CAVP (Contrastive Audio-Visual Pretraining), have significantly enhanced the alignment of text, video, and audio embeddings via a single contrastive loss. However, these methods often overlook the bidirectional interactions and inherent noises present in each modality, which can crucially impact the quality and efficacy of cross-modal integration. To address this limitation, we introduce DiffGAP, a novel approach incorporating a lightweight generative module within the contrastive space. Specifically, our DiffGAP employs a bidirectional diffusion process tailored to bridge the cross-modal gap more effectively. This involves a denoising process on text and video embeddings conditioned on audio embeddings and vice versa, thus facilitating a more nuanced and robust cross-modal interaction. Our experimental results on VGGSound and AudioCaps datasets demonstrate that DiffGAP significantly improves performance in video/text-audio generation and retrieval tasks, confirming its effectiveness in enhancing cross-modal understanding and generation capabilities.