 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Language Model Is a Good Guide for Large Language Model in Chinese Entity Relation Extraction
Feb 22, 2024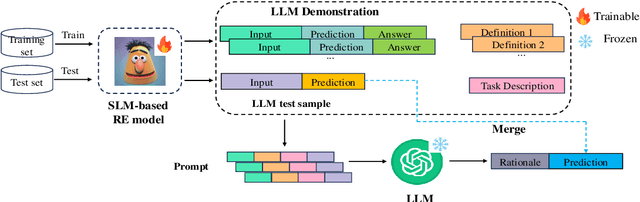

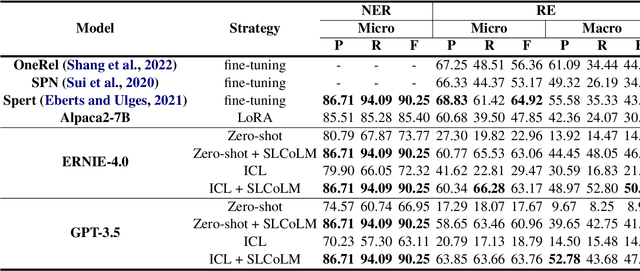
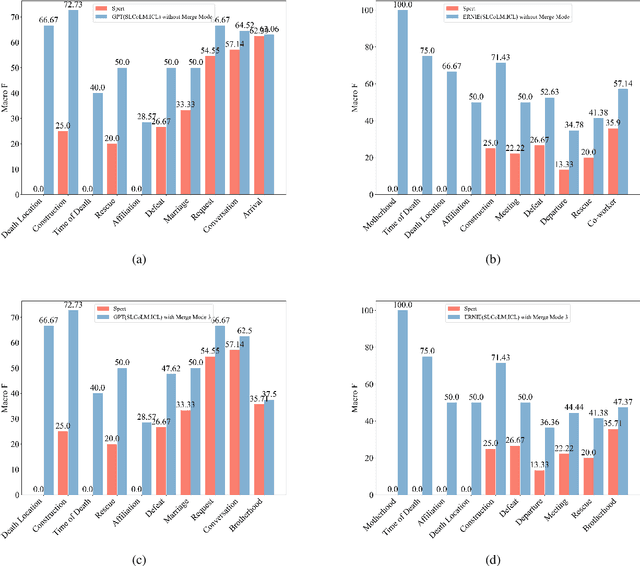
Recently, large language models (LLMs) have been successful in relational extraction (RE) tasks, especially in the few-shot learning. An important problem in the field of RE is long-tailed data, while not much attention is currently paid to this problem using LLM approaches. Therefore, in this paper, we propose SLCoLM, a model collaboration framework, to mitigate the data long-tail problem. In our framework, We use the ``\textit{Training-Guide-Predict}'' strategy to combine the strengths of pre-trained language models (PLMs) and LLMs, where a task-specific PLM framework acts as a tutor, transfers task knowledge to the LLM, and guides the LLM in performing RE tasks. Our experiments on a RE dataset rich in relation types show that the approach in this paper facilitates RE of long-tail relation types.
Understanding the Role of Cross-Entropy Loss in Fairly Evaluating Large Language Model-based Recommendation
Feb 22, 2024



Large language models (LLMs) have gained much attention in the recommendation community; some studies have observed that LLMs, fine-tuned by the cross-entropy loss with a full softmax, could achieve state-of-the-art performance already. However, these claims are drawn from unobjective and unfair comparisons. In view of the substantial quantity of items in reality, conventional recommenders typically adopt a pointwise/pairwise loss function instead for training. This substitute however causes severe performance degradation, leading to under-estimation of conventional methods and over-confidence in the ranking capability of LLMs. In this work, we theoretically justify the superiority of cross-entropy, and showcase that it can be adequately replaced by some elementary approximations with certain necessary modifications. The remarkable results across three public datasets corroborate that even in a practical sense, existing LLM-based methods are not as effective as claimed for next-item recommendation. We hope that these theoretical understandings in conjunction with the empirical results will facilitate an objective evaluation of LLM-based recommendation in the future.
Bayesian Reward Models for LLM Alignment
Feb 20, 2024To ensure that large language model (LLM) responses are helpful and non-toxic, we usually fine-tune a reward model on human preference data. We then select policy responses with high rewards (best-of-n sampling) or further optimize the policy to produce responses with high rewards (reinforcement learning from human feedback). However, this process is vulnerable to reward overoptimization or hacking, in which the responses selected have high rewards due to errors in the reward model rather than a genuine preference. This is especially problematic as the prompt or response diverges from the training data. It should be possible to mitigate these issues by training a Bayesian reward model, which signals higher uncertainty further from the training data distribution. Therefore, we trained Bayesian reward models using Laplace-LoRA (Yang et al., 2024) and found that the resulting uncertainty estimates can successfully mitigate reward overoptimization in best-of-n sampling.
Case Study: Testing Model Capabilities in Some Reasoning Tasks
Feb 15, 2024Large Language Models (LLMs) excel in generating personalized content and facilitating interactive dialogues, showcasing their remarkable aptitude for a myriad of applications. However, their capabilities in reasoning and providing explainable outputs, especially within the context of reasoning abilities, remain areas for improvement. In this study, we delve into the reasoning abilities of LLMs, highlighting the current challenges and limitations that hinder their effectiveness in complex reasoning scenarios.
Natural Language Reinforcement Learning
Feb 14, 2024Reinforcement Learning (RL) has shown remarkable abilities in learning policies for decision-making tasks. However, RL is often hindered by issues such as low sample efficiency, lack of interpretability, and sparse supervision signals. To tackle these limitations, we take inspiration from the human learning process and introduce Natural Language Reinforcement Learning (NLRL), which innovatively combines RL principles with natural language representation. Specifically, NLRL redefines RL concepts like task objectives, policy, value function, Bellman equation, and policy iteration in natural language space. We present how NLRL can be practically implemented with the latest advancements in large language models (LLMs) like GPT-4. Initial experiments over tabular MDPs demonstrate the effectiveness, efficiency, and also interpretability of the NLRL framework.
Intelligent Agricultural Management Considering N$_2$O Emission and Climate Variability with Uncertainties
Feb 13, 2024



This study examines how artificial intelligence (AI), especially Reinforcement Learning (RL), can be used in farming to boost crop yields, fine-tune nitrogen use and watering, and reduce nitrate runoff and greenhouse gases, focusing on Nitrous Oxide (N$_2$O) emissions from soil. Facing climate change and limited agricultural knowledge, we use Partially Observable Markov Decision Processes (POMDPs) with a crop simulator to model AI agents' interactions with farming environments. We apply deep Q-learning with Recurrent Neural Network (RNN)-based Q networks for training agents on optimal actions. Also, we develop Machine Learning (ML) models to predict N$_2$O emissions, integrating these predictions into the simulator. Our research tackles uncertainties in N$_2$O emission estimates with a probabilistic ML approach and climate variability through a stochastic weather model, offering a range of emission outcomes to improve forecast reliability and decision-making. By incorporating climate change effects, we enhance agents' climate adaptability, aiming for resilient agricultural practices. Results show these agents can align crop productivity with environmental concerns by penalizing N$_2$O emissions, adapting effectively to climate shifts like warmer temperatures and less rain. This strategy improves farm management under climate change, highlighting AI's role in sustainable agriculture.
A Statistical Model of Bursty Mixed Gaussian-impulsive Noise: Model and Parameter Estimation
Feb 09, 2024Non-Gaussian impulsive noise (IN) with memory exists in many practical applications. When it is mixed with white Gaussian noise (WGN), the resultant mixed noise will be bursty. The performance of communication systems will degrade significantly under bursty mixed noise if the bursty characteristic is ignored. A proper model for the bursty mixed noise and corresponding algorithms needs to be designed to obtain desirable performance but there is no such model reported to the best of our knowledge. The important problem is addressed in the two-part paper. In the first part, we propose a closed-form heavy-tailed multivariate probability density function (PDF) that to model the bursty mixed noise. This model is the weighted addition of gaussian distribution and student distribution. Then, we present the parameter estimation method based on the empirical characteristic function of the proposed model and analyze the performance of the parameter estimation. Numerical results show that our proposed bursty mixed noise model matches the measured bursty noise well. Meanwhile, the parameters of the proposed noise model can be accurately estimated in terms of mean square error (MSE).
Entropy-Regularized Token-Level Policy Optimization for Large Language Models
Feb 09, 2024



Large Language Models (LLMs) have shown promise as intelligent agents in interactive decision-making tasks. Traditional approaches often depend on meticulously designed prompts, high-quality examples, or additional reward models for in-context learning, supervised fine-tuning, or RLHF. Reinforcement learning (RL) presents a dynamic alternative for LLMs to overcome these dependencies by engaging directly with task-specific environments. Nonetheless, it faces significant hurdles: 1) instability stemming from the exponentially vast action space requiring exploration; 2) challenges in assigning token-level credit based on action-level reward signals, resulting in discord between maximizing rewards and accurately modeling corpus data. In response to these challenges, we introduce Entropy-Regularized Token-level Policy Optimization (ETPO), an entropy-augmented RL method tailored for optimizing LLMs at the token level. At the heart of ETPO is our novel per-token soft Bellman update, designed to harmonize the RL process with the principles of language modeling. This methodology decomposes the Q-function update from a coarse action-level view to a more granular token-level perspective, backed by theoretical proof of optimization consistency. Crucially, this decomposition renders linear time complexity in action exploration. We assess the effectiveness of ETPO within a simulated environment that models data science code generation as a series of multi-step interactive tasks; results show that ETPO achieves effective performance improvement on the CodeLlama-7B model and surpasses a variant PPO baseline inherited from RLHF. This underlines ETPO's potential as a robust method for refining the interactive decision-making capabilities of LLMs.
CounterCLR: Counterfactual Contrastive Learning with Non-random Missing Data in Recommendation
Feb 08, 2024


Recommender systems are designed to learn user preferences from observed feedback and comprise many fundamental tasks, such as rating prediction and post-click conversion rate (pCVR) prediction. However, the observed feedback usually suffer from two issues: selection bias and data sparsity, where biased and insufficient feedback seriously degrade the performance of recommender systems in terms of accuracy and ranking. Existing solutions for handling the issues, such as data imputation and inverse propensity score, are highly susceptible to additional trained imputation or propensity models. In this work, we propose a novel counterfactual contrastive learning framework for recommendation, named CounterCLR, to tackle the problem of non-random missing data by exploiting the advances in contrast learning. Specifically, the proposed CounterCLR employs a deep representation network, called CauNet, to infer non-random missing data in recommendations and perform user preference modeling by further introducing a self-supervised contrastive learning task. Our CounterCLR mitigates the selection bias problem without the need for additional models or estimators, while also enhancing the generalization ability in cases of sparse data. Experiments on real-world datasets demonstrate the effectiveness and superiority of our method.
Deep Learning for Multivariate Time Series Imputation: A Survey
Feb 06, 2024The ubiquitous missing values cause the multivariate time series data to be partially observed, destroying the integrity of time series and hindering the effective time series data analysis. Recently deep learning imputation methods have demonstrated remarkable success in elevating the quality of corrupted time series data, subsequently enhancing performance in downstream tasks. In this paper, we conduct a comprehensive survey on the recently proposed deep learning imputation methods. First, we propose a taxonomy for the reviewed methods, and then provide a structured review of these methods by highlighting their strengths and limitations. We also conduct empirical experiments to study different methods and compare their enhancement for downstream tasks. Finally, the open issues for future research on multivariate time series imputation are pointed out. All code and configurations of this work, including a regularly maintained multivariate time series imputation paper list, can be found in the GitHub repository~\url{https://github.com/WenjieDu/Awesome\_Imputation}.