 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Local Exploration for Replanning in Cluttered Unknown Environments for Micro-Aerial Vehicles
Mar 12, 2018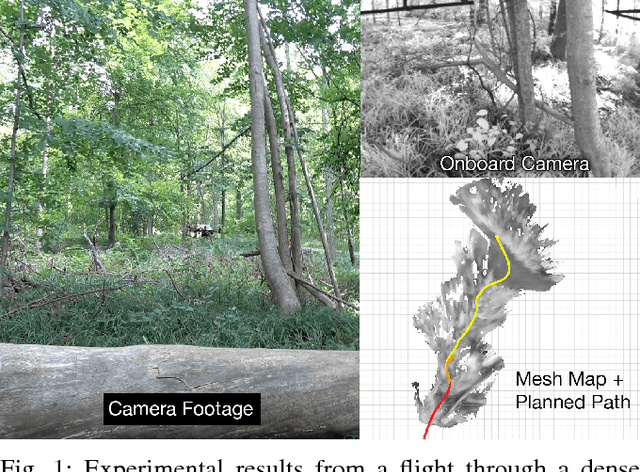

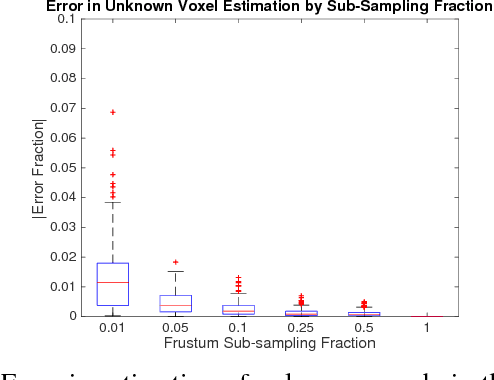
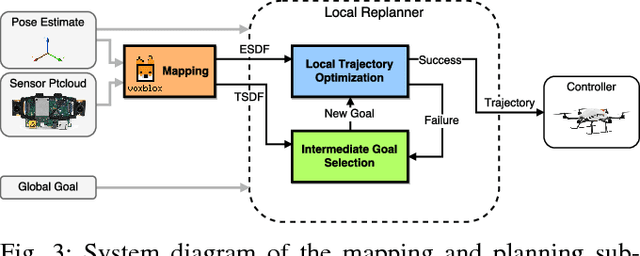
In order to enable Micro-Aerial Vehicles (MAVs) to assist in complex, unknown, unstructured environments, they must be able to navigate with guaranteed safety, even when faced with a cluttered environment they have no prior knowledge of. While trajectory optimization-based local planners have been shown to perform well in these cases, prior work either does not address how to deal with local minima in the optimization problem, or solves it by using an optimistic global planner. We present a conservative trajectory optimization-based local planner, coupled with a local exploration strategy that selects intermediate goals. We perform extensive simulations to show that this system performs better than the standard approach of using an optimistic global planner, and also outperforms doing a single exploration step when the local planner is stuck. The method is validated through experiments in a variety of highly cluttered environments including a dense forest. These experiments show the complete system running in real time fully onboard an MAV, mapping and replanning at 4 Hz.
A Data-driven Model for Interaction-aware Pedestrian Motion Prediction in Object Cluttered Environments
Feb 26, 2018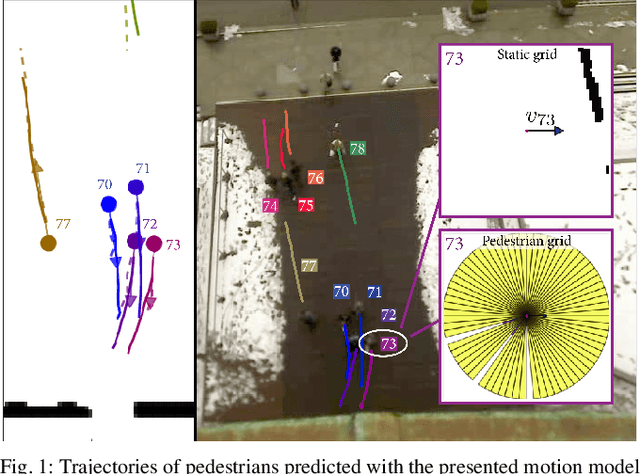
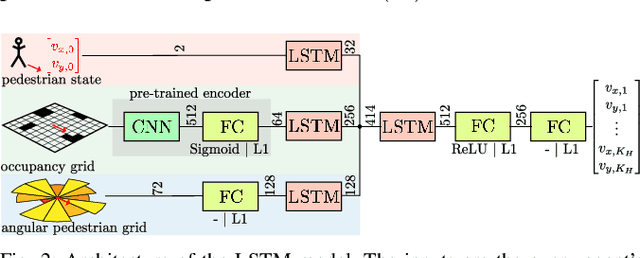
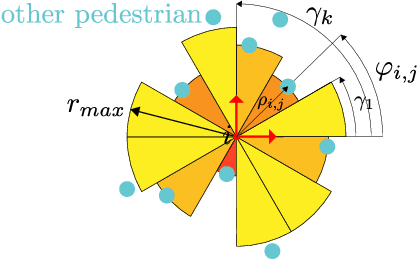
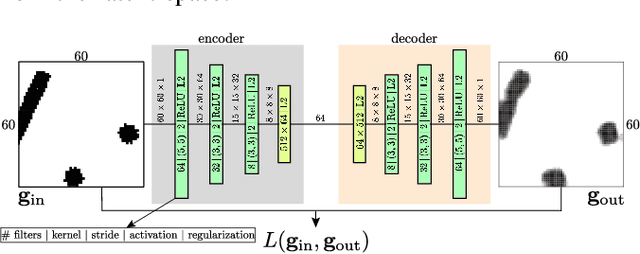
This paper reports on a data-driven, interaction-aware motion prediction approach for pedestrians in environments cluttered with static obstacles. When navigating in such workspaces shared with humans, robots need accurate motion predictions of the surrounding pedestrians. Human navigation behavior is mostly influenced by their surrounding pedestrians and by the static obstacles in their vicinity. In this paper we introduce a new model based on Long-Short Term Memory (LSTM) neural networks, which is able to learn human motion behavior from demonstrated data. To the best of our knowledge, this is the first approach using LSTMs, that incorporates both static obstacles and surrounding pedestrians for trajectory forecasting. As part of the model, we introduce a new way of encoding surrounding pedestrians based on a 1d-grid in polar angle space. We evaluate the benefit of interaction-aware motion prediction and the added value of incorporating static obstacles on both simulation and real-world datasets by comparing with state-of-the-art approaches. The results show, that our new approach outperforms the other approaches while being very computationally efficient and that taking into account static obstacles for motion predictions significantly improves the prediction accuracy, especially in cluttered environments.
X-View: Graph-Based Semantic Multi-View Localization
Feb 16, 2018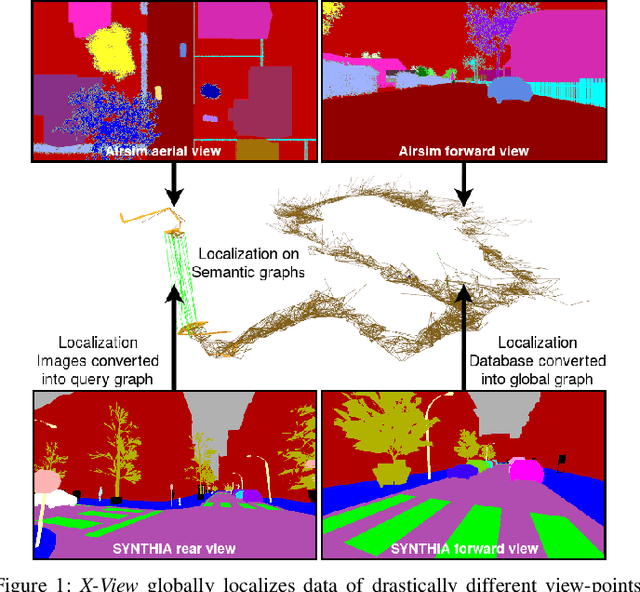
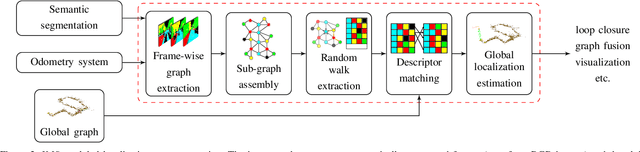
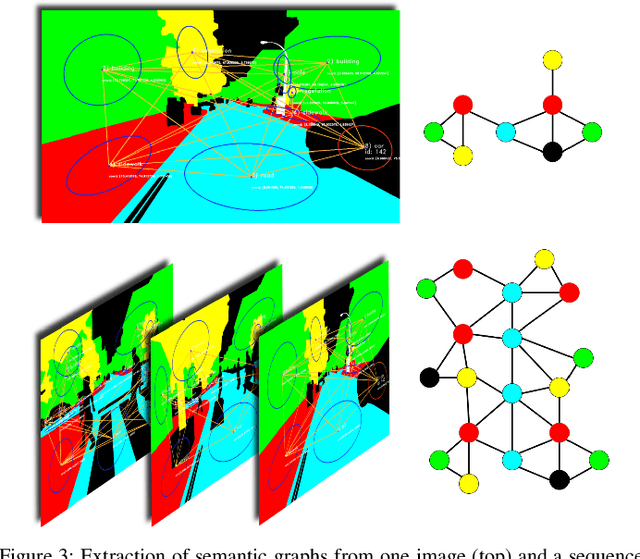
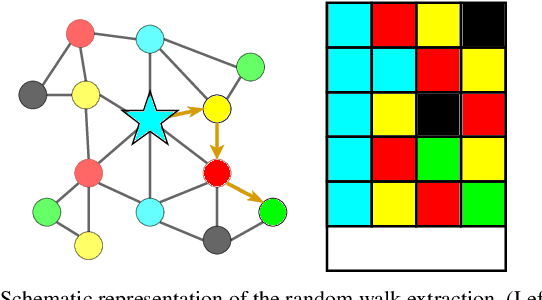
Global registration of multi-view robot data is a challenging task. Appearance-based global localization approaches often fail under drastic view-point changes, as representations have limited view-point invariance. This work is based on the idea that human-made environments contain rich semantics which can be used to disambiguate global localization. Here, we present X-View, a Multi-View Semantic Global Localization system. X-View leverages semantic graph descriptor matching for global localization, enabling localization under drastically different view-points. While the approach is general in terms of the semantic input data, we present and evaluate an implementation on visual data. We demonstrate the system in experiments on the publicly available SYNTHIA dataset, on a realistic urban dataset recorded with a simulator, and on real-world StreetView data. Our findings show that X-View is able to globally localize aerial-to-ground, and ground-to-ground robot data of drastically different view-points. Our approach achieves an accuracy of up to 85 % on global localizations in the multi-view case, while the benchmarked baseline appearance-based methods reach up to 75 %.
Why and How to Avoid the Flipped Quaternion Multiplication
Feb 05, 2018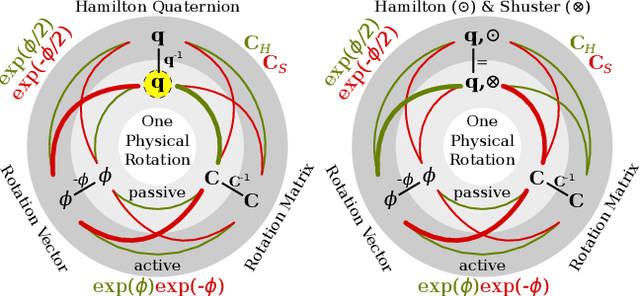
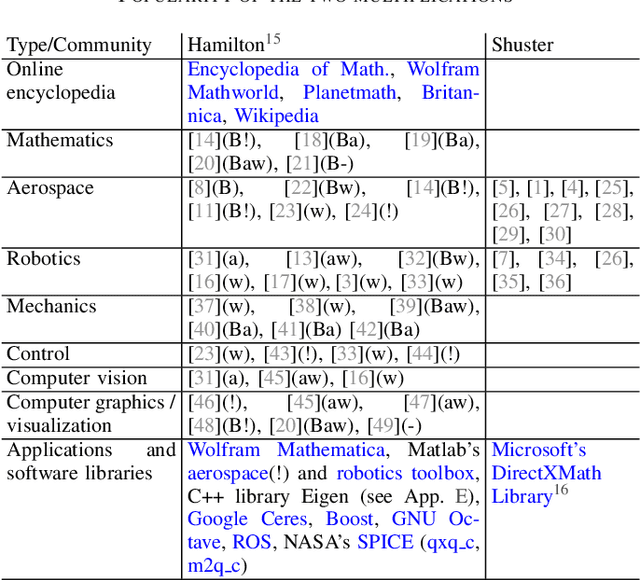
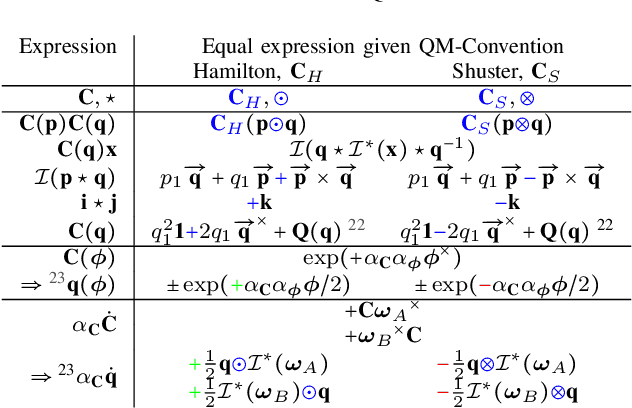
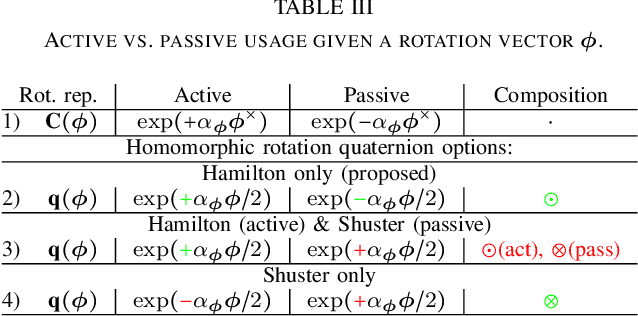
Over the last decades quaternions have become a crucial and very successful tool for attitude representation in robotics and aerospace. However, there is a major problem that is continuously causing trouble in practice when it comes to exchanging formulas or implementations: there are two quaternion multiplications in common use, Hamilton's original multiplication and its flipped version, which is often associated with NASA's Jet Propulsion Laboratory. We believe that this particular issue is completely avoidable and only exists today due to a lack of understanding. This paper explains the underlying problem for the popular passive world to body usage of rotation quaternions, and derives an alternative solution compatible with Hamilton's multiplication. Furthermore, it argues for entirely discontinuing the flipped multiplication. Additionally, it provides recipes for efficiently detecting relevant conventions and migrating formulas or algorithms between them.
Robust Collaborative Object Transportation Using Multiple MAVs
Nov 23, 2017

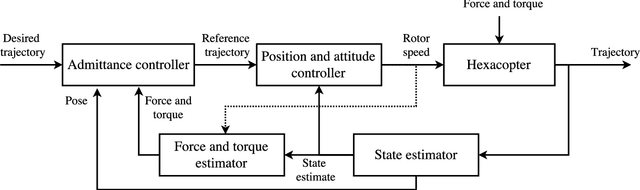
Collaborative object transportation using multiple Micro Aerial Vehicles (MAVs) with limited communication is a challenging problem. In this paper we address the problem of multiple MAVs mechanically coupled to a bulky object for transportation purposes without explicit communication between agents. The apparent physical properties of each agent are reshaped to achieve robustly stable transportation. Parametric uncertainties and unmodeled dynamics of each agent are quantified and techniques from robust control theory are employed to choose the physical parameters of each agent to guarantee stability. Extensive simulation analysis and experimental results show that the proposed method guarantees stability in worst case scenarios.
3D Registration of Aerial and Ground Robots for Disaster Response: An Evaluation of Features, Descriptors, and Transformation Estimation
Oct 25, 2017
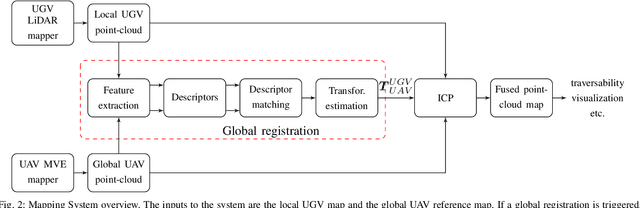
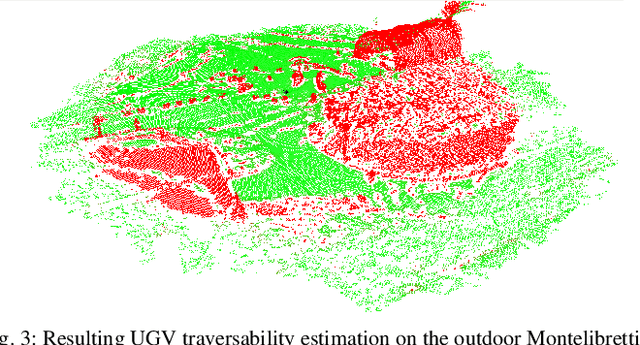

Global registration of heterogeneous ground and aerial mapping data is a challenging task. This is especially difficult in disaster response scenarios when we have no prior information on the environment and cannot assume the regular order of man-made environments or meaningful semantic cues. In this work we extensively evaluate different approaches to globally register UGV generated 3D point-cloud data from LiDAR sensors with UAV generated point-cloud maps from vision sensors. The approaches are realizations of different selections for: a) local features: key-points or segments; b) descriptors: FPFH, SHOT, or ESF; and c) transformation estimations: RANSAC or FGR. Additionally, we compare the results against standard approaches like applying ICP after a good prior transformation has been given. The evaluation criteria include the distance which a UGV needs to travel to successfully localize, the registration error, and the computational cost. In this context, we report our findings on effectively performing the task on two new Search and Rescue datasets. Our results have the potential to help the community take informed decisions when registering point-cloud maps from ground robots to those from aerial robots.
A Decentralized Multi-Agent Unmanned Aerial System to Search, Pick Up, and Relocate Objects
Sep 13, 2017
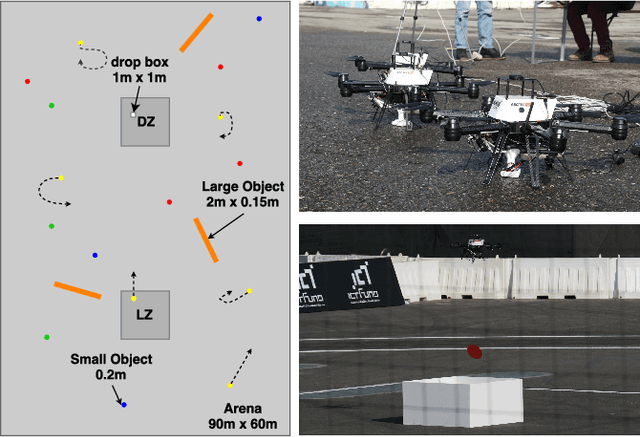

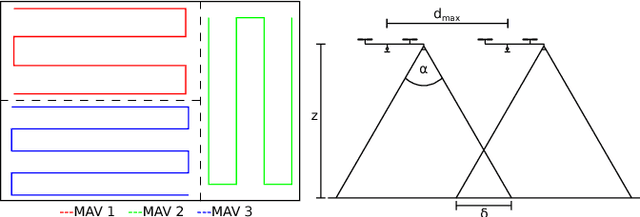
We present a fully integrated autonomous multi- robot aerial system for finding and collecting moving and static objects with unknown locations. This task addresses multiple relevant problems in search and rescue (SAR) robotics such as multi-agent aerial exploration, object detection and tracking, and aerial gripping. Usually, the community tackles these problems individually but the integration into a working system generates extra complexity which is rarely addressed. We show that this task can be solved reliably using only simple components. Our decentralized system uses accurate global state estimation, reactive collision avoidance, and sweep planning for multi-agent exploration. Objects are detected, tracked, and picked up using blob detection, inverse 3D-projection, Kalman filtering, visual-servoing, and a magnetic gripper. We evaluate the individual components of our system on the real platform. The full system has been deployed successfully in various public demonstrations, field tests, and the Mohamed Bin Zayed International Robotics Challenge 2017 (MBZIRC). Among the contestants we showed reliable performances and reached second place out of 17 in the individual challenge.
weedNet: Dense Semantic Weed Classification Using Multispectral Images and MAV for Smart Farming
Sep 11, 2017



Selective weed treatment is a critical step in autonomous crop management as related to crop health and yield. However, a key challenge is reliable, and accurate weed detection to minimize damage to surrounding plants. In this paper, we present an approach for dense semantic weed classification with multispectral images collected by a micro aerial vehicle (MAV). We use the recently developed encoder-decoder cascaded Convolutional Neural Network (CNN), Segnet, that infers dense semantic classes while allowing any number of input image channels and class balancing with our sugar beet and weed datasets. To obtain training datasets, we established an experimental field with varying herbicide levels resulting in field plots containing only either crop or weed, enabling us to use the Normalized Difference Vegetation Index (NDVI) as a distinguishable feature for automatic ground truth generation. We train 6 models with different numbers of input channels and condition (fine-tune) it to achieve about 0.8 F1-score and 0.78 Area Under the Curve (AUC) classification metrics. For model deployment, an embedded GPU system (Jetson TX2) is tested for MAV integration. Dataset used in this paper is released to support the community and future work.
Visual-inertial self-calibration on informative motion segments
Aug 08, 2017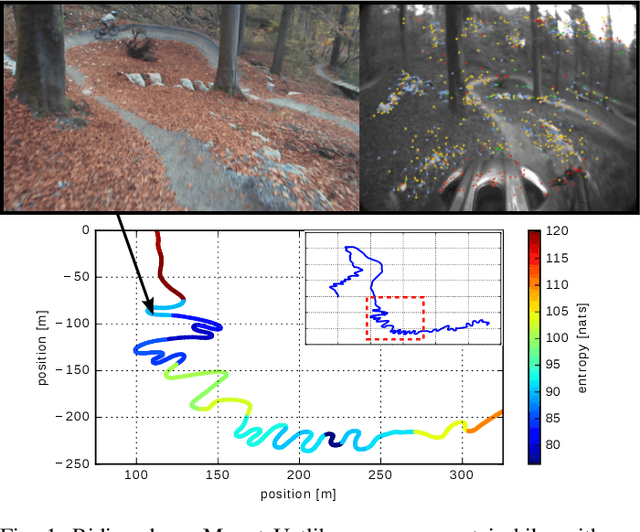
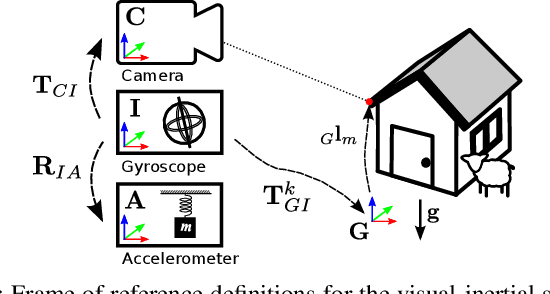
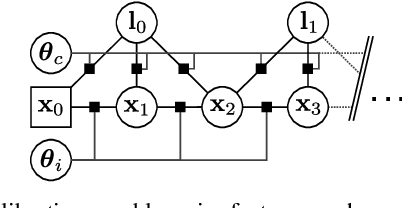
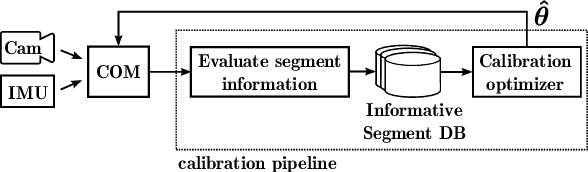
Environmental conditions and external effects, such as shocks, have a significant impact on the calibration parameters of visual-inertial sensor systems. Thus long-term operation of these systems cannot fully rely on factory calibration. Since the observability of certain parameters is highly dependent on the motion of the device, using short data segments at device initialization may yield poor results. When such systems are additionally subject to energy constraints, it is also infeasible to use full-batch approaches on a big dataset and careful selection of the data is of high importance. In this paper, we present a novel approach for resource efficient self-calibration of visual-inertial sensor systems. This is achieved by casting the calibration as a segment-based optimization problem that can be run on a small subset of informative segments. Consequently, the computational burden is limited as only a predefined number of segments is used. We also propose an efficient information-theoretic selection to identify such informative motion segments. In evaluations on a challenging dataset, we show our approach to significantly outperform state-of-the-art in terms of computational burden while maintaining a comparable accuracy.
Voxblox: Incremental 3D Euclidean Signed Distance Fields for On-Board MAV Planning
Apr 21, 2017
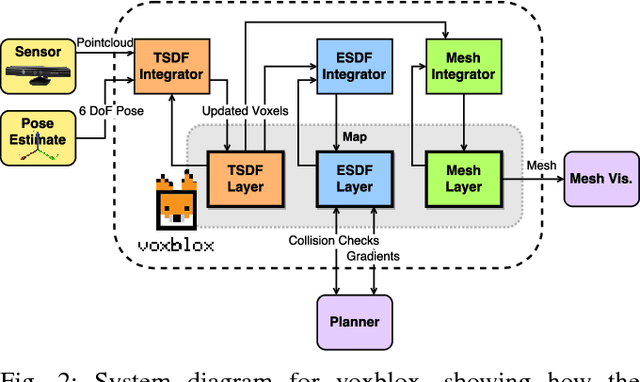
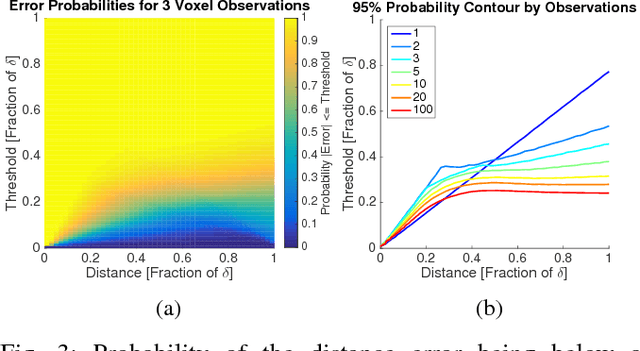
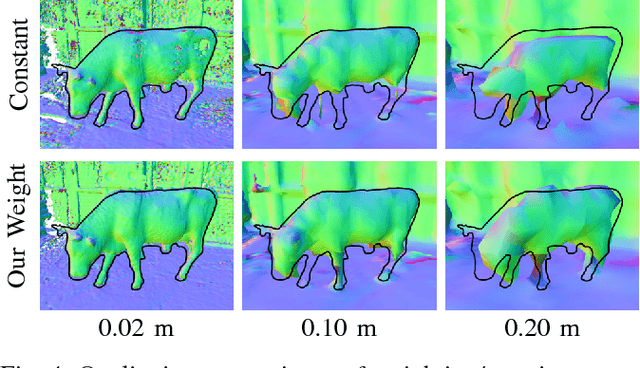
Micro Aerial Vehicles (MAVs) that operate in unstructured, unexplored environments require fast and flexible local planning, which can replan when new parts of the map are explored. Trajectory optimization methods fulfill these needs, but require obstacle distance information, which can be given by Euclidean Signed Distance Fields (ESDFs). We propose a method to incrementally build ESDFs from Truncated Signed Distance Fields (TSDFs), a common implicit surface representation used in computer graphics and vision. TSDFs are fast to build and smooth out sensor noise over many observations, and are designed to produce surface meshes. Meshes allow human operators to get a better assessment of the robot's environment, and set high-level mission goals. We show that we can build TSDFs faster than Octomaps, and that it is more accurate to build ESDFs out of TSDFs than occupancy maps. Our complete system, called voxblox, will be available as open source and runs in real-time on a single CPU core. We validate our approach on-board an MAV, by using our system with a trajectory optimization local planner, entirely on-board and in real-time.