 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the high score: Prosocial ability profiles of multi-agent populations
Sep 17, 2025The development and evaluation of social capabilities in AI agents require complex environments where competitive and cooperative behaviours naturally emerge. While game-theoretic properties can explain why certain teams or agent populations outperform others, more abstract behaviours, such as convention following, are harder to control in training and evaluation settings. The Melting Pot contest is a social AI evaluation suite designed to assess the cooperation capabilities of AI systems. In this paper, we apply a Bayesian approach known as Measurement Layouts to infer the capability profiles of multi-agent systems in the Melting Pot contest. We show that these capability profiles not only predict future performance within the Melting Pot suite but also reveal the underlying prosocial abilities of agents. Our analysis indicates that while higher prosocial capabilities sometimes correlate with better performance, this is not a universal trend-some lower-scoring agents exhibit stronger cooperation abilities. Furthermore, we find that top-performing contest submissions are more likely to achieve high scores in scenarios where prosocial capabilities are not required. These findings, together with reports that the contest winner used a hard-coded solution tailored to specific environments, suggest that at least one top-performing team may have optimised for conditions where cooperation was not necessary, potentially exploiting limitations in the evaluation framework. We provide recommendations for improving the annotation of cooperation demands and propose future research directions to account for biases introduced by different testing environments. Our results demonstrate that Measurement Layouts offer both strong predictive accuracy and actionable insights, contributing to a more transparent and generalisable approach to evaluating AI systems in complex social settings.
Identifying, Evaluating, and Mitigating Risks of AI Thought Partnerships
May 22, 2025Artificial Intelligence (AI) systems have historically been used as tools that execute narrowly defined tasks. Yet recent advances in AI have unlocked possibilities for a new class of models that genuinely collaborate with humans in complex reasoning, from conceptualizing problems to brainstorming solutions. Such AI thought partners enable novel forms of collaboration and extended cognition, yet they also pose major risks-including and beyond risks of typical AI tools and agents. In this commentary, we systematically identify risks of AI thought partners through a novel framework that identifies risks at multiple levels of analysis, including Real-time, Individual, and Societal risks arising from collaborative cognition (RISc). We leverage this framework to propose concrete metrics for risk evaluation, and finally suggest specific mitigation strategies for developers and policymakers. As AI thought partners continue to proliferate, these strategies can help prevent major harms and ensure that humans actively benefit from productive thought partnerships.
Conversational Complexity for Assessing Risk in Large Language Models
Sep 02, 2024



Large Language Models (LLMs) present a dual-use dilemma: they enable beneficial applications while harboring potential for harm, particularly through conversational interactions. Despite various safeguards, advanced LLMs remain vulnerable. A watershed case was Kevin Roose's notable conversation with Bing, which elicited harmful outputs after extended interaction. This contrasts with simpler early jailbreaks that produced similar content more easily, raising the question: How much conversational effort is needed to elicit harmful information from LLMs? We propose two measures: Conversational Length (CL), which quantifies the conversation length used to obtain a specific response, and Conversational Complexity (CC), defined as the Kolmogorov complexity of the user's instruction sequence leading to the response. To address the incomputability of Kolmogorov complexity, we approximate CC using a reference LLM to estimate the compressibility of user instructions. Applying this approach to a large red-teaming dataset, we perform a quantitative analysis examining the statistical distribution of harmful and harmless conversational lengths and complexities. Our empirical findings suggest that this distributional analysis and the minimisation of CC serve as valuable tools for understanding AI safety, offering insights into the accessibility of harmful information. This work establishes a foundation for a new perspective on LLM safety, centered around the algorithmic complexity of pathways to harm.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Evaluating General-Purpose AI with Psychometrics
Oct 25, 2023Artificial intelligence (AI) has witnessed an evolution from task-specific to general-purpose systems that trend toward human versatility. As AI systems begin to play pivotal roles in society, it is important to ensure that they are adequately evaluated. Current AI benchmarks typically assess performance on collections of specific tasks. This has drawbacks when used for assessing general-purpose AI systems. First, it is difficult to predict whether AI systems could complete a new task it has never seen or that did not previously exist. Second, these benchmarks often focus on overall performance metrics, potentially overlooking the finer details crucial for making informed decisions. Lastly, there are growing concerns about the reliability of existing benchmarks and questions about what is being measured. To solve these challenges, this paper suggests that psychometrics, the science of psychological measurement, should be placed at the core of evaluating general-purpose AI. Psychometrics provides a rigorous methodology for identifying and measuring the latent constructs that underlie performance across multiple tasks. We discuss its merits, warn against potential pitfalls, and propose a framework for putting it into practice. Finally, we explore future opportunities to integrate psychometrics with AI.
Dialectical language model evaluation: An initial appraisal of the commonsense spatial reasoning abilities of LLMs
Apr 22, 2023
Language models have become very popular recently and many claims have been made about their abilities, including for commonsense reasoning. Given the increasingly better results of current language models on previous static benchmarks for commonsense reasoning, we explore an alternative dialectical evaluation. The goal of this kind of evaluation is not to obtain an aggregate performance value but to find failures and map the boundaries of the system. Dialoguing with the system gives the opportunity to check for consistency and get more reassurance of these boundaries beyond anecdotal evidence. In this paper we conduct some qualitative investigations of this kind of evaluation for the particular case of spatial reasoning (which is a fundamental aspect of commonsense reasoning). We conclude with some suggestions for future work both to improve the capabilities of language models and to systematise this kind of dialectical evaluation.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Evaluating the Apperception Engine
Jul 09, 2020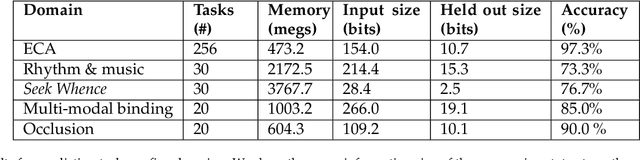

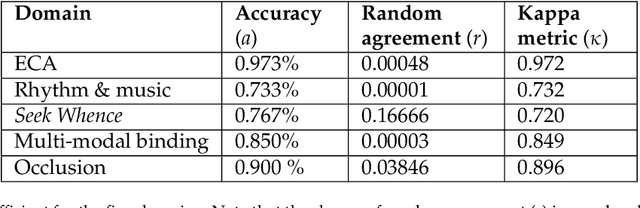

The Apperception Engine is an unsupervised learning system. Given a sequence of sensory inputs, it constructs a symbolic causal theory that both explains the sensory sequence and also satisfies a set of unity conditions. The unity conditions insist that the constituents of the theory - objects, properties, and laws - must be integrated into a coherent whole. Once a theory has been constructed, it can be applied to predict future sensor readings, retrodict earlier readings, or impute missing readings. In this paper, we evaluate the Apperception Engine in a diverse variety of domains, including cellular automata, rhythms and simple nursery tunes, multi-modal binding problems, occlusion tasks, and sequence induction intelligence tests. In each domain, we test our engine's ability to predict future sensor values, retrodict earlier sensor values, and impute missing sensory data. The engine performs well in all these domains, significantly outperforming neural net baselines and state of the art inductive logic programming systems. These results are significant because neural nets typically struggle to solve the binding problem (where information from different modalities must somehow be combined together into different aspects of one unified object) and fail to solve occlusion tasks (in which objects are sometimes visible and sometimes obscured from view). We note in particular that in the sequence induction intelligence tests, our system achieved human-level performance. This is notable because our system is not a bespoke system designed specifically to solve intelligence tests, but a general-purpose system that was designed to make sense of any sensory sequence.
Making sense of sensory input
Oct 05, 2019
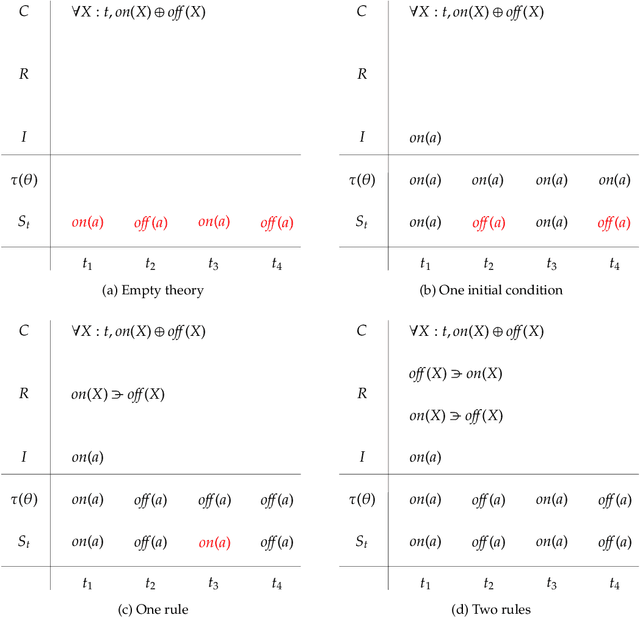
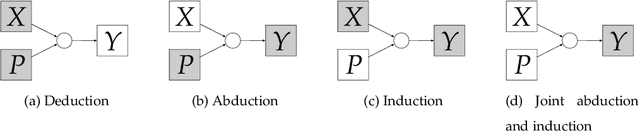
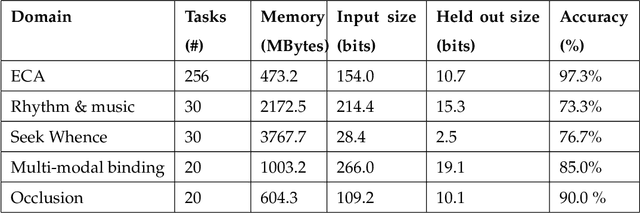
This paper attempts to answer a central question in unsupervised learning: what does it mean to "make sense" of a sensory sequence? In our formalization, making sense involves constructing a symbolic causal theory that explains the sensory sequence and satisfies a set of unity conditions. This model was inspired by Kant's discussion of the synthetic unity of apperception in the Critique of Pure Reason. On our account, making sense of sensory input is a type of program synthesis, but it is unsupervised program synthesis. Our second contribution is a computer implementation, the Apperception Engine, that was designed to satisfy the above requirements. Our system is able to produce interpretable human-readable causal theories from very small amounts of data, because of the strong inductive bias provided by the Kantian unity constraints. A causal theory produced by our system is able to predict future sensor readings, as well as retrodict earlier readings, and "impute" (fill in the blanks of) missing sensory readings, in any combination. We tested the engine in a diverse variety of domains, including cellular automata, rhythms and simple nursery tunes, multi-modal binding problems, occlusion tasks, and sequence induction IQ tests. In each domain, we test our engine's ability to predict future sensor values, retrodict earlier sensor values, and impute missing sensory data. The Apperception Engine performs well in all these domains, significantly out-performing neural net baselines. We note in particular that in the sequence induction IQ tasks, our system achieved human-level performance. This is notable because our system is not a bespoke system designed specifically to solve IQ tasks, but a general purpose apperception system that was designed to make sense of any sensory sequence.
Finite Biased Teaching with Infinite Concept Classes
Apr 19, 2018
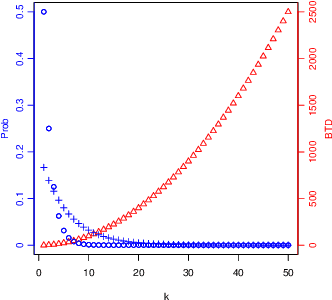
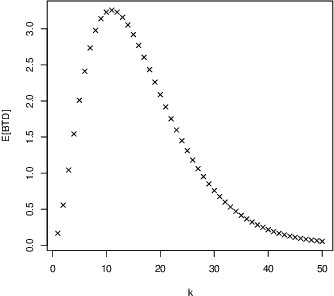

We investigate the teaching of infinite concept classes through the effect of the learning bias (which is used by the learner to prefer some concepts over others and by the teacher to devise the teaching examples) and the sampling bias (which determines how the concepts are sampled from the class). We analyse two important classes: Turing machines and finite-state machines. We derive bounds for the biased teaching dimension when the learning bias is derived from a complexity measure (Kolmogorov complexity and minimal number of states respectively) and analyse the sampling distributions that lead to finite expected biased teaching dimensions. We highlight the existing trade-off between the bound and the representativeness of the sample, and its implications for the understanding of what teaching rich concepts to machines entails.