 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis
May 14, 2022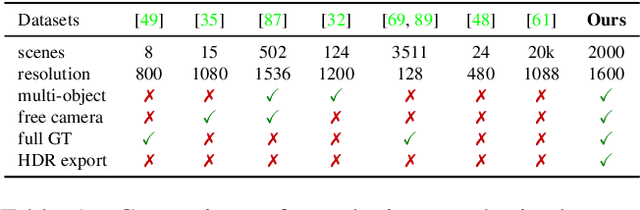


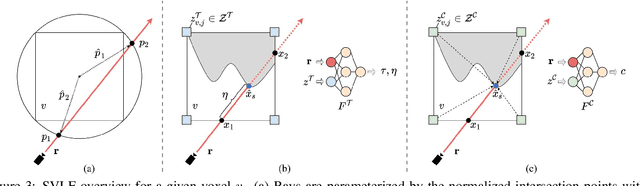
We present a large-scale synthetic dataset for novel view synthesis consisting of ~300k images rendered from nearly 2000 complex scenes using high-quality ray tracing at high resolution (1600 x 1600 pixels). The dataset is orders of magnitude larger than existing synthetic datasets for novel view synthesis, thus providing a large unified benchmark for both training and evaluation. Using 4 distinct sources of high-quality 3D meshes, the scenes of our dataset exhibit challenging variations in camera views, lighting, shape, materials, and textures. Because our dataset is too large for existing methods to process, we propose Sparse Voxel Light Field (SVLF), an efficient voxel-based light field approach for novel view synthesis that achieves comparable performance to NeRF on synthetic data, while being an order of magnitude faster to train and two orders of magnitude faster to render. SVLF achieves this speed by relying on a sparse voxel octree, careful voxel sampling (requiring only a handful of queries per ray), and reduced network structure; as well as ground truth depth maps at training time. Our dataset is generated by NViSII, a Python-based ray tracing renderer, which is designed to be simple for non-experts to use and share, flexible and powerful through its use of scripting, and able to create high-quality and physically-based rendered images. Experiments with a subset of our dataset allow us to compare standard methods like NeRF and mip-NeRF for single-scene modeling, and pixelNeRF for category-level modeling, pointing toward the need for future improvements in this area.
6-DoF Pose Estimation of Household Objects for Robotic Manipulation: An Accessible Dataset and Benchmark
Mar 11, 2022
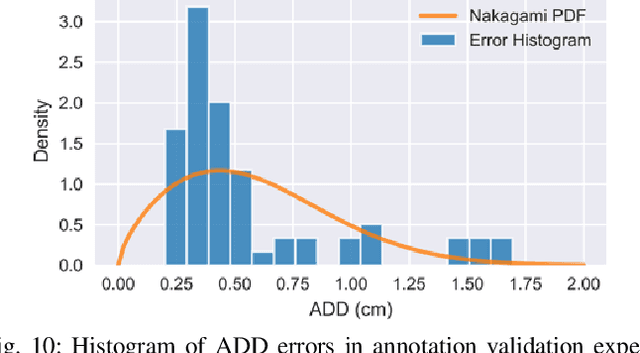
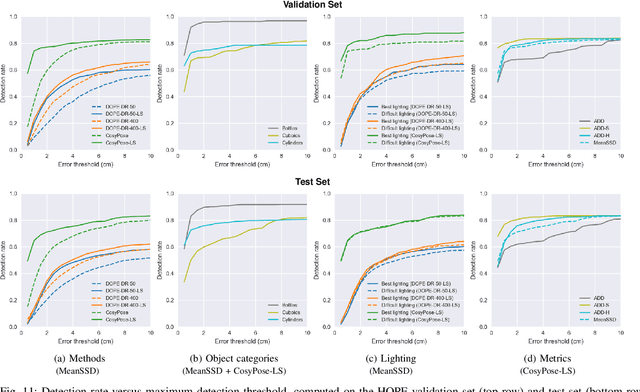
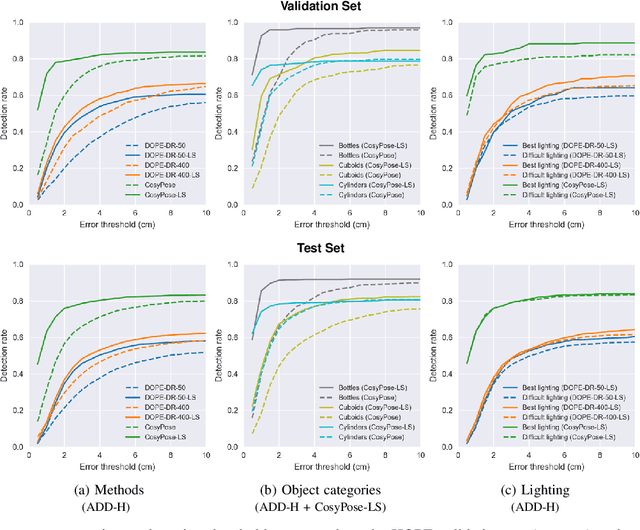
We present a new dataset for 6-DoF pose estimation of known objects, with a focus on robotic manipulation research. We propose a set of toy grocery objects, whose physical instantiations are readily available for purchase and are appropriately sized for robotic grasping and manipulation. We provide 3D scanned textured models of these objects, suitable for generating synthetic training data, as well as RGBD images of the objects in challenging, cluttered scenes exhibiting partial occlusion, extreme lighting variations, multiple instances per image, and a large variety of poses. Using semi-automated RGBD-to-model texture correspondences, the images are annotated with ground truth poses that were verified empirically to be accurate to within a few millimeters. We also propose a new pose evaluation metric called {ADD-H} based upon the Hungarian assignment algorithm that is robust to symmetries in object geometry without requiring their explicit enumeration. We share pre-trained pose estimators for all the toy grocery objects, along with their baseline performance on both validation and test sets. We offer this dataset to the community to help connect the efforts of computer vision researchers with the needs of roboticists.
Watch It Move: Unsupervised Discovery of 3D Joints for Re-Posing of Articulated Objects
Dec 21, 2021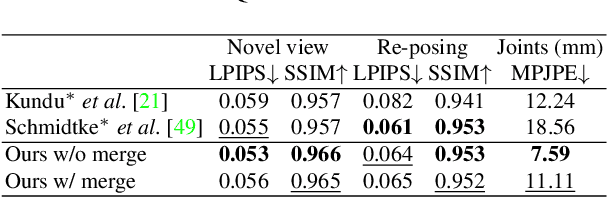
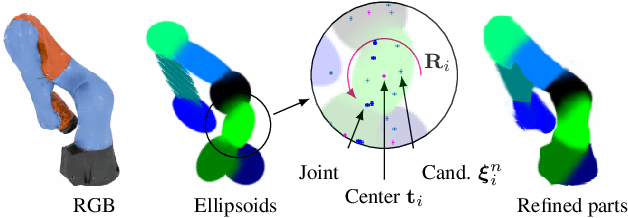
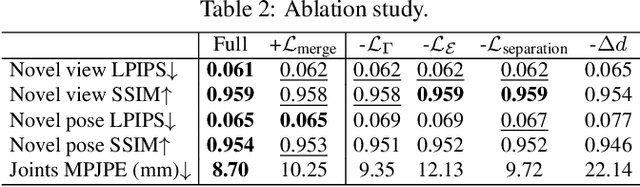
Rendering articulated objects while controlling their poses is critical to applications such as virtual reality or animation for movies. Manipulating the pose of an object, however, requires the understanding of its underlying structure, that is, its joints and how they interact with each other. Unfortunately, assuming the structure to be known, as existing methods do, precludes the ability to work on new object categories. We propose to learn both the appearance and the structure of previously unseen articulated objects by observing them move from multiple views, with no additional supervision, such as joints annotations, or information about the structure. Our insight is that adjacent parts that move relative to each other must be connected by a joint. To leverage this observation, we model the object parts in 3D as ellipsoids, which allows us to identify joints. We combine this explicit representation with an implicit one that compensates for the approximation introduced. We show that our method works for different structures, from quadrupeds, to single-arm robots, to humans.
Efficient Geometry-aware 3D Generative Adversarial Networks
Dec 15, 2021
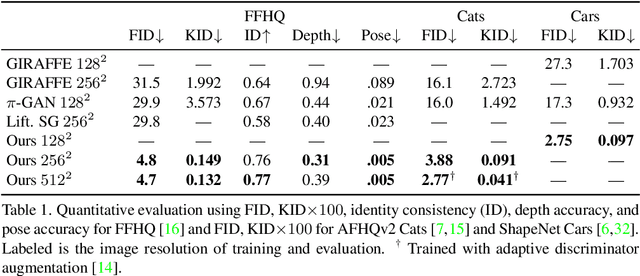
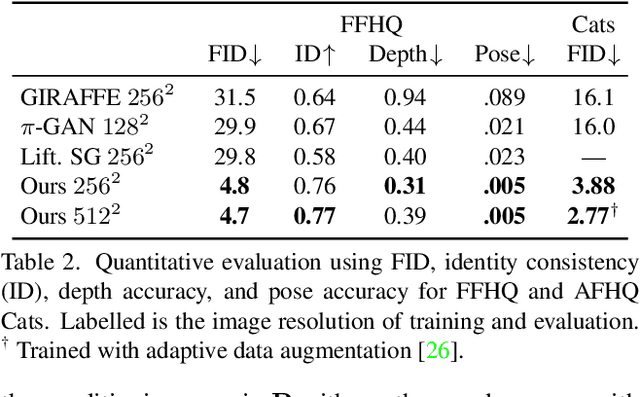
Unsupervised generation of high-quality multi-view-consistent images and 3D shapes using only collections of single-view 2D photographs has been a long-standing challenge. Existing 3D GANs are either compute-intensive or make approximations that are not 3D-consistent; the former limits quality and resolution of the generated images and the latter adversely affects multi-view consistency and shape quality. In this work, we improve the computational efficiency and image quality of 3D GANs without overly relying on these approximations. For this purpose, we introduce an expressive hybrid explicit-implicit network architecture that, together with other design choices, synthesizes not only high-resolution multi-view-consistent images in real time but also produces high-quality 3D geometry. By decoupling feature generation and neural rendering, our framework is able to leverage state-of-the-art 2D CNN generators, such as StyleGAN2, and inherit their efficiency and expressiveness. We demonstrate state-of-the-art 3D-aware synthesis with FFHQ and AFHQ Cats, among other experiments.
Single-stage Keypoint-based Category-level Object Pose Estimation from an RGB Image
Sep 13, 2021
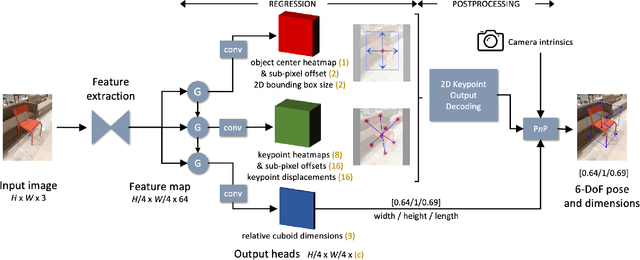

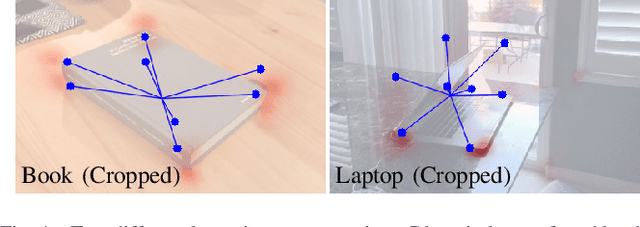
Prior work on 6-DoF object pose estimation has largely focused on instance-level processing, in which a textured CAD model is available for each object being detected. Category-level 6-DoF pose estimation represents an important step toward developing robotic vision systems that operate in unstructured, real-world scenarios. In this work, we propose a single-stage, keypoint-based approach for category-level object pose estimation that operates on unknown object instances within a known category using a single RGB image as input. The proposed network performs 2D object detection, detects 2D keypoints, estimates 6-DoF pose, and regresses relative bounding cuboid dimensions. These quantities are estimated in a sequential fashion, leveraging the recent idea of convGRU for propagating information from easier tasks to those that are more difficult. We favor simplicity in our design choices: generic cuboid vertex coordinates, single-stage network, and monocular RGB input. We conduct extensive experiments on the challenging Objectron benchmark, outperforming state-of-the-art methods on the 3D IoU metric (27.6% higher than the MobilePose single-stage approach and 7.1% higher than the related two-stage approach).
NViSII: A Scriptable Tool for Photorealistic Image Generation
May 28, 2021

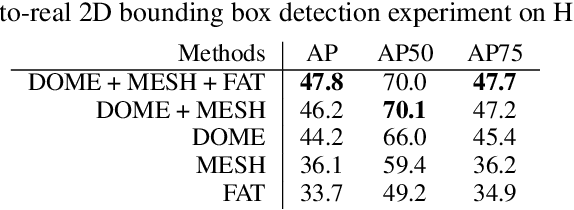

We present a Python-based renderer built on NVIDIA's OptiX ray tracing engine and the OptiX AI denoiser, designed to generate high-quality synthetic images for research in computer vision and deep learning. Our tool enables the description and manipulation of complex dynamic 3D scenes containing object meshes, materials, textures, lighting, volumetric data (e.g., smoke), and backgrounds. Metadata, such as 2D/3D bounding boxes, segmentation masks, depth maps, normal maps, material properties, and optical flow vectors, can also be generated. In this work, we discuss design goals, architecture, and performance. We demonstrate the use of data generated by path tracing for training an object detector and pose estimator, showing improved performance in sim-to-real transfer in situations that are difficult for traditional raster-based renderers. We offer this tool as an easy-to-use, performant, high-quality renderer for advancing research in synthetic data generation and deep learning.
DexYCB: A Benchmark for Capturing Hand Grasping of Objects
Apr 09, 2021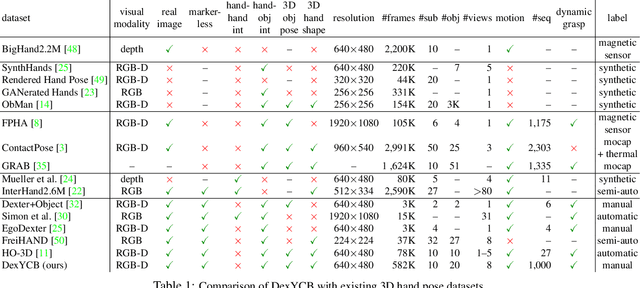

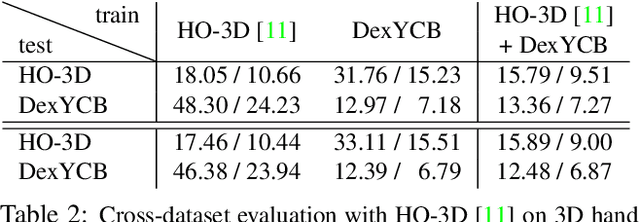

We introduce DexYCB, a new dataset for capturing hand grasping of objects. We first compare DexYCB with a related one through cross-dataset evaluation. We then present a thorough benchmark of state-of-the-art approaches on three relevant tasks: 2D object and keypoint detection, 6D object pose estimation, and 3D hand pose estimation. Finally, we evaluate a new robotics-relevant task: generating safe robot grasps in human-to-robot object handover. Dataset and code are available at https://dex-ycb.github.io.
Multi-view Fusion for Multi-level Robotic Scene Understanding
Mar 25, 2021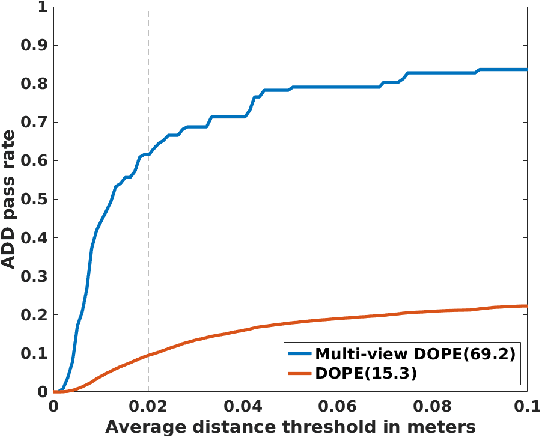

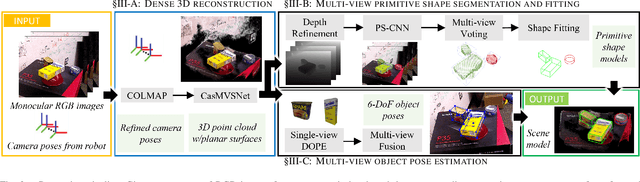

We present a system for multi-level scene awareness for robotic manipulation. Given a sequence of camera-in-hand RGB images, the system calculates three types of information: 1) a point cloud representation of all the surfaces in the scene, for the purpose of obstacle avoidance. 2) the rough pose of unknown objects from categories corresponding to primitive shapes (e.g., cuboids and cylinders), and 3) full 6-DoF pose of known objects. By developing and fusing recent techniques in these domains, we provide a rich scene representation for robot awareness. We demonstrate the importance of each of these modules, their complementary nature, and the potential benefits of the system in the context of robotic manipulation.
Hierarchical Planning for Long-Horizon Manipulation with Geometric and Symbolic Scene Graphs
Dec 14, 2020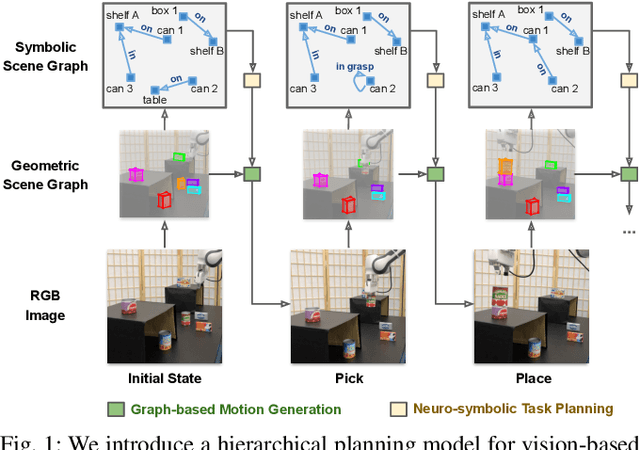
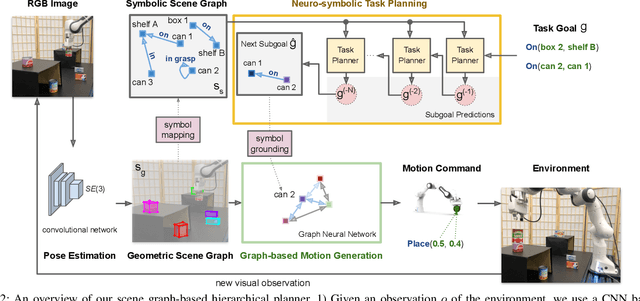

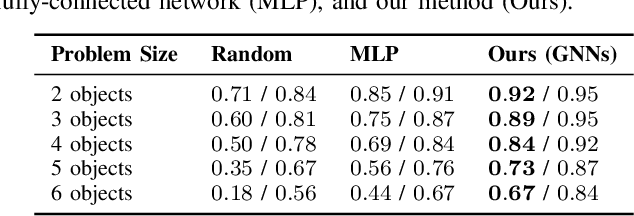
We present a visually grounded hierarchical planning algorithm for long-horizon manipulation tasks. Our algorithm offers a joint framework of neuro-symbolic task planning and low-level motion generation conditioned on the specified goal. At the core of our approach is a two-level scene graph representation, namely geometric scene graph and symbolic scene graph. This hierarchical representation serves as a structured, object-centric abstraction of manipulation scenes. Our model uses graph neural networks to process these scene graphs for predicting high-level task plans and low-level motions. We demonstrate that our method scales to long-horizon tasks and generalizes well to novel task goals. We validate our method in a kitchen storage task in both physical simulation and the real world. Our experiments show that our method achieved over 70% success rate and nearly 90% of subgoal completion rate on the real robot while being four orders of magnitude faster in computation time compared to standard search-based task-and-motion planner.
Fast Uncertainty Quantification for Deep Object Pose Estimation
Nov 16, 2020


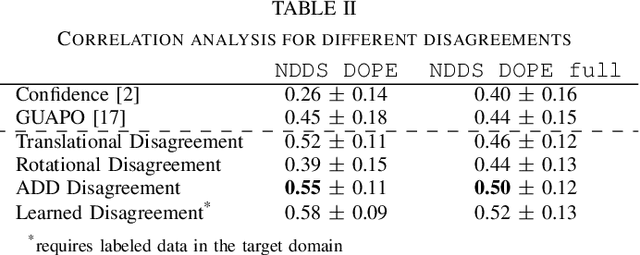
Deep learning-based object pose estimators are often unreliable and overconfident especially when the input image is outside the training domain, for instance, with sim2real transfer. Efficient and robust uncertainty quantification (UQ) in pose estimators is critically needed in many robotic tasks. In this work, we propose a simple, efficient, and plug-and-play UQ method for 6-DoF object pose estimation. We ensemble 2-3 pre-trained models with different neural network architectures and/or training data sources, and compute their average pairwise disagreement against one another to obtain the uncertainty quantification. We propose four disagreement metrics, including a learned metric, and show that the average distance (ADD) is the best learning-free metric and it is only slightly worse than the learned metric, which requires labeled target data. Our method has several advantages compared to the prior art: 1) our method does not require any modification of the training process or the model inputs; and 2) it needs only one forward pass for each model. We evaluate the proposed UQ method on three tasks where our uncertainty quantification yields much stronger correlations with pose estimation errors than the baselines. Moreover, in a real robot grasping task, our method increases the grasping success rate from 35% to 90%.