 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Reward Learning for Co-Robotic Vision Based Exploration in Bandwidth Limited Environments
Mar 10, 2020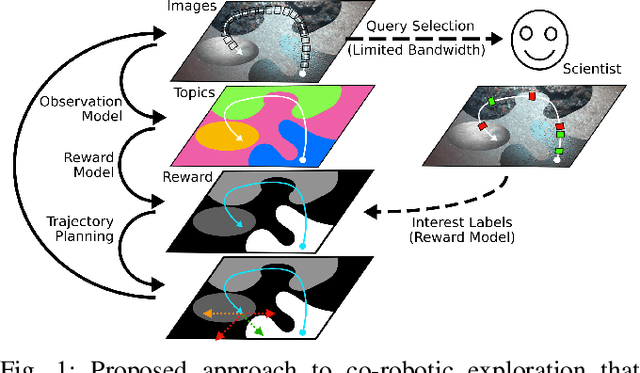
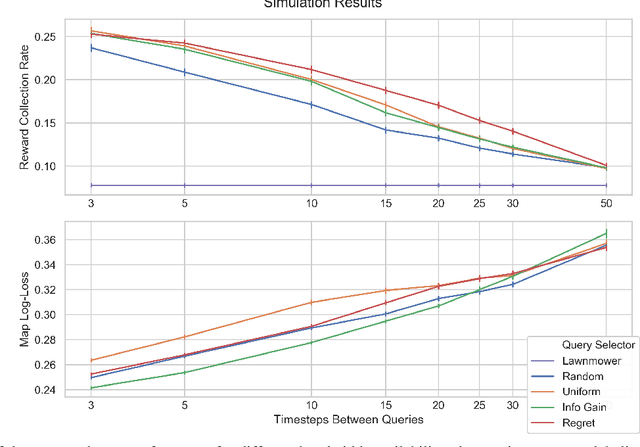
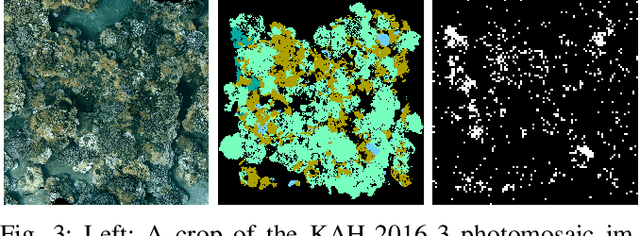
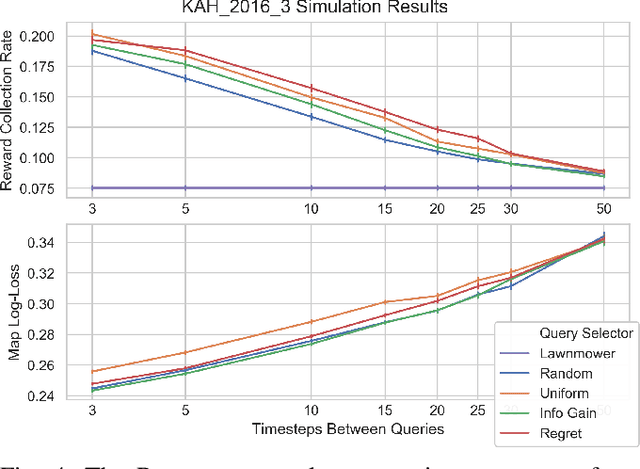
We present a novel POMDP problem formulation for a robot that must autonomously decide where to go to collect new and scientifically relevant images given a limited ability to communicate with its human operator. From this formulation we derive constraints and design principles for the observation model, reward model, and communication strategy of such a robot, exploring techniques to deal with the very high-dimensional observation space and scarcity of relevant training data. We introduce a novel active reward learning strategy based on making queries to help the robot minimize path "regret" online, and evaluate it for suitability in autonomous visual exploration through simulations. We demonstrate that, in some bandwidth-limited environments, this novel regret-based criterion enables the robotic explorer to collect up to 17% more reward per mission than the next-best criterion.
Asynchronous and Parallel Distributed Pose Graph Optimization
Mar 06, 2020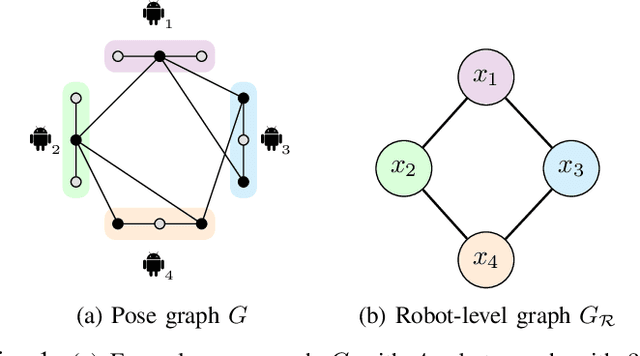
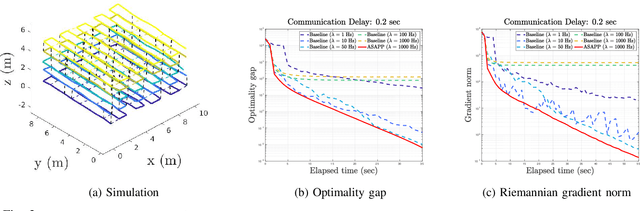
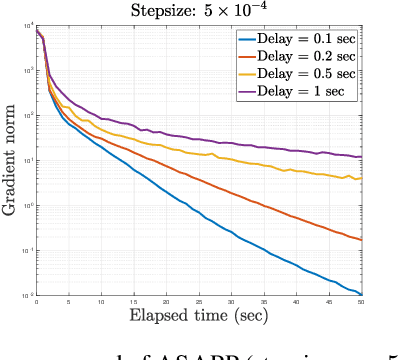
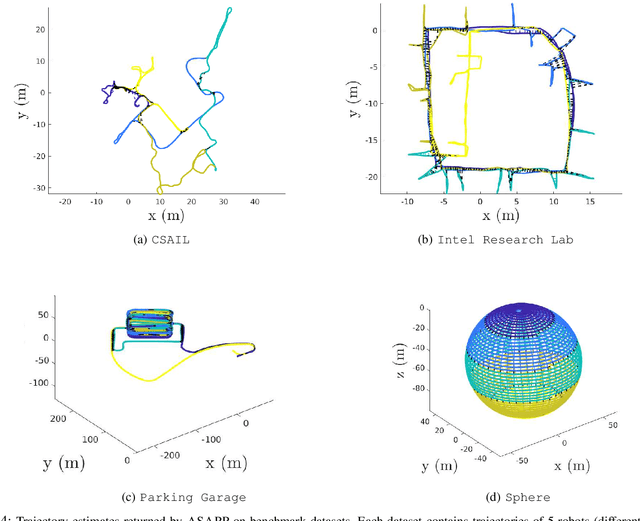
We present Asynchronous Stochastic Parallel Pose Graph Optimization (ASAPP), the first asynchronous algorithm for distributed pose graph optimization (PGO) in multi-robot simultaneous localization and mapping. By enabling robots to optimize their local trajectory estimates without synchronization, ASAPP offers resiliency against communication delays and alleviates the need to wait for stragglers in the network. Furthermore, the same algorithm can be used to solve the so-called rank-restricted semidefinite relaxations of PGO, a crucial class of non-convex Riemannian optimization problems at the center of recent PGO solvers with global optimality guarantees. Under bounded delay, we establish the global first-order convergence of ASAPP using a sufficiently small stepsize. The derived stepsize depends on the worst-case delay and inherent problem sparsity, and furthermore matches known result for synchronous algorithms when delay is zero. Numerical evaluations on both simulated and real-world SLAM datasets demonstrate the speedup achieved with ASAPP and show the algorithm's resilience against a wide range of communication delays in practice.
Touch the Wind: Simultaneous Airflow, Drag and Interaction Sensing on a Multirotor
Mar 04, 2020
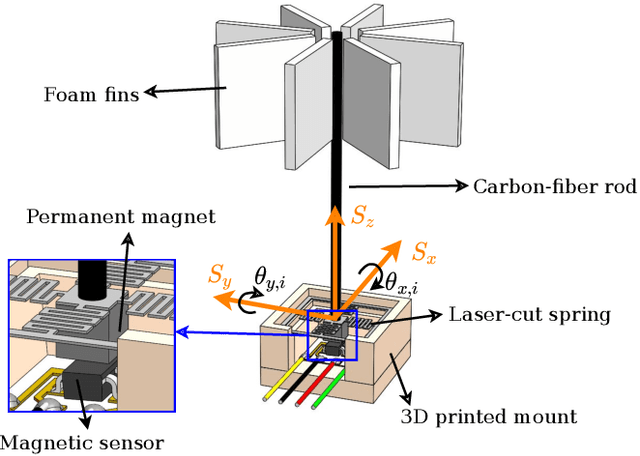
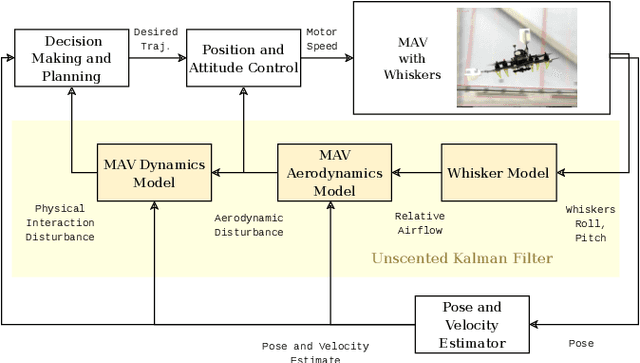
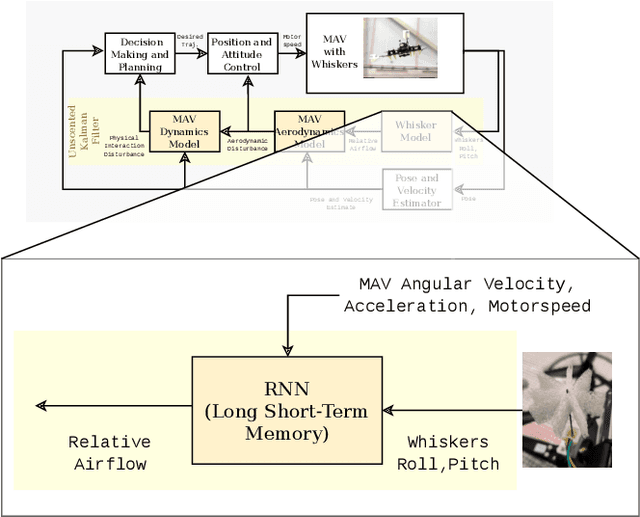
Disturbance estimation for Micro Aerial Vehicles (MAVs) is crucial for robustness and safety. In this paper, we use novel, bio-inspired airflow sensors to measure the airflow acting on a MAV, and we fuse this information in an Unscented Kalman Filter (UKF) to simultaneously estimate the three-dimensional wind vector, the drag force, and other interaction forces (e.g. due to collisions, interaction with a human) acting on the robot. To this end, we present and compare a fully model-based and a deep learning-based strategy. The model-based approach considers the MAV and airflow sensor dynamics and its interaction with the wind, while the deep learning-based strategy uses a Long Short-Term Memory (LSTM) neural network to obtain an estimate of the relative airflow, which is then fused in the proposed filter. We validate our methods in hardware experiments, showing that we can accurately estimate relative airflow of up to 4 m/s, and we can differentiate drag and interaction force.
A Distributed Pipeline for Scalable, Deconflicted Formation Flying
Mar 04, 2020
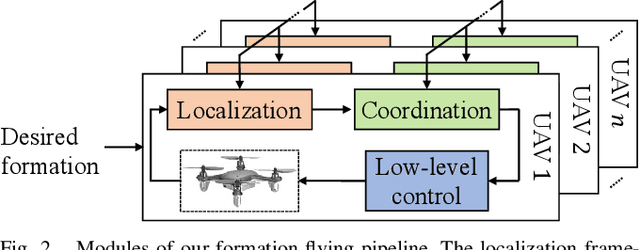

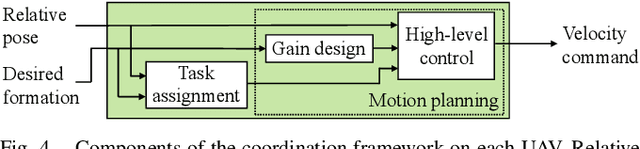
Reliance on external localization infrastructure and centralized coordination are main limiting factors for formation flying of vehicles in large numbers and in unprepared environments. While solutions using onboard localization address the dependency on external infrastructure, the associated coordination strategies typically lack collision avoidance and scalability. To address these shortcomings, we present a unified pipeline with onboard localization and a distributed, collision-free motion planning strategy that scales to a large number of vehicles. Since distributed collision avoidance strategies are known to result in gridlock, we also present a decentralized task assignment solution to deconflict vehicles. We experimentally validate our pipeline in simulation and hardware. The results show that our approach for solving the optimization problem associated with motion planning gives solutions within seconds in cases where general purpose solvers fail due to high complexity. In addition, our lightweight assignment strategy leads to successful and quicker formation convergence in 96-100% of all trials, whereas indefinite gridlocks occur without it for 33-50% of trials. By enabling large-scale, deconflicted coordination, this pipeline should help pave the way for anytime, anywhere deployment of aerial swarms.
Scaling Up Multiagent Reinforcement Learning for Robotic Systems: Learn an Adaptive Sparse Communication Graph
Mar 03, 2020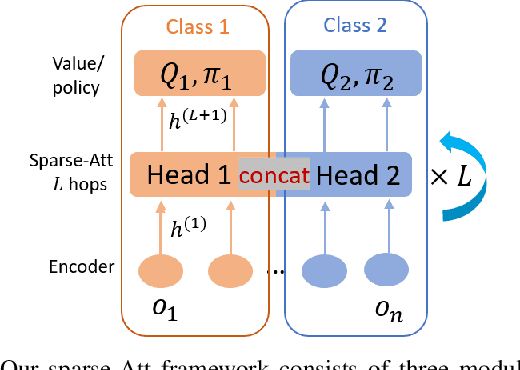
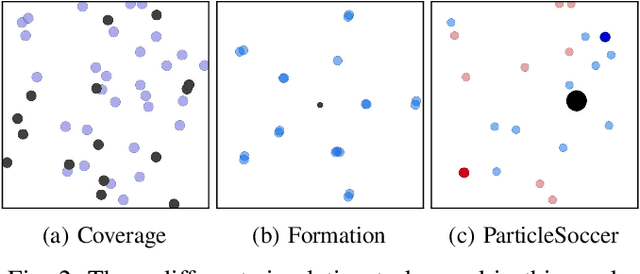
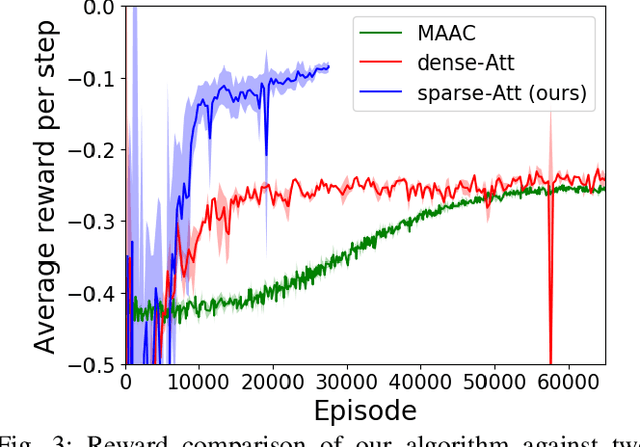
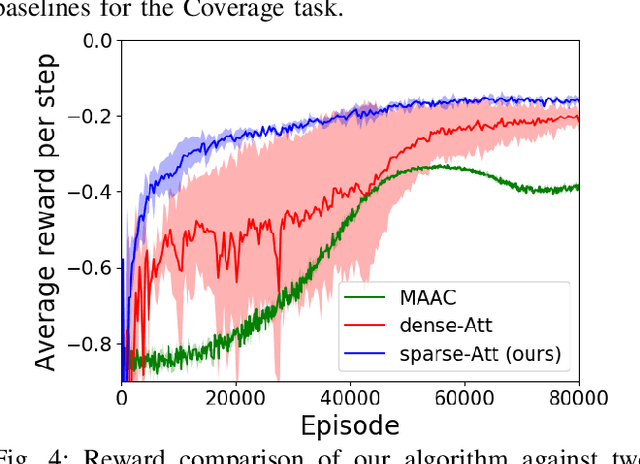
The complexity of multiagent reinforcement learning (MARL) in multiagent systems increases exponentially with respect to the agent number. This scalability issue prevents MARL from being applied in large-scale multiagent systems. However, one critical feature in MARL that is often neglected is that the interactions between agents are quite sparse. Without exploiting this sparsity structure, existing works aggregate information from all of the agents and thus have a high sample complexity. To address this issue, we propose an adaptive sparse attention mechanism by generalizing a sparsity-inducing activation function. Then a sparse communication graph in MARL is learned by graph neural networks based on this new attention mechanism. Through this sparsity structure, the agents can communicate in an effective as well as efficient way via only selectively attending to agents that matter the most and thus the scale of the MARL problem is reduced with little optimality compromised. Comparative results show that our algorithm can learn an interpretable sparse structure and outperforms previous works by a significant margin on applications involving a large-scale multiagent system.
R-MADDPG for Partially Observable Environments and Limited Communication
Feb 18, 2020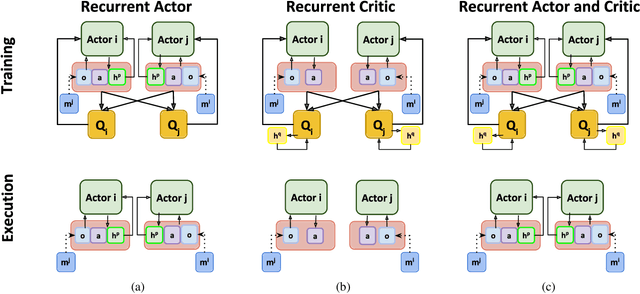
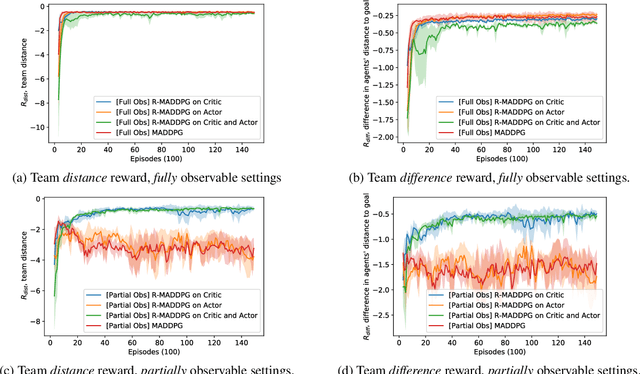

There are several real-world tasks that would benefit from applying multiagent reinforcement learning (MARL) algorithms, including the coordination among self-driving cars. The real world has challenging conditions for multiagent learning systems, such as its partial observable and nonstationary nature. Moreover, if agents must share a limited resource (e.g. network bandwidth) they must all learn how to coordinate resource use. This paper introduces a deep recurrent multiagent actor-critic framework (R-MADDPG) for handling multiagent coordination under partial observable set-tings and limited communication. We investigate recurrency effects on performance and communication use of a team of agents. We demonstrate that the resulting framework learns time dependencies for sharing missing observations, handling resource limitations, and developing different communication patterns among agents.
* Reinforcement Learning for Real Life (RL4RealLife) Workshop in the 36th International Conference on Machine Learning, Long Beach, California, USA, 2019
Multi-agent Motion Planning for Dense and Dynamic Environments via Deep Reinforcement Learning
Jan 18, 2020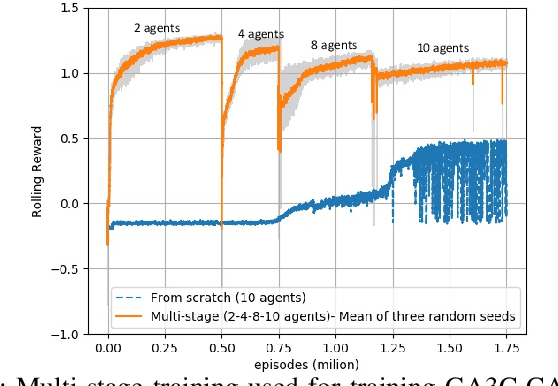
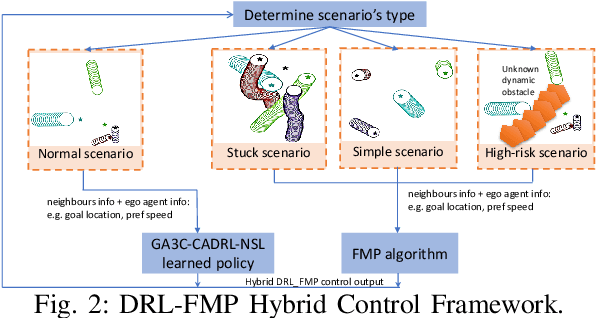
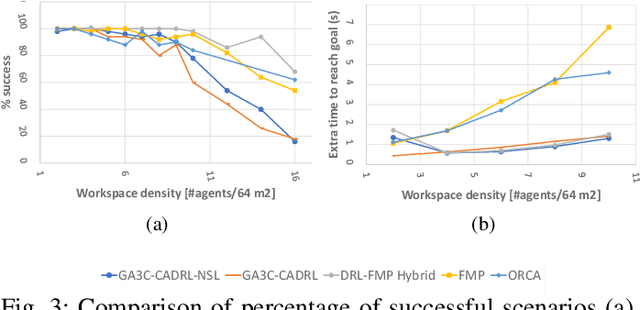
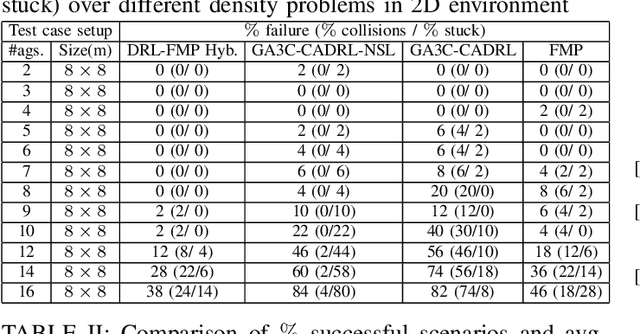
This paper introduces a hybrid algorithm of deep reinforcement learning (RL) and Force-based motion planning (FMP) to solve distributed motion planning problem in dense and dynamic environments. Individually, RL and FMP algorithms each have their own limitations. FMP is not able to produce time-optimal paths and existing RL solutions are not able to produce collision-free paths in dense environments. Therefore, we first tried improving the performance of recent RL approaches by introducing a new reward function that not only eliminates the requirement of a pre supervised learning (SL) step but also decreases the chance of collision in crowded environments. That improved things, but there were still a lot of failure cases. So, we developed a hybrid approach to leverage the simpler FMP approach in stuck, simple and high-risk cases, and continue using RL for normal cases in which FMP can't produce optimal path. Also, we extend GA3C-CADRL algorithm to 3D environment. Simulation results show that the proposed algorithm outperforms both deep RL and FMP algorithms and produces up to 50% more successful scenarios than deep RL and up to 75% less extra time to reach goal than FMP.
FASTER: Fast and Safe Trajectory Planner for Flights in Unknown Environments
Jan 09, 2020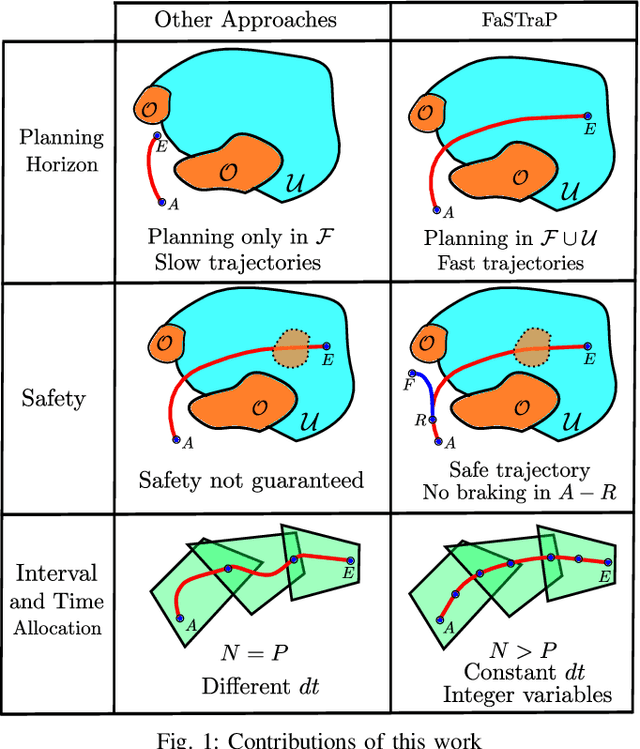
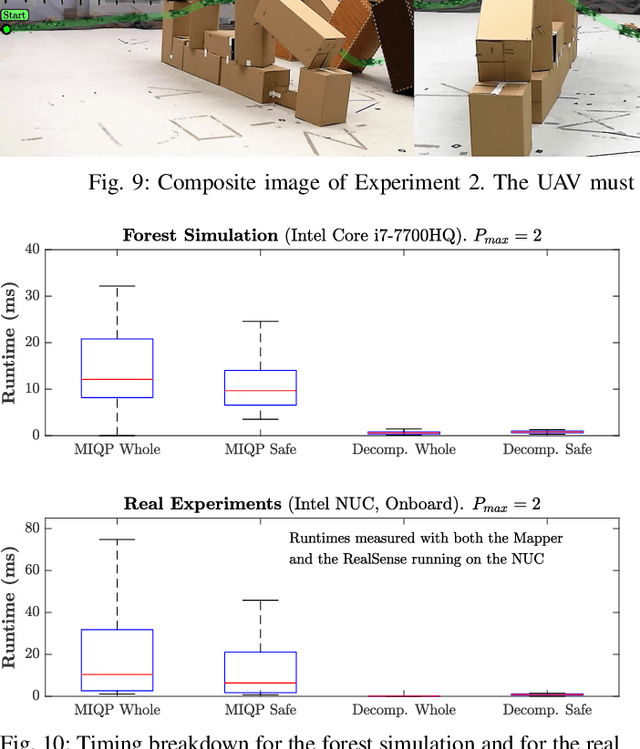
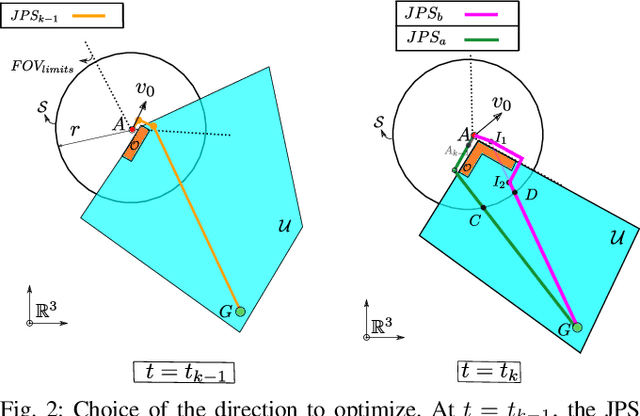
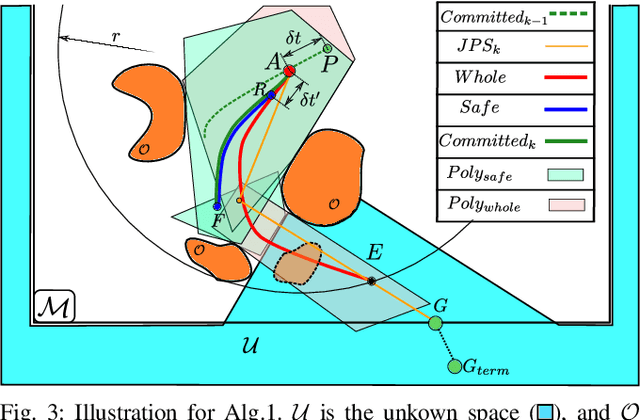
Planning high-speed trajectories for UAVs in unknown environments requires algorithmic techniques that enable fast reaction times to guarantee safety as more information about the environment becomes available. The standard approach to ensure safety is to enforce a "stop" condition in the free-known space. However, this can severely limit the speed of the vehicle, especially in situations where much of the world is unknown. Moreover, the ad-hoc time and interval allocation scheme usually imposed on the trajectory also leads to conservative and slower trajectories. This work proposes FASTER (Fast and Safe Trajectory Planner) to ensure safety without sacrificing speed. FASTER obtains high-speed trajectories by enabling the local planner to optimize in both the free-known and unknown spaces. Safety guarantees are ensured by always having a feasible, safe back-up trajectory in the free-known space at the start of each replanning step. The Mixed Integer Quadratic Program formulation proposed allows the solver to choose the trajectory interval allocation, and the time allocation is found by a line search algorithm initialized with a heuristic computed from the previous replanning iteration. This proposed algorithm is tested extensively both in simulation and in real hardware, showing agile flights in unknown cluttered environments with velocities up to 7.8 m/s. To demonstrate the generality of the proposed framework, FASTER is also applied to a skid-steer robot, and the maximum speed specified for the robot (2 m/s) is achieved in real hardware experiments.
Block-Coordinate Descent on the Riemannian Staircase for Certifiably Correct Distributed Rotation and Pose Synchronization
Dec 21, 2019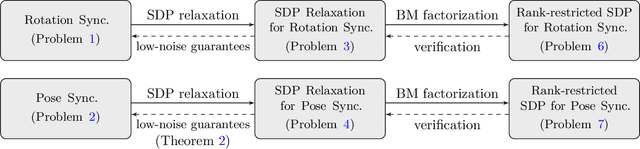
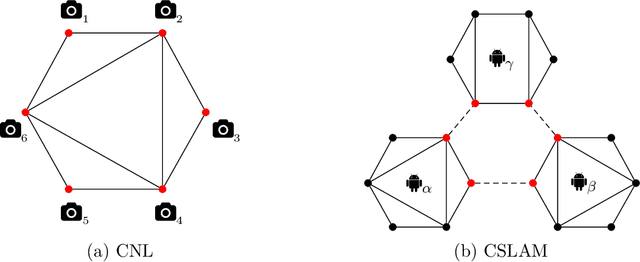
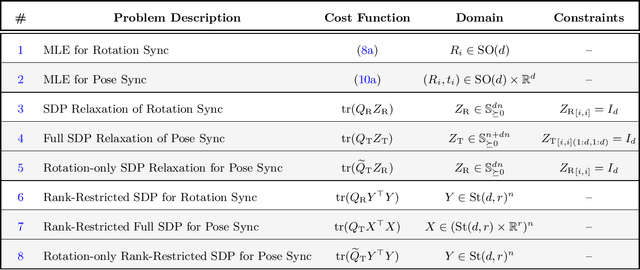
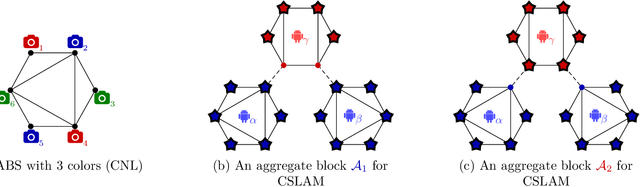
This paper presents the first certifiably correct solver for distributed rotation and pose synchronization, the backbone of modern collaborative simultaneous localization and mapping (CSLAM) and camera network localization (CNL) systems. By pursuing a sparse semidefinite relaxation, our approach provides formal performance guarantees that match the state of the art in the centralized setting. In particular, we prove that under "low" noise, the solution to the semidefinite relaxation is guaranteed to provide a globally optimal solution to the original non-convex problem. To solve the resulting large-scale semidefinite programs, we adopt the state-of-the-art Riemannian Staircase framework and develop Riemannian block-coordinate descent (RBCD) as the core distributed local search algorithm. RBCD is well-suited to distributed synchronization problems as it only requires local communication, provides privacy protection, and is easily parallelizable. Furthermore, we prove that RBCD converges to first-order critical points for general Riemannian optimization problems over product of matrix submanifolds, with a global sublinear convergence rate. Extensive evaluations on real and synthetic datasets demonstrate that the proposed solver correctly recovers globally optimal solutions under low-to-moderate noise, and outperforms alternative distributed techniques in terms of solution precision and convergence speed.
Incremental Learning of Motion Primitives for Pedestrian Trajectory Prediction at Intersections
Nov 21, 2019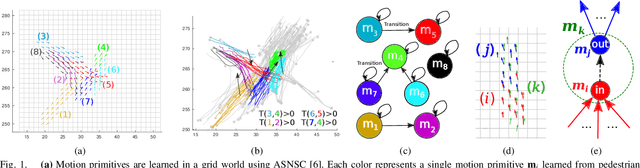
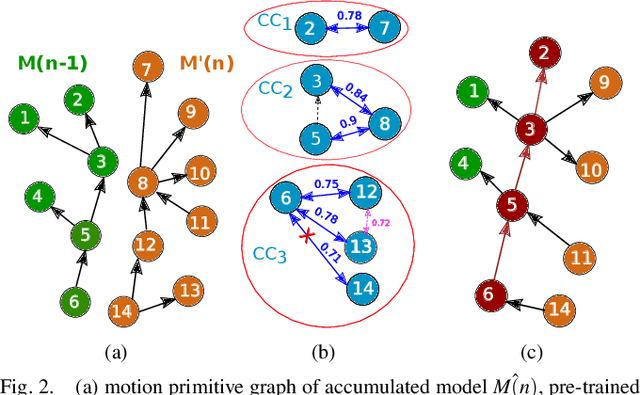
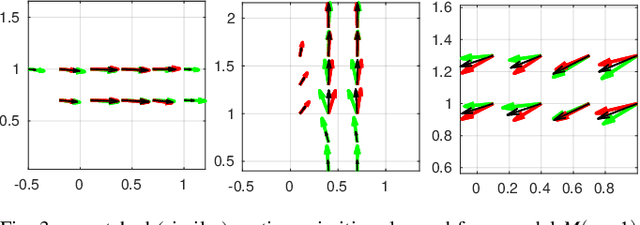

This paper presents a novel incremental learning algorithm for pedestrian motion prediction, with the ability to improve the learned model over time when data is incrementally available. In this setup, trajectories are modeled as simple segments called motion primitives. Transitions between motion primitives are modeled as Gaussian Processes. When new data is available, the motion primitives learned from the new data are compared with the previous ones by measuring the inner product of the motion primitive vectors. Similar motion primitives and transitions are fused and novel motion primitives are added to capture newly observed behaviors. The proposed approach is tested and compared with other baselines in intersection scenarios where the data is incrementally available either from a single intersection or from multiple intersections with different geometries. In both cases, our method incrementally learns motion patterns and outperforms the offline learning approach in terms of prediction errors. The results also show that the model size in our algorithm grows at a much lower rate than standard incremental learning, where newly learned motion primitives and transitions are simply accumulated over time.