 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEPHand: View-Efficient Photometric Hand Performance Capture at Scale
Jun 18, 2026Robust, high-fidelity 3D hand capture, while fundamental to digital human creation, remains challenging with practical multi-view systems that balance rich photometry with the geometric ambiguities of reconstruction arising from limited viewpoint density. This paper presents an end-to-end pipeline for dynamic hand performance capture and registration, specifically designed for view-efficient setups ($\sim$20 views). We address key challenges with two primary innovations. First, to overcome reconstruction difficulties like limited view overlap and background clutter, our mask-free neural method robustly extracts detailed hand geometry and appearance from unmasked images using scene parameterization and scenario-specific density regularization. Second, addressing registration challenges such as accurately capturing non-linear skin deformations and ensuring plausible results during severe self-contact, we propose a physics-inspired framework. It aligns reconstructions to a personalized hand model by optimizing intrinsic volumetric offsets within its canonical tetrahedral mesh, alongside pose parameters. This approach, supported by robust losses and optimization, captures fine surface deformations, ensures plausible results under severe articulation and self-contact, and demonstrates strong tolerance to input noise. We demonstrate the scalability and robustness of our automated pipeline on an extensive dataset of over 12,000 sequences, from which we also derive a large-scale, high-quality synthetic 2D/3D hand dataset for training downstream tasks. This showcases its effectiveness for single hands, intricate two-hand interactions, and natural hand-object manipulations. Our method achieves state-of-the-art reconstruction fidelity in view-efficient, unmasked scenarios and highly accurate registration. Our project page are available at https://vephand.github.io/.
Multi-agent Motion Planning for Dense and Dynamic Environments via Deep Reinforcement Learning
Jan 18, 2020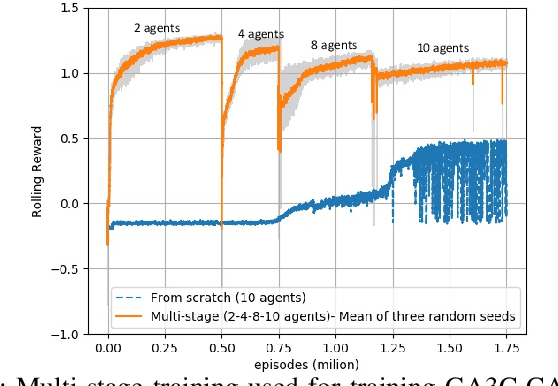
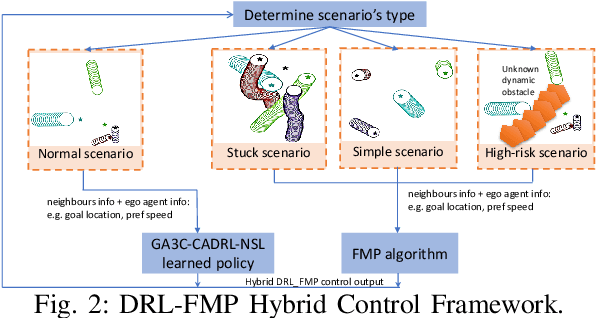
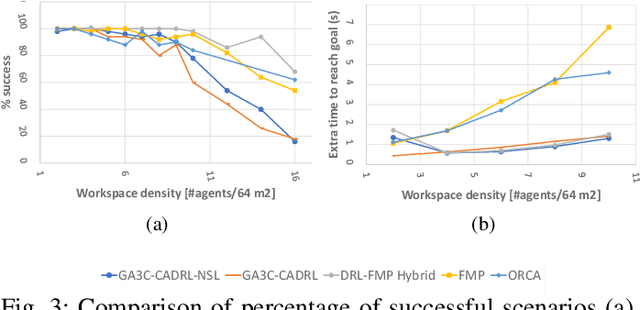
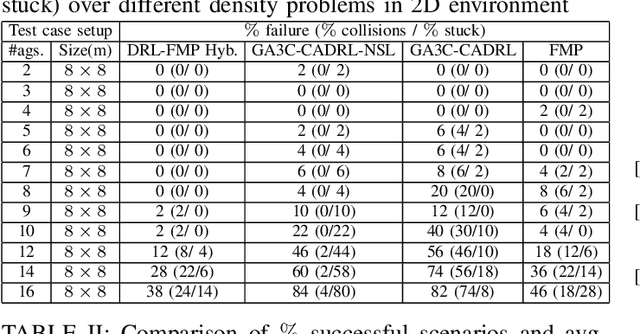
This paper introduces a hybrid algorithm of deep reinforcement learning (RL) and Force-based motion planning (FMP) to solve distributed motion planning problem in dense and dynamic environments. Individually, RL and FMP algorithms each have their own limitations. FMP is not able to produce time-optimal paths and existing RL solutions are not able to produce collision-free paths in dense environments. Therefore, we first tried improving the performance of recent RL approaches by introducing a new reward function that not only eliminates the requirement of a pre supervised learning (SL) step but also decreases the chance of collision in crowded environments. That improved things, but there were still a lot of failure cases. So, we developed a hybrid approach to leverage the simpler FMP approach in stuck, simple and high-risk cases, and continue using RL for normal cases in which FMP can't produce optimal path. Also, we extend GA3C-CADRL algorithm to 3D environment. Simulation results show that the proposed algorithm outperforms both deep RL and FMP algorithms and produces up to 50% more successful scenarios than deep RL and up to 75% less extra time to reach goal than FMP.
Force-based Algorithm for Motion Planning of Large Agent Teams
Sep 10, 2019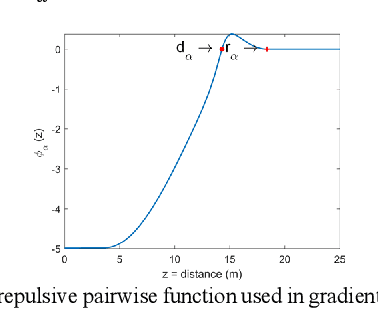
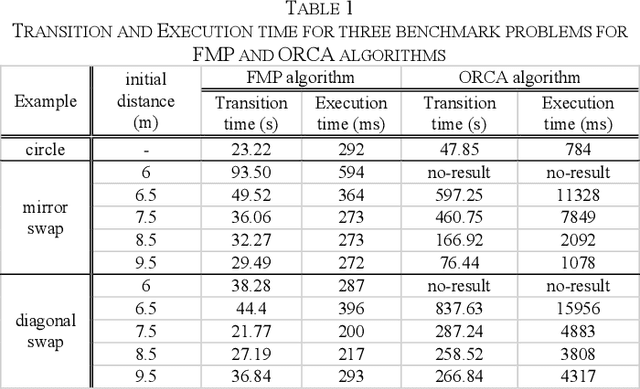
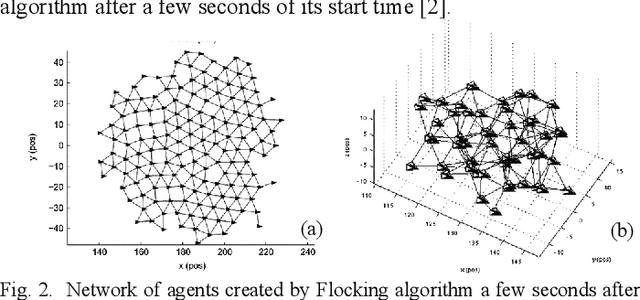
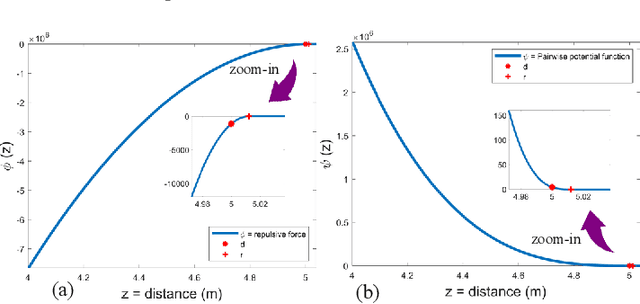
This paper presents a distributed, efficient, scalable and real-time motion planning algorithm for a large group of agents moving in 2 or 3-dimensional spaces. This algorithm enables autonomous agents to generate individual trajectories independently with only the relative position information of neighboring agents. Each agent applies a force-based control that contains two main terms: collision avoidance and navigational feedback. The first term keeps two agents separate with a certain distance, while the second term attracts each agent toward its goal location. Compared with existing collision-avoidance algorithms, the proposed force-based motion planning (FMP) algorithm is able to find collision-free motions with lower transition time, free from velocity state information of neighbouring agents. It leads to less computational overhead. The performance of proposed FMP is examined over several dense and complex 2D and 3D benchmark simulation scenarios, with results outperforming existing methods.