 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing ML Training with Metagradient Descent
Mar 17, 2025A major challenge in training large-scale machine learning models is configuring the training process to maximize model performance, i.e., finding the best training setup from a vast design space. In this work, we unlock a gradient-based approach to this problem. We first introduce an algorithm for efficiently calculating metagradients -- gradients through model training -- at scale. We then introduce a "smooth model training" framework that enables effective optimization using metagradients. With metagradient descent (MGD), we greatly improve on existing dataset selection methods, outperform accuracy-degrading data poisoning attacks by an order of magnitude, and automatically find competitive learning rate schedules.
Understanding Automatic Differentiation Pitfalls
May 12, 2023

Automatic differentiation, also known as backpropagation, AD, autodiff, or algorithmic differentiation, is a popular technique for computing derivatives of computer programs accurately and efficiently. Sometimes, however, the derivatives computed by AD could be interpreted as incorrect. These pitfalls occur systematically across tools and approaches. In this paper we broadly categorize problematic usages of AD and illustrate each category with examples such as chaos, time-averaged oscillations, discretizations, fixed-point loops, lookup tables, and linear solvers. We also review debugging techniques and their effectiveness in these situations. With this article we hope to help readers avoid unexpected behavior, detect problems more easily when they occur, and have more realistic expectations from AD tools.
ProTuner: Tuning Programs with Monte Carlo Tree Search
May 27, 2020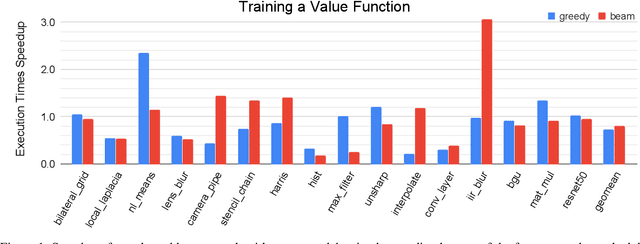

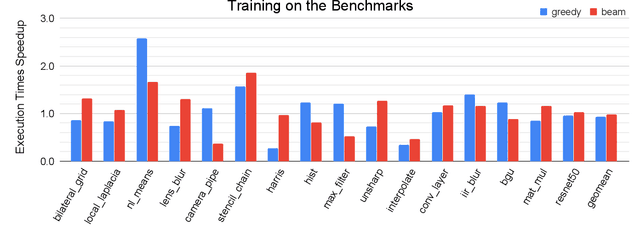
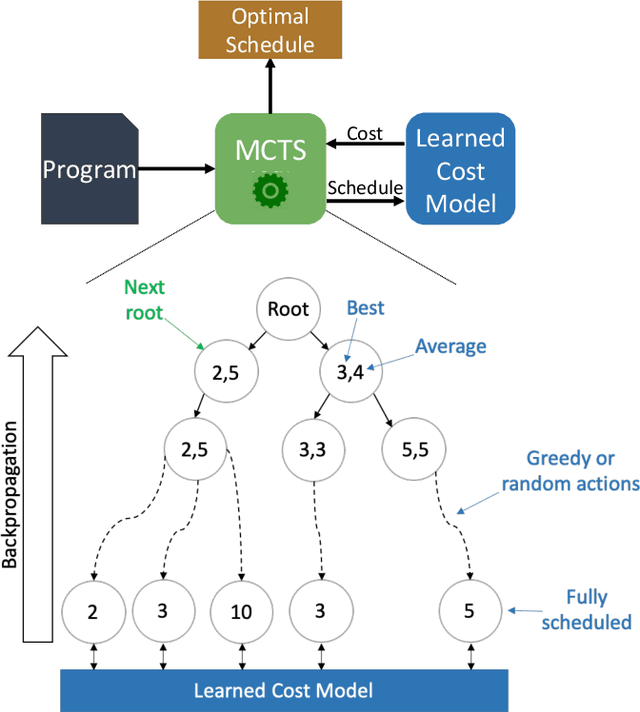
We explore applying the Monte Carlo Tree Search (MCTS) algorithm in a notoriously difficult task: tuning programs for high-performance deep learning and image processing. We build our framework on top of Halide and show that MCTS can outperform the state-of-the-art beam-search algorithm. Unlike beam search, which is guided by greedy intermediate performance comparisons between partial and less meaningful schedules, MCTS compares complete schedules and looks ahead before making any intermediate scheduling decision. We further explore modifications to the standard MCTS algorithm as well as combining real execution time measurements with the cost model. Our results show that MCTS can outperform beam search on a suite of 16 real benchmarks.
AutoPhase: Juggling HLS Phase Orderings in Random Forests with Deep Reinforcement Learning
Mar 04, 2020


The performance of the code a compiler generates depends on the order in which it applies the optimization passes. Choosing a good order--often referred to as the phase-ordering problem, is an NP-hard problem. As a result, existing solutions rely on a variety of heuristics. In this paper, we evaluate a new technique to address the phase-ordering problem: deep reinforcement learning. To this end, we implement AutoPhase: a framework that takes a program and uses deep reinforcement learning to find a sequence of compilation passes that minimizes its execution time. Without loss of generality, we construct this framework in the context of the LLVM compiler toolchain and target high-level synthesis programs. We use random forests to quantify the correlation between the effectiveness of a given pass and the program's features. This helps us reduce the search space by avoiding phase orderings that are unlikely to improve the performance of a given program. We compare the performance of AutoPhase to state-of-the-art algorithms that address the phase-ordering problem. In our evaluation, we show that AutoPhase improves circuit performance by 28% when compared to using the -O3 compiler flag, and achieves competitive results compared to the state-of-the-art solutions, while requiring fewer samples. Furthermore, unlike existing state-of-the-art solutions, our deep reinforcement learning solution shows promising result in generalizing to real benchmarks and 12,874 different randomly generated programs, after training on a hundred randomly generated programs.
AutoPhase: Compiler Phase-Ordering for High Level Synthesis with Deep Reinforcement Learning
Jan 15, 2019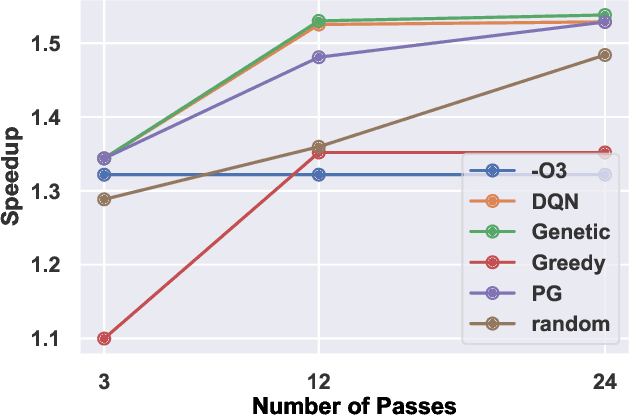
The performance of the code generated by a compiler depends on the order in which the optimization passes are applied. In the context of high-level synthesis, the quality of the generated circuit relates directly to the code generated by the front-end compiler. Unfortunately, choosing a good order--often referred to as the phase-ordering problem--is an NP-hard problem. As a result, existing solutions rely on a variety of sub-optimal heuristics. In this paper, we evaluate a new technique to address the phase-ordering problem: deep reinforcement learning. To this end, we implement a framework that takes any group of programs and finds a sequence of passes that optimize the performance of these programs. Without loss of generality, we instantiate this framework in the context of an LLVM compiler and target multiple High-Level Synthesis programs. We compare the performance of deep reinforcement learning to state-of-the-art algorithms that address the phase-ordering problem. Overall, our framework runs one to two orders of magnitude faster than these algorithms, and achieves a 16% improvement in circuit performance over the -O3 compiler flag.