 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Do LLM Preferences Predict Downstream Behavior?
Feb 21, 2026Preference-driven behavior in LLMs may be a necessary precondition for AI misalignment such as sandbagging: models cannot strategically pursue misaligned goals unless their behavior is influenced by their preferences. Yet prior work has typically prompted models explicitly to act in specific ways, leaving unclear whether observed behaviors reflect instruction-following capabilities vs underlying model preferences. Here we test whether this precondition for misalignment is present. Using entity preferences as a behavioral probe, we measure whether stated preferences predict downstream behavior in five frontier LLMs across three domains: donation advice, refusal behavior, and task performance. Conceptually replicating prior work, we first confirm that all five models show highly consistent preferences across two independent measurement methods. We then test behavioral consequences in a simulated user environment. We find that all five models give preference-aligned donation advice. All five models also show preference-correlated refusal patterns when asked to recommend donations, refusing more often for less-preferred entities. All preference-related behaviors that we observe here emerge without instructions to act on preferences. Results for task performance are mixed: on a question-answering benchmark (BoolQ), two models show small but significant accuracy differences favoring preferred entities; one model shows the opposite pattern; and two models show no significant relationship. On complex agentic tasks, we find no evidence of preference-driven performance differences. While LLMs have consistent preferences that reliably predict advice-giving behavior, these preferences do not consistently translate into downstream task performance.
Training language models to follow instructions with human feedback
Mar 04, 2022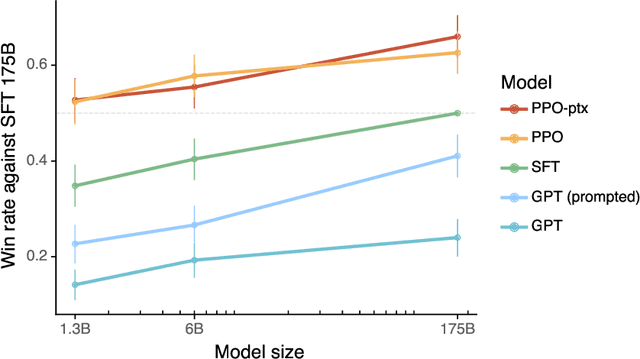

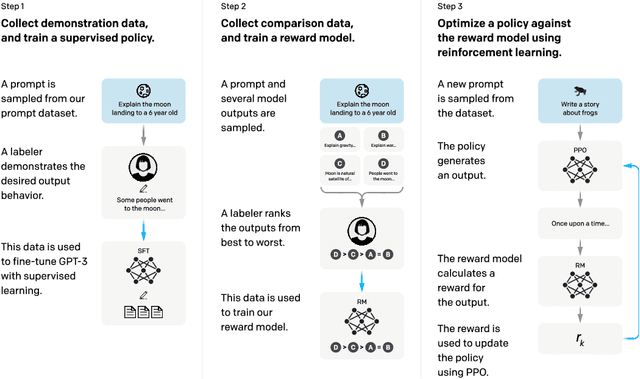

Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. In this paper, we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback. Starting with a set of labeler-written prompts and prompts submitted through the OpenAI API, we collect a dataset of labeler demonstrations of the desired model behavior, which we use to fine-tune GPT-3 using supervised learning. We then collect a dataset of rankings of model outputs, which we use to further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT. In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters. Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. Even though InstructGPT still makes simple mistakes, our results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent.