 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse and Effective Red Teaming with Auto-generated Rewards and Multi-step Reinforcement Learning
Dec 24, 2024



Automated red teaming can discover rare model failures and generate challenging examples that can be used for training or evaluation. However, a core challenge in automated red teaming is ensuring that the attacks are both diverse and effective. Prior methods typically succeed in optimizing either for diversity or for effectiveness, but rarely both. In this paper, we provide methods that enable automated red teaming to generate a large number of diverse and successful attacks. Our approach decomposes the task into two steps: (1) automated methods for generating diverse attack goals and (2) generating effective attacks for those goals. While we provide multiple straightforward methods for generating diverse goals, our key contributions are to train an RL attacker that both follows those goals and generates diverse attacks for those goals. First, we demonstrate that it is easy to use a large language model (LLM) to generate diverse attacker goals with per-goal prompts and rewards, including rule-based rewards (RBRs) to grade whether the attacks are successful for the particular goal. Second, we demonstrate how training the attacker model with multi-step RL, where the model is rewarded for generating attacks that are different from past attempts further increases diversity while remaining effective. We use our approach to generate both prompt injection attacks and prompts that elicit unsafe responses. In both cases, we find that our approach is able to generate highly-effective and considerably more diverse attacks than past general red-teaming approaches.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Rule Based Rewards for Language Model Safety
Nov 02, 2024Reinforcement learning based fine-tuning of large language models (LLMs) on human preferences has been shown to enhance both their capabilities and safety behavior. However, in cases related to safety, without precise instructions to human annotators, the data collected may cause the model to become overly cautious, or to respond in an undesirable style, such as being judgmental. Additionally, as model capabilities and usage patterns evolve, there may be a costly need to add or relabel data to modify safety behavior. We propose a novel preference modeling approach that utilizes AI feedback and only requires a small amount of human data. Our method, Rule Based Rewards (RBR), uses a collection of rules for desired or undesired behaviors (e.g. refusals should not be judgmental) along with a LLM grader. In contrast to prior methods using AI feedback, our method uses fine-grained, composable, LLM-graded few-shot prompts as reward directly in RL training, resulting in greater control, accuracy and ease of updating. We show that RBRs are an effective training method, achieving an F1 score of 97.1, compared to a human-feedback baseline of 91.7, resulting in much higher safety-behavior accuracy through better balancing usefulness and safety.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Oct 09, 2024



We introduce MLE-bench, a benchmark for measuring how well AI agents perform at machine learning engineering. To this end, we curate 75 ML engineering-related competitions from Kaggle, creating a diverse set of challenging tasks that test real-world ML engineering skills such as training models, preparing datasets, and running experiments. We establish human baselines for each competition using Kaggle's publicly available leaderboards. We use open-source agent scaffolds to evaluate several frontier language models on our benchmark, finding that the best-performing setup--OpenAI's o1-preview with AIDE scaffolding--achieves at least the level of a Kaggle bronze medal in 16.9% of competitions. In addition to our main results, we investigate various forms of resource scaling for AI agents and the impact of contamination from pre-training. We open-source our benchmark code (github.com/openai/mle-bench/) to facilitate future research in understanding the ML engineering capabilities of AI agents.
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Apr 19, 2024



Today's LLMs are susceptible to prompt injections, jailbreaks, and other attacks that allow adversaries to overwrite a model's original instructions with their own malicious prompts. In this work, we argue that one of the primary vulnerabilities underlying these attacks is that LLMs often consider system prompts (e.g., text from an application developer) to be the same priority as text from untrusted users and third parties. To address this, we propose an instruction hierarchy that explicitly defines how models should behave when instructions of different priorities conflict. We then propose a data generation method to demonstrate this hierarchical instruction following behavior, which teaches LLMs to selectively ignore lower-privileged instructions. We apply this method to GPT-3.5, showing that it drastically increases robustness -- even for attack types not seen during training -- while imposing minimal degradations on standard capabilities.
A Holistic Approach to Undesired Content Detection in the Real World
Aug 05, 2022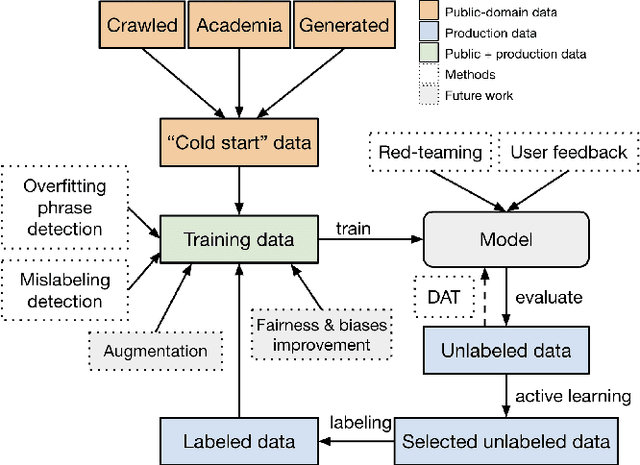


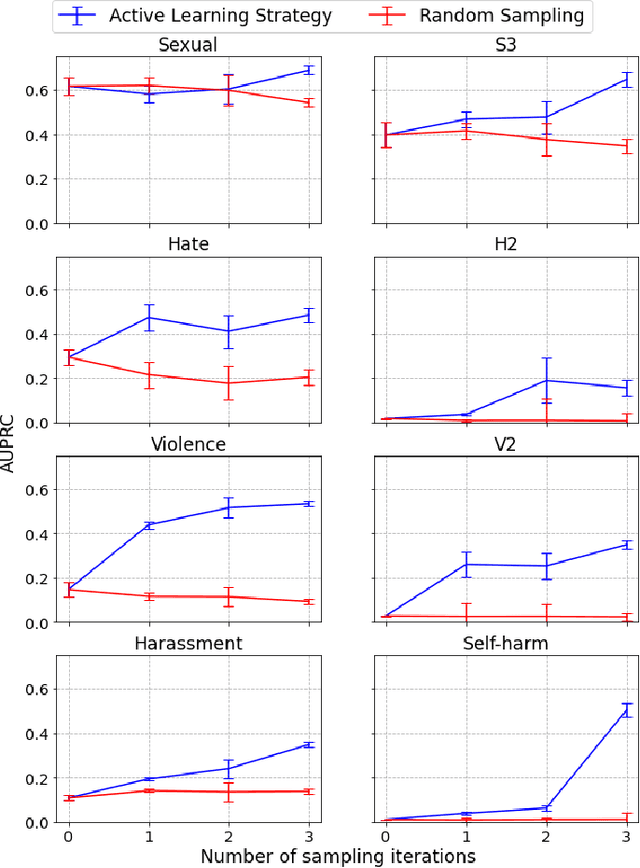
We present a holistic approach to building a robust and useful natural language classification system for real-world content moderation. The success of such a system relies on a chain of carefully designed and executed steps, including the design of content taxonomies and labeling instructions, data quality control, an active learning pipeline to capture rare events, and a variety of methods to make the model robust and to avoid overfitting. Our moderation system is trained to detect a broad set of categories of undesired content, including sexual content, hateful content, violence, self-harm, and harassment. This approach generalizes to a wide range of different content taxonomies and can be used to create high-quality content classifiers that outperform off-the-shelf models.
Exploration in Deep Reinforcement Learning: A Survey
May 02, 2022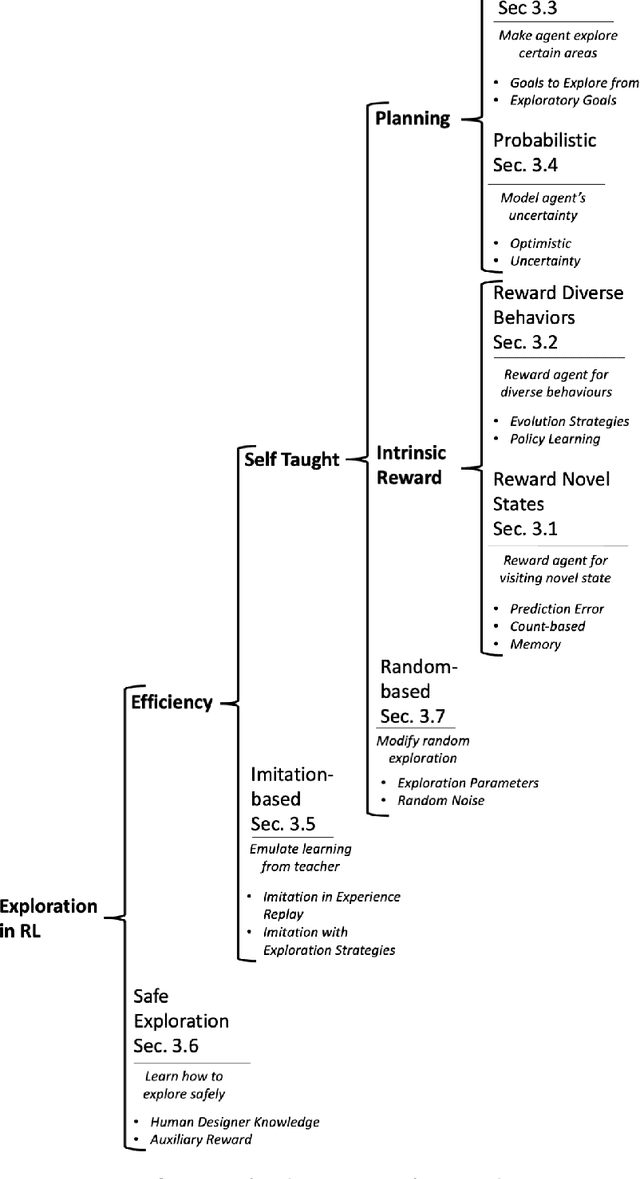
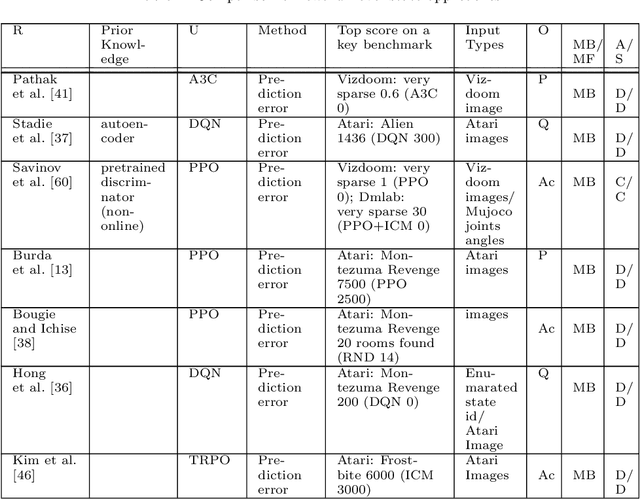
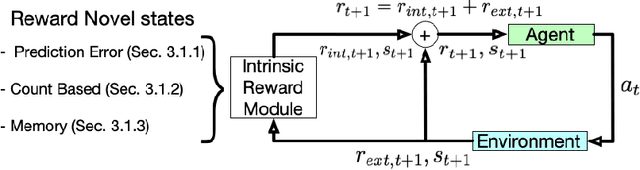
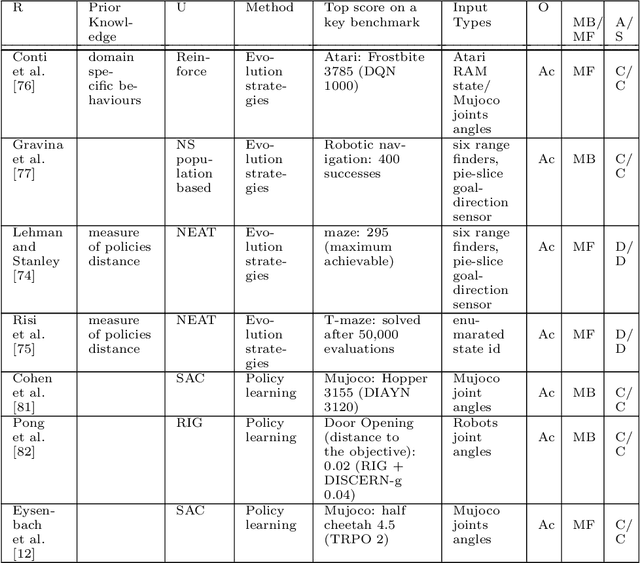
This paper reviews exploration techniques in deep reinforcement learning. Exploration techniques are of primary importance when solving sparse reward problems. In sparse reward problems, the reward is rare, which means that the agent will not find the reward often by acting randomly. In such a scenario, it is challenging for reinforcement learning to learn rewards and actions association. Thus more sophisticated exploration methods need to be devised. This review provides a comprehensive overview of existing exploration approaches, which are categorized based on the key contributions as follows reward novel states, reward diverse behaviours, goal-based methods, probabilistic methods, imitation-based methods, safe exploration and random-based methods. Then, the unsolved challenges are discussed to provide valuable future research directions. Finally, the approaches of different categories are compared in terms of complexity, computational effort and overall performance.
Text and Code Embeddings by Contrastive Pre-Training
Jan 24, 2022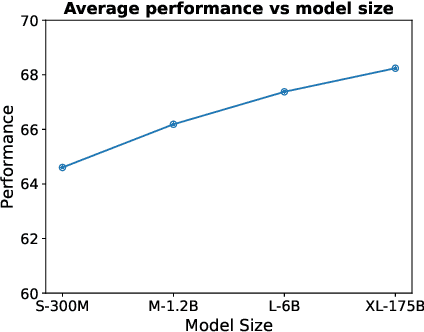
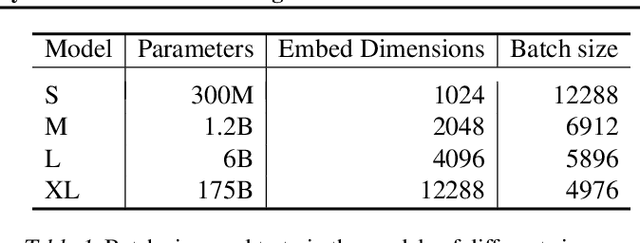
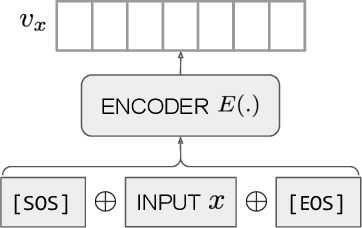
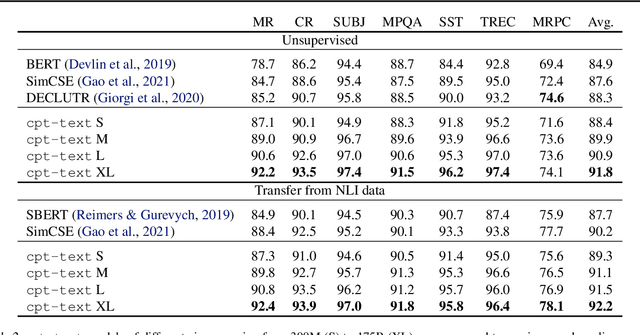
Text embeddings are useful features in many applications such as semantic search and computing text similarity. Previous work typically trains models customized for different use cases, varying in dataset choice, training objective and model architecture. In this work, we show that contrastive pre-training on unsupervised data at scale leads to high quality vector representations of text and code. The same unsupervised text embeddings that achieve new state-of-the-art results in linear-probe classification also display impressive semantic search capabilities and sometimes even perform competitively with fine-tuned models. On linear-probe classification accuracy averaging over 7 tasks, our best unsupervised model achieves a relative improvement of 4% and 1.8% over previous best unsupervised and supervised text embedding models respectively. The same text embeddings when evaluated on large-scale semantic search attains a relative improvement of 23.4%, 14.7%, and 10.6% over previous best unsupervised methods on MSMARCO, Natural Questions and TriviaQA benchmarks, respectively. Similarly to text embeddings, we train code embedding models on (text, code) pairs, obtaining a 20.8% relative improvement over prior best work on code search.
Asymmetric self-play for automatic goal discovery in robotic manipulation
Jan 13, 2021
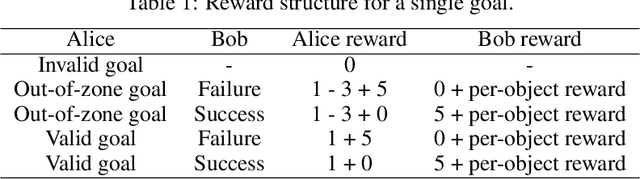
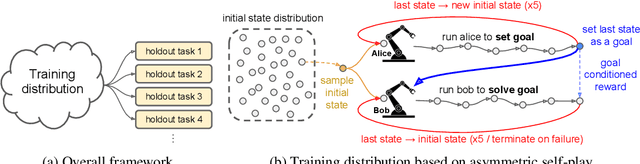
We train a single, goal-conditioned policy that can solve many robotic manipulation tasks, including tasks with previously unseen goals and objects. We rely on asymmetric self-play for goal discovery, where two agents, Alice and Bob, play a game. Alice is asked to propose challenging goals and Bob aims to solve them. We show that this method can discover highly diverse and complex goals without any human priors. Bob can be trained with only sparse rewards, because the interaction between Alice and Bob results in a natural curriculum and Bob can learn from Alice's trajectory when relabeled as a goal-conditioned demonstration. Finally, our method scales, resulting in a single policy that can generalize to many unseen tasks such as setting a table, stacking blocks, and solving simple puzzles. Videos of a learned policy is available at https://robotics-self-play.github.io.