 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHGATSolver: A Heterogeneous Graph Attention Solver for Fluid-Structure Interaction
Jan 14, 2026Fluid-structure interaction (FSI) systems involve distinct physical domains, fluid and solid, governed by different partial differential equations and coupled at a dynamic interface. While learning-based solvers offer a promising alternative to costly numerical simulations, existing methods struggle to capture the heterogeneous dynamics of FSI within a unified framework. This challenge is further exacerbated by inconsistencies in response across domains due to interface coupling and by disparities in learning difficulty across fluid and solid regions, leading to instability during prediction. To address these challenges, we propose the Heterogeneous Graph Attention Solver (HGATSolver). HGATSolver encodes the system as a heterogeneous graph, embedding physical structure directly into the model via distinct node and edge types for fluid, solid, and interface regions. This enables specialized message-passing mechanisms tailored to each physical domain. To stabilize explicit time stepping, we introduce a novel physics-conditioned gating mechanism that serves as a learnable, adaptive relaxation factor. Furthermore, an Inter-domain Gradient-Balancing Loss dynamically balances the optimization objectives across domains based on predictive uncertainty. Extensive experiments on two constructed FSI benchmarks and a public dataset demonstrate that HGATSolver achieves state-of-the-art performance, establishing an effective framework for surrogate modeling of coupled multi-physics systems.
CodeContests+: High-Quality Test Case Generation for Competitive Programming
Jun 06, 2025



Competitive programming, due to its high reasoning difficulty and precise correctness feedback, has become a key task for both training and evaluating the reasoning capabilities of large language models (LLMs). However, while a large amount of public problem data, such as problem statements and solutions, is available, the test cases of these problems are often difficult to obtain. Therefore, test case generation is a necessary task for building large-scale datasets, and the quality of the test cases directly determines the accuracy of the evaluation. In this paper, we introduce an LLM-based agent system that creates high-quality test cases for competitive programming problems. We apply this system to the CodeContests dataset and propose a new version with improved test cases, named CodeContests+. We evaluated the quality of test cases in CodeContestsPlus. First, we used 1.72 million submissions with pass/fail labels to examine the accuracy of these test cases in evaluation. The results indicated that CodeContests+ achieves significantly higher accuracy than CodeContests, particularly with a notably higher True Positive Rate (TPR). Subsequently, our experiments in LLM Reinforcement Learning (RL) further confirmed that improvements in test case quality yield considerable advantages for RL.
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
Apr 03, 2025The task of issue resolving is to modify a codebase to generate a patch that addresses a given issue. However, existing benchmarks, such as SWE-bench, focus almost exclusively on Python, making them insufficient for evaluating Large Language Models (LLMs) across diverse software ecosystems. To address this, we introduce a multilingual issue-resolving benchmark, called Multi-SWE-bench, covering Java, TypeScript, JavaScript, Go, Rust, C, and C++. It includes a total of 1,632 high-quality instances, which were carefully annotated from 2,456 candidates by 68 expert annotators, ensuring that the benchmark can provide an accurate and reliable evaluation. Based on Multi-SWE-bench, we evaluate a series of state-of-the-art models using three representative methods (Agentless, SWE-agent, and OpenHands) and present a comprehensive analysis with key empirical insights. In addition, we launch a Multi-SWE-RL open-source community, aimed at building large-scale reinforcement learning (RL) training datasets for issue-resolving tasks. As an initial contribution, we release a set of 4,723 well-structured instances spanning seven programming languages, laying a solid foundation for RL research in this domain. More importantly, we open-source our entire data production pipeline, along with detailed tutorials, encouraging the open-source community to continuously contribute and expand the dataset. We envision our Multi-SWE-bench and the ever-growing Multi-SWE-RL community as catalysts for advancing RL toward its full potential, bringing us one step closer to the dawn of AGI.
FullStack Bench: Evaluating LLMs as Full Stack Coders
Dec 03, 2024



As the capabilities of code large language models (LLMs) continue to expand, their applications across diverse code intelligence domains are rapidly increasing. However, most existing datasets only evaluate limited application domains. To address this gap, we have developed a comprehensive code evaluation dataset FullStack Bench focusing on full-stack programming, which encompasses a wide range of application domains (e.g., basic programming, data analysis, software engineering, mathematics, and machine learning). Besides, to assess multilingual programming capabilities, in FullStack Bench, we design real-world instructions and corresponding unit test cases from 16 widely-used programming languages to reflect real-world usage scenarios rather than simple translations. Moreover, we also release an effective code sandbox execution tool (i.e., SandboxFusion) supporting various programming languages and packages to evaluate the performance of our FullStack Bench efficiently. Comprehensive experimental results on our FullStack Bench demonstrate the necessity and effectiveness of our FullStack Bench and SandboxFusion.
Reinforcement learning for bandwidth estimation and congestion control in real-time communications
Dec 04, 2019

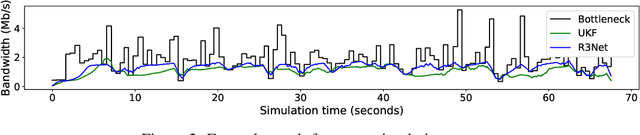
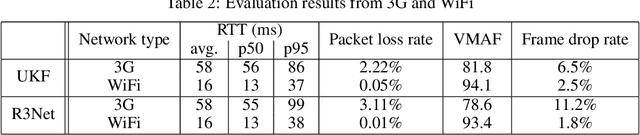
Bandwidth estimation and congestion control for real-time communications (i.e., audio and video conferencing) remains a difficult problem, despite many years of research. Achieving high quality of experience (QoE) for end users requires continual updates due to changing network architectures and technologies. In this paper, we apply reinforcement learning for the first time to the problem of real-time communications (RTC), where we seek to optimize user-perceived quality. We present initial proof-of-concept results, where we learn an agent to control sending rate in an RTC system, evaluating using both network simulation and real Internet video calls. We discuss the challenges we observed, particularly in designing realistic reward functions that reflect QoE, and in bridging the gap between the training environment and real-world networks.