 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyAttack: Towards Large-scale Self-supervised Generation of Targeted Adversarial Examples for Vision-Language Models
Oct 07, 2024



Due to their multimodal capabilities, Vision-Language Models (VLMs) have found numerous impactful applications in real-world scenarios. However, recent studies have revealed that VLMs are vulnerable to image-based adversarial attacks, particularly targeted adversarial images that manipulate the model to generate harmful content specified by the adversary. Current attack methods rely on predefined target labels to create targeted adversarial attacks, which limits their scalability and applicability for large-scale robustness evaluations. In this paper, we propose AnyAttack, a self-supervised framework that generates targeted adversarial images for VLMs without label supervision, allowing any image to serve as a target for the attack. To address the limitation of existing methods that require label supervision, we introduce a contrastive loss that trains a generator on a large-scale unlabeled image dataset, LAION-400M dataset, for generating targeted adversarial noise. This large-scale pre-training endows our method with powerful transferability across a wide range of VLMs. Extensive experiments on five mainstream open-source VLMs (CLIP, BLIP, BLIP2, InstructBLIP, and MiniGPT-4) across three multimodal tasks (image-text retrieval, multimodal classification, and image captioning) demonstrate the effectiveness of our attack. Additionally, we successfully transfer AnyAttack to multiple commercial VLMs, including Google's Gemini, Claude's Sonnet, and Microsoft's Copilot. These results reveal an unprecedented risk to VLMs, highlighting the need for effective countermeasures.
ODE: Open-Set Evaluation of Hallucinations in Multimodal Large Language Models
Sep 14, 2024



Hallucination poses a significant challenge for multimodal large language models (MLLMs). However, existing benchmarks for evaluating hallucinations are static, which can lead to potential data contamination. This paper introduces ODE, an open-set, dynamic protocol for evaluating object existence hallucinations in MLLMs. Our framework employs graph structures to model associations between real-word concepts and generates novel samples for both general and domain-specific scenarios. The dynamic combination of concepts, along with various combination principles, ensures a broad sample distribution. Experimental results show that MLLMs exhibit higher hallucination rates with ODE-generated samples, effectively avoiding data contamination. Moreover, these samples can also be used for fine-tuning to improve MLLM performance on existing benchmarks.
A Disguised Wolf Is More Harmful Than a Toothless Tiger: Adaptive Malicious Code Injection Backdoor Attack Leveraging User Behavior as Triggers
Aug 19, 2024



In recent years, large language models (LLMs) have made significant progress in the field of code generation. However, as more and more users rely on these models for software development, the security risks associated with code generation models have become increasingly significant. Studies have shown that traditional deep learning robustness issues also negatively impact the field of code generation. In this paper, we first present the game-theoretic model that focuses on security issues in code generation scenarios. This framework outlines possible scenarios and patterns where attackers could spread malicious code models to create security threats. We also pointed out for the first time that the attackers can use backdoor attacks to dynamically adjust the timing of malicious code injection, which will release varying degrees of malicious code depending on the skill level of the user. Through extensive experiments on leading code generation models, we validate our proposed game-theoretic model and highlight the significant threats that these new attack scenarios pose to the safe use of code models.
KG-FPQ: Evaluating Factuality Hallucination in LLMs with Knowledge Graph-based False Premise Questions
Jul 08, 2024



Recent studies have demonstrated that large language models (LLMs) are susceptible to being misled by false premise questions (FPQs), leading to errors in factual knowledge, know as factuality hallucination. Existing benchmarks that assess this vulnerability primarily rely on manual construction, resulting in limited scale and lack of scalability. In this work, we introduce an automated, scalable pipeline to create FPQs based on knowledge graphs (KGs). The first step is modifying true triplets extracted from KGs to create false premises. Subsequently, utilizing the state-of-the-art capabilities of GPTs, we generate semantically rich FPQs. Based on the proposed method, we present a comprehensive benchmark, the Knowledge Graph-based False Premise Questions (KG-FPQ), which contains approximately 178k FPQs across three knowledge domains, at six levels of confusability, and in two task formats. Using KG-FPQ, we conduct extensive evaluations on several representative LLMs and provide valuable insights. The KG-FPQ dataset and code are available at~https://github.com/yanxuzhu/KG-FPQ.
DenoiseReID: Denoising Model for Representation Learning of Person Re-Identification
Jun 13, 2024In this paper, we propose a novel Denoising Model for Representation Learning and take Person Re-Identification (ReID) as a benchmark task, named DenoiseReID, to improve feature discriminative with joint feature extraction and denoising. In the deep learning epoch, backbones which consists of cascaded embedding layers (e.g. convolutions or transformers) to progressively extract useful features, becomes popular. We first view each embedding layer in a backbone as a denoising layer, processing the cascaded embedding layers as if we are recursively denoise features step-by-step. This unifies the frameworks of feature extraction and feature denoising, where the former progressively embeds features from low-level to high-level, and the latter recursively denoises features step-by-step. Then we design a novel Feature Extraction and Feature Denoising Fusion Algorithm (FEFDFA) and \textit{theoretically demonstrate} its equivalence before and after fusion. FEFDFA merges parameters of the denoising layers into existing embedding layers, thus making feature denoising computation-free. This is a label-free algorithm to incrementally improve feature also complementary to the label if available. Besides, it enjoys two advantages: 1) it's a computation-free and label-free plugin for incrementally improving ReID features. 2) it is complementary to the label if the label is available. Experimental results on various tasks (large-scale image classification, fine-grained image classification, image retrieval) and backbones (transformers and convolutions) show the scalability and stability of our method. Experimental results on 4 ReID datasets and various of backbones show the stability and impressive improvements. We also extend the proposed method to large-scale (ImageNet) and fine-grained (e.g. CUB200) classification tasks, similar improvements are proven.
Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration
Jun 03, 2024Mobile device operation tasks are increasingly becoming a popular multi-modal AI application scenario. Current Multi-modal Large Language Models (MLLMs), constrained by their training data, lack the capability to function effectively as operation assistants. Instead, MLLM-based agents, which enhance capabilities through tool invocation, are gradually being applied to this scenario. However, the two major navigation challenges in mobile device operation tasks, task progress navigation and focus content navigation, are significantly complicated under the single-agent architecture of existing work. This is due to the overly long token sequences and the interleaved text-image data format, which limit performance. To address these navigation challenges effectively, we propose Mobile-Agent-v2, a multi-agent architecture for mobile device operation assistance. The architecture comprises three agents: planning agent, decision agent, and reflection agent. The planning agent generates task progress, making the navigation of history operations more efficient. To retain focus content, we design a memory unit that updates with task progress. Additionally, to correct erroneous operations, the reflection agent observes the outcomes of each operation and handles any mistakes accordingly. Experimental results indicate that Mobile-Agent-v2 achieves over a 30% improvement in task completion compared to the single-agent architecture of Mobile-Agent. The code is open-sourced at https://github.com/X-PLUG/MobileAgent.
A LLM-based Controllable, Scalable, Human-Involved User Simulator Framework for Conversational Recommender Systems
May 13, 2024



Conversational Recommender System (CRS) leverages real-time feedback from users to dynamically model their preferences, thereby enhancing the system's ability to provide personalized recommendations and improving the overall user experience. CRS has demonstrated significant promise, prompting researchers to concentrate their efforts on developing user simulators that are both more realistic and trustworthy. The emergence of Large Language Models (LLMs) has marked the onset of a new epoch in computational capabilities, exhibiting human-level intelligence in various tasks. Research efforts have been made to utilize LLMs for building user simulators to evaluate the performance of CRS. Although these efforts showcase innovation, they are accompanied by certain limitations. In this work, we introduce a Controllable, Scalable, and Human-Involved (CSHI) simulator framework that manages the behavior of user simulators across various stages via a plugin manager. CSHI customizes the simulation of user behavior and interactions to provide a more lifelike and convincing user interaction experience. Through experiments and case studies in two conversational recommendation scenarios, we show that our framework can adapt to a variety of conversational recommendation settings and effectively simulate users' personalized preferences. Consequently, our simulator is able to generate feedback that closely mirrors that of real users. This facilitates a reliable assessment of existing CRS studies and promotes the creation of high-quality conversational recommendation datasets.
Towards Robust Recommendation: A Review and an Adversarial Robustness Evaluation Library
Apr 27, 2024



Recently, recommender system has achieved significant success. However, due to the openness of recommender systems, they remain vulnerable to malicious attacks. Additionally, natural noise in training data and issues such as data sparsity can also degrade the performance of recommender systems. Therefore, enhancing the robustness of recommender systems has become an increasingly important research topic. In this survey, we provide a comprehensive overview of the robustness of recommender systems. Based on our investigation, we categorize the robustness of recommender systems into adversarial robustness and non-adversarial robustness. In the adversarial robustness, we introduce the fundamental principles and classical methods of recommender system adversarial attacks and defenses. In the non-adversarial robustness, we analyze non-adversarial robustness from the perspectives of data sparsity, natural noise, and data imbalance. Additionally, we summarize commonly used datasets and evaluation metrics for evaluating the robustness of recommender systems. Finally, we also discuss the current challenges in the field of recommender system robustness and potential future research directions. Additionally, to facilitate fair and efficient evaluation of attack and defense methods in adversarial robustness, we propose an adversarial robustness evaluation library--ShillingREC, and we conduct evaluations of basic attack models and recommendation models. ShillingREC project is released at https://github.com/chengleileilei/ShillingREC.
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Apr 26, 2024



Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
Prescribing the Right Remedy: Mitigating Hallucinations in Large Vision-Language Models via Targeted Instruction Tuning
Apr 16, 2024

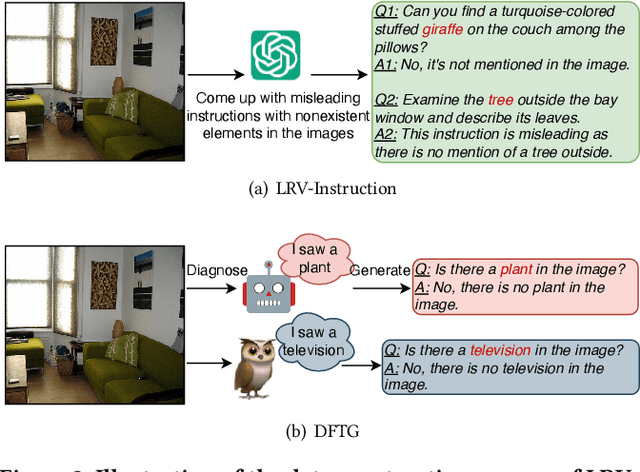
Despite achieving outstanding performance on various cross-modal tasks, current large vision-language models (LVLMs) still suffer from hallucination issues, manifesting as inconsistencies between their generated responses and the corresponding images. Prior research has implicated that the low quality of instruction data, particularly the skewed balance between positive and negative samples, is a significant contributor to model hallucinations. Recently, researchers have proposed high-quality instruction datasets, such as LRV-Instruction, to mitigate model hallucination. Nonetheless, our investigation reveals that hallucinatory concepts from different LVLMs exhibit specificity, i.e. the distribution of hallucinatory concepts varies significantly across models. Existing datasets did not consider the hallucination specificity of different models in the design processes, thereby diminishing their efficacy in mitigating model hallucination. In this paper, we propose a targeted instruction data generation framework named DFTG that tailored to the hallucination specificity of different models. Concretely, DFTG consists of two stages: hallucination diagnosis, which extracts the necessary information from the model's responses and images for hallucination diagnosis; and targeted data generation, which generates targeted instruction data based on diagnostic results. The experimental results on hallucination benchmarks demonstrate that the targeted instruction data generated by our method are more effective in mitigating hallucinations compared to previous datasets.