 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Personality Control and Adaptation for LLM Agents
Jan 15, 2026Large Language Models (LLMs) are increasingly shaping human-computer interaction (HCI), from personalized assistants to social simulations. Beyond language competence, researchers are exploring whether LLMs can exhibit human-like characteristics that influence engagement, decision-making, and perceived realism. Personality, in particular, is critical, yet existing approaches often struggle to achieve both nuanced and adaptable expression. We present a framework that models LLM personality via Jungian psychological types, integrating three mechanisms: a dominant-auxiliary coordination mechanism for coherent core expression, a reinforcement-compensation mechanism for temporary adaptation to context, and a reflection mechanism that drives long-term personality evolution. This design allows the agent to maintain nuanced traits while dynamically adjusting to interaction demands and gradually updating its underlying structure. Personality alignment is evaluated using Myers-Briggs Type Indicator questionnaires and tested under diverse challenge scenarios as a preliminary structured assessment. Findings suggest that evolving, personality-aware LLMs can support coherent, context-sensitive interactions, enabling naturalistic agent design in HCI.
Large Foundation Model for Ads Recommendation
Aug 20, 2025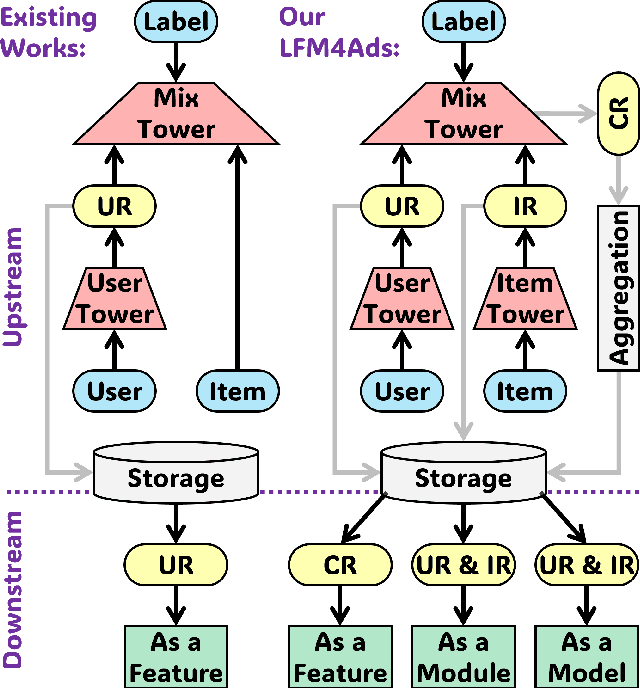
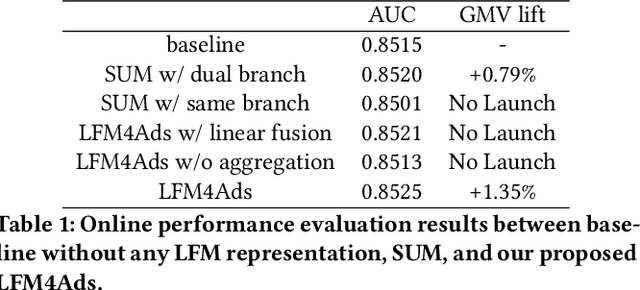
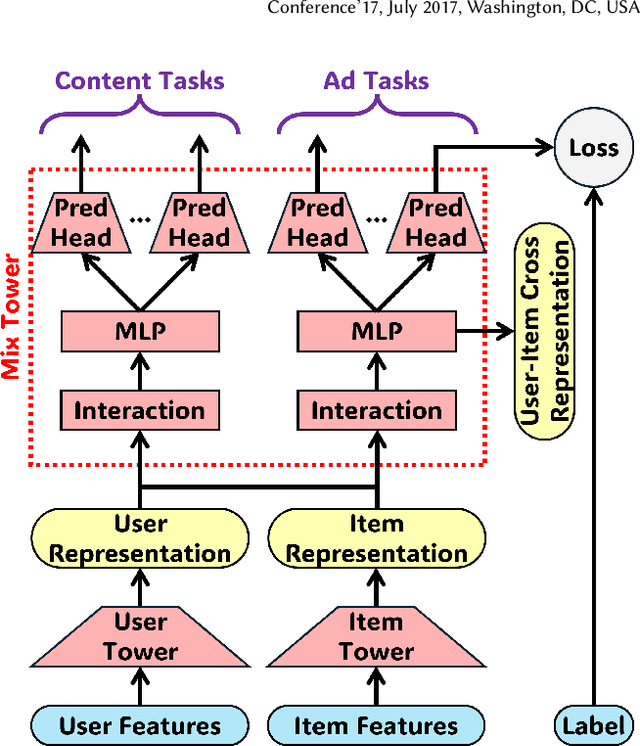
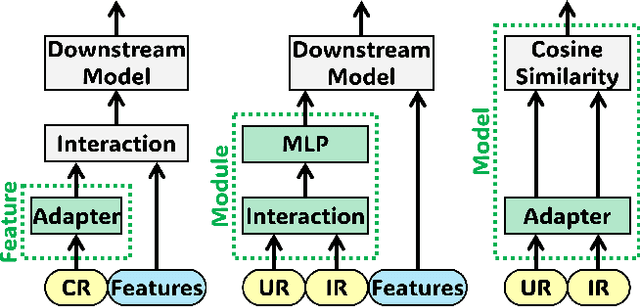
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
PMA: Towards Parameter-Efficient Point Cloud Understanding via Point Mamba Adapter
May 27, 2025Applying pre-trained models to assist point cloud understanding has recently become a mainstream paradigm in 3D perception. However, existing application strategies are straightforward, utilizing only the final output of the pre-trained model for various task heads. It neglects the rich complementary information in the intermediate layer, thereby failing to fully unlock the potential of pre-trained models. To overcome this limitation, we propose an orthogonal solution: Point Mamba Adapter (PMA), which constructs an ordered feature sequence from all layers of the pre-trained model and leverages Mamba to fuse all complementary semantics, thereby promoting comprehensive point cloud understanding. Constructing this ordered sequence is non-trivial due to the inherent isotropy of 3D space. Therefore, we further propose a geometry-constrained gate prompt generator (G2PG) shared across different layers, which applies shared geometric constraints to the output gates of the Mamba and dynamically optimizes the spatial order, thus enabling more effective integration of multi-layer information. Extensive experiments conducted on challenging point cloud datasets across various tasks demonstrate that our PMA elevates the capability for point cloud understanding to a new level by fusing diverse complementary intermediate features. Code is available at https://github.com/zyh16143998882/PMA.
EvdCLIP: Improving Vision-Language Retrieval with Entity Visual Descriptions from Large Language Models
May 24, 2025Vision-language retrieval (VLR) has attracted significant attention in both academia and industry, which involves using text (or images) as queries to retrieve corresponding images (or text). However, existing methods often neglect the rich visual semantics knowledge of entities, thus leading to incorrect retrieval results. To address this problem, we propose the Entity Visual Description enhanced CLIP (EvdCLIP), designed to leverage the visual knowledge of entities to enrich queries. Specifically, since humans recognize entities through visual cues, we employ a large language model (LLM) to generate Entity Visual Descriptions (EVDs) as alignment cues to complement textual data. These EVDs are then integrated into raw queries to create visually-rich, EVD-enhanced queries. Furthermore, recognizing that EVD-enhanced queries may introduce noise or low-quality expansions, we develop a novel, trainable EVD-aware Rewriter (EaRW) for vision-language retrieval tasks. EaRW utilizes EVD knowledge and the generative capabilities of the language model to effectively rewrite queries. With our specialized training strategy, EaRW can generate high-quality and low-noise EVD-enhanced queries. Extensive quantitative and qualitative experiments on image-text retrieval benchmarks validate the superiority of EvdCLIP on vision-language retrieval tasks.
LARES: Latent Reasoning for Sequential Recommendation
May 22, 2025Sequential recommender systems have become increasingly important in real-world applications that model user behavior sequences to predict their preferences. However, existing sequential recommendation methods predominantly rely on non-reasoning paradigms, which may limit the model's computational capacity and result in suboptimal recommendation performance. To address these limitations, we present LARES, a novel and scalable LAtent REasoning framework for Sequential recommendation that enhances model's representation capabilities through increasing the computation density of parameters by depth-recurrent latent reasoning. Our proposed approach employs a recurrent architecture that allows flexible expansion of reasoning depth without increasing parameter complexity, thereby effectively capturing dynamic and intricate user interest patterns. A key difference of LARES lies in refining all input tokens at each implicit reasoning step to improve the computation utilization. To fully unlock the model's reasoning potential, we design a two-phase training strategy: (1) Self-supervised pre-training (SPT) with dual alignment objectives; (2) Reinforcement post-training (RPT). During the first phase, we introduce trajectory-level alignment and step-level alignment objectives, which enable the model to learn recommendation-oriented latent reasoning patterns without requiring supplementary annotated data. The subsequent phase utilizes reinforcement learning (RL) to harness the model's exploratory ability, further refining its reasoning capabilities. Comprehensive experiments on real-world benchmarks demonstrate our framework's superior performance. Notably, LARES exhibits seamless compatibility with existing advanced models, further improving their recommendation performance.
Action is All You Need: Dual-Flow Generative Ranking Network for Recommendation
May 22, 2025We introduce the Dual-Flow Generative Ranking Network (DFGR), a two-stream architecture designed for recommendation systems. DFGR integrates innovative interaction patterns between real and fake flows within the QKV modules of the self-attention mechanism, enhancing both training and inference efficiency. This approach effectively addresses a key limitation observed in Meta's proposed HSTU generative recommendation approach, where heterogeneous information volumes are mapped into identical vector spaces, leading to training instability. Unlike traditional recommendation models, DFGR only relies on user history behavior sequences and minimal attribute information, eliminating the need for extensive manual feature engineering. Comprehensive evaluations on open-source and industrial datasets reveal DFGR's superior performance compared to established baselines such as DIN, DCN, DIEN, and DeepFM. We also investigate optimal parameter allocation strategies under computational constraints, establishing DFGR as an efficient and effective next-generation generate ranking paradigm.
Embracing Collaboration Over Competition: Condensing Multiple Prompts for Visual In-Context Learning
Apr 30, 2025Visual In-Context Learning (VICL) enables adaptively solving vision tasks by leveraging pixel demonstrations, mimicking human-like task completion through analogy. Prompt selection is critical in VICL, but current methods assume the existence of a single "ideal" prompt in a pool of candidates, which in practice may not hold true. Multiple suitable prompts may exist, but individually they often fall short, leading to difficulties in selection and the exclusion of useful context. To address this, we propose a new perspective: prompt condensation. Rather than relying on a single prompt, candidate prompts collaborate to efficiently integrate informative contexts without sacrificing resolution. We devise Condenser, a lightweight external plugin that compresses relevant fine-grained context across multiple prompts. Optimized end-to-end with the backbone, Condenser ensures accurate integration of contextual cues. Experiments demonstrate Condenser outperforms state-of-the-arts across benchmark tasks, showing superior context compression, scalability with more prompts, and enhanced computational efficiency compared to ensemble methods, positioning it as a highly competitive solution for VICL. Code is open-sourced at https://github.com/gimpong/CVPR25-Condenser.
Search-Based Interaction For Conversation Recommendation via Generative Reward Model Based Simulated User
Apr 29, 2025Conversational recommendation systems (CRSs) use multi-turn interaction to capture user preferences and provide personalized recommendations. A fundamental challenge in CRSs lies in effectively understanding user preferences from conversations. User preferences can be multifaceted and complex, posing significant challenges for accurate recommendations even with access to abundant external knowledge. While interaction with users can clarify their true preferences, frequent user involvement can lead to a degraded user experience. To address this problem, we propose a generative reward model based simulated user, named GRSU, for automatic interaction with CRSs. The simulated user provides feedback to the items recommended by CRSs, enabling them to better capture intricate user preferences through multi-turn interaction. Inspired by generative reward models, we design two types of feedback actions for the simulated user: i.e., generative item scoring, which offers coarse-grained feedback, and attribute-based item critique, which provides fine-grained feedback. To ensure seamless integration, these feedback actions are unified into an instruction-based format, allowing the development of a unified simulated user via instruction tuning on synthesized data. With this simulated user, automatic multi-turn interaction with CRSs can be effectively conducted. Furthermore, to strike a balance between effectiveness and efficiency, we draw inspiration from the paradigm of reward-guided search in complex reasoning tasks and employ beam search for the interaction process. On top of this, we propose an efficient candidate ranking method to improve the recommendation results derived from interaction. Extensive experiments on public datasets demonstrate the effectiveness, efficiency, and transferability of our approach.
VLM as Policy: Common-Law Content Moderation Framework for Short Video Platform
Apr 21, 2025Exponentially growing short video platforms (SVPs) face significant challenges in moderating content detrimental to users' mental health, particularly for minors. The dissemination of such content on SVPs can lead to catastrophic societal consequences. Although substantial efforts have been dedicated to moderating such content, existing methods suffer from critical limitations: (1) Manual review is prone to human bias and incurs high operational costs. (2) Automated methods, though efficient, lack nuanced content understanding, resulting in lower accuracy. (3) Industrial moderation regulations struggle to adapt to rapidly evolving trends due to long update cycles. In this paper, we annotate the first SVP content moderation benchmark with authentic user/reviewer feedback to fill the absence of benchmark in this field. Then we evaluate various methods on the benchmark to verify the existence of the aforementioned limitations. We further propose our common-law content moderation framework named KuaiMod to address these challenges. KuaiMod consists of three components: training data construction, offline adaptation, and online deployment & refinement. Leveraging large vision language model (VLM) and Chain-of-Thought (CoT) reasoning, KuaiMod adequately models video toxicity based on sparse user feedback and fosters dynamic moderation policy with rapid update speed and high accuracy. Offline experiments and large-scale online A/B test demonstrates the superiority of KuaiMod: KuaiMod achieves the best moderation performance on our benchmark. The deployment of KuaiMod reduces the user reporting rate by 20% and its application in video recommendation increases both Daily Active User (DAU) and APP Usage Time (AUT) on several Kuaishou scenarios. We have open-sourced our benchmark at https://kuaimod.github.io.
InstructEngine: Instruction-driven Text-to-Image Alignment
Apr 14, 2025



Reinforcement Learning from Human/AI Feedback (RLHF/RLAIF) has been extensively utilized for preference alignment of text-to-image models. Existing methods face certain limitations in terms of both data and algorithm. For training data, most approaches rely on manual annotated preference data, either by directly fine-tuning the generators or by training reward models to provide training signals. However, the high annotation cost makes them difficult to scale up, the reward model consumes extra computation and cannot guarantee accuracy. From an algorithmic perspective, most methods neglect the value of text and only take the image feedback as a comparative signal, which is inefficient and sparse. To alleviate these drawbacks, we propose the InstructEngine framework. Regarding annotation cost, we first construct a taxonomy for text-to-image generation, then develop an automated data construction pipeline based on it. Leveraging advanced large multimodal models and human-defined rules, we generate 25K text-image preference pairs. Finally, we introduce cross-validation alignment method, which refines data efficiency by organizing semantically analogous samples into mutually comparable pairs. Evaluations on DrawBench demonstrate that InstructEngine improves SD v1.5 and SDXL's performance by 10.53% and 5.30%, outperforming state-of-the-art baselines, with ablation study confirming the benefits of InstructEngine's all components. A win rate of over 50% in human reviews also proves that InstructEngine better aligns with human preferences.