 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Paracrawl for Document-level Neural Machine Translation
Apr 20, 2023Document-level neural machine translation (NMT) has outperformed sentence-level NMT on a number of datasets. However, document-level NMT is still not widely adopted in real-world translation systems mainly due to the lack of large-scale general-domain training data for document-level NMT. We examine the effectiveness of using Paracrawl for learning document-level translation. Paracrawl is a large-scale parallel corpus crawled from the Internet and contains data from various domains. The official Paracrawl corpus was released as parallel sentences (extracted from parallel webpages) and therefore previous works only used Paracrawl for learning sentence-level translation. In this work, we extract parallel paragraphs from Paracrawl parallel webpages using automatic sentence alignments and we use the extracted parallel paragraphs as parallel documents for training document-level translation models. We show that document-level NMT models trained with only parallel paragraphs from Paracrawl can be used to translate real documents from TED, News and Europarl, outperforming sentence-level NMT models. We also perform a targeted pronoun evaluation and show that document-level models trained with Paracrawl data can help context-aware pronoun translation.
Vision-Language Models for Vision Tasks: A Survey
Apr 03, 2023Most visual recognition studies rely heavily on crowd-labelled data in deep neural networks (DNNs) training, and they usually train a DNN for each single visual recognition task, leading to a laborious and time-consuming visual recognition paradigm. To address the two challenges, Vision-Language Models (VLMs) have been intensively investigated recently, which learns rich vision-language correlation from web-scale image-text pairs that are almost infinitely available on the Internet and enables zero-shot predictions on various visual recognition tasks with a single VLM. This paper provides a systematic review of visual language models for various visual recognition tasks, including: (1) the background that introduces the development of visual recognition paradigms; (2) the foundations of VLM that summarize the widely-adopted network architectures, pre-training objectives, and downstream tasks; (3) the widely-adopted datasets in VLM pre-training and evaluations; (4) the review and categorization of existing VLM pre-training methods, VLM transfer learning methods, and VLM knowledge distillation methods; (5) the benchmarking, analysis and discussion of the reviewed methods; (6) several research challenges and potential research directions that could be pursued in the future VLM studies for visual recognition. A project associated with this survey has been created at https://github.com/jingyi0000/VLM_survey.
Semantic-visual Guided Transformer for Few-shot Class-incremental Learning
Mar 27, 2023



Few-shot class-incremental learning (FSCIL) has recently attracted extensive attention in various areas. Existing FSCIL methods highly depend on the robustness of the feature backbone pre-trained on base classes. In recent years, different Transformer variants have obtained significant processes in the feature representation learning of massive fields. Nevertheless, the progress of the Transformer in FSCIL scenarios has not achieved the potential promised in other fields so far. In this paper, we develop a semantic-visual guided Transformer (SV-T) to enhance the feature extracting capacity of the pre-trained feature backbone on incremental classes. Specifically, we first utilize the visual (image) labels provided by the base classes to supervise the optimization of the Transformer. And then, a text encoder is introduced to automatically generate the corresponding semantic (text) labels for each image from the base classes. Finally, the constructed semantic labels are further applied to the Transformer for guiding its hyperparameters updating. Our SV-T can take full advantage of more supervision information from base classes and further enhance the training robustness of the feature backbone. More importantly, our SV-T is an independent method, which can directly apply to the existing FSCIL architectures for acquiring embeddings of various incremental classes. Extensive experiments on three benchmarks, two FSCIL architectures, and two Transformer variants show that our proposed SV-T obtains a significant improvement in comparison to the existing state-of-the-art FSCIL methods.
Indescribable Multi-modal Spatial Evaluator
Mar 02, 2023



Multi-modal image registration spatially aligns two images with different distributions. One of its major challenges is that images acquired from different imaging machines have different imaging distributions, making it difficult to focus only on the spatial aspect of the images and ignore differences in distributions. In this study, we developed a self-supervised approach, Indescribable Multi-model Spatial Evaluator (IMSE), to address multi-modal image registration. IMSE creates an accurate multi-modal spatial evaluator to measure spatial differences between two images, and then optimizes registration by minimizing the error predicted of the evaluator. To optimize IMSE performance, we also proposed a new style enhancement method called Shuffle Remap which randomizes the image distribution into multiple segments, and then randomly disorders and remaps these segments, so that the distribution of the original image is changed. Shuffle Remap can help IMSE to predict the difference in spatial location from unseen target distributions. Our results show that IMSE outperformed the existing methods for registration using T1-T2 and CT-MRI datasets. IMSE also can be easily integrated into the traditional registration process, and can provide a convenient way to evaluate and visualize registration results. IMSE also has the potential to be used as a new paradigm for image-to-image translation. Our code is available at https://github.com/Kid-Liet/IMSE.
PMT-IQA: Progressive Multi-task Learning for Blind Image Quality Assessment
Jan 03, 2023



Blind image quality assessment (BIQA) remains challenging due to the diversity of distortion and image content variation, which complicate the distortion patterns crossing different scales and aggravate the difficulty of the regression problem for BIQA. However, existing BIQA methods often fail to consider multi-scale distortion patterns and image content, and little research has been done on learning strategies to make the regression model produce better performance. In this paper, we propose a simple yet effective Progressive Multi-Task Image Quality Assessment (PMT-IQA) model, which contains a multi-scale feature extraction module (MS) and a progressive multi-task learning module (PMT), to help the model learn complex distortion patterns and better optimize the regression issue to align with the law of human learning process from easy to hard. To verify the effectiveness of the proposed PMT-IQA model, we conduct experiments on four widely used public datasets, and the experimental results indicate that the performance of PMT-IQA is superior to the comparison approaches, and both MS and PMT modules improve the model's performance.
Generalizable Black-Box Adversarial Attack with Meta Learning
Jan 01, 2023In the scenario of black-box adversarial attack, the target model's parameters are unknown, and the attacker aims to find a successful adversarial perturbation based on query feedback under a query budget. Due to the limited feedback information, existing query-based black-box attack methods often require many queries for attacking each benign example. To reduce query cost, we propose to utilize the feedback information across historical attacks, dubbed example-level adversarial transferability. Specifically, by treating the attack on each benign example as one task, we develop a meta-learning framework by training a meta-generator to produce perturbations conditioned on benign examples. When attacking a new benign example, the meta generator can be quickly fine-tuned based on the feedback information of the new task as well as a few historical attacks to produce effective perturbations. Moreover, since the meta-train procedure consumes many queries to learn a generalizable generator, we utilize model-level adversarial transferability to train the meta-generator on a white-box surrogate model, then transfer it to help the attack against the target model. The proposed framework with the two types of adversarial transferability can be naturally combined with any off-the-shelf query-based attack methods to boost their performance, which is verified by extensive experiments.
Domain Adaptive Scene Text Detection via Subcategorization
Dec 01, 2022Most existing scene text detectors require large-scale training data which cannot scale well due to two major factors: 1) scene text images often have domain-specific distributions; 2) collecting large-scale annotated scene text images is laborious. We study domain adaptive scene text detection, a largely neglected yet very meaningful task that aims for optimal transfer of labelled scene text images while handling unlabelled images in various new domains. Specifically, we design SCAST, a subcategory-aware self-training technique that mitigates the network overfitting and noisy pseudo labels in domain adaptive scene text detection effectively. SCAST consists of two novel designs. For labelled source data, it introduces pseudo subcategories for both foreground texts and background stuff which helps train more generalizable source models with multi-class detection objectives. For unlabelled target data, it mitigates the network overfitting by co-regularizing the binary and subcategory classifiers trained in the source domain. Extensive experiments show that SCAST achieves superior detection performance consistently across multiple public benchmarks, and it also generalizes well to other domain adaptive detection tasks such as vehicle detection.
Towards Efficient Use of Multi-Scale Features in Transformer-Based Object Detectors
Aug 24, 2022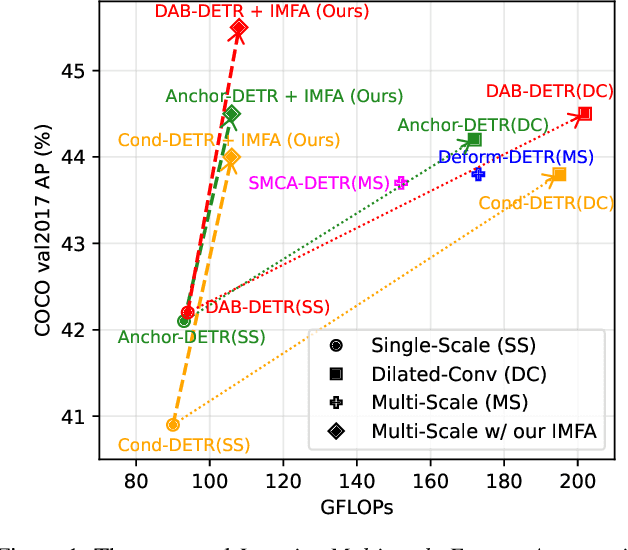
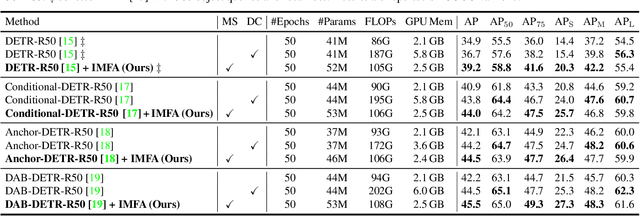
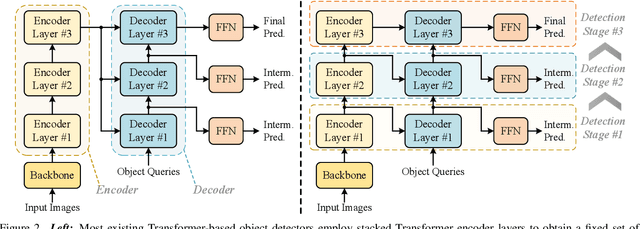
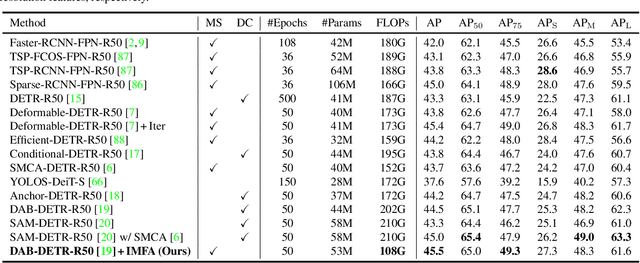
Multi-scale features have been proven highly effective for object detection, and most ConvNet-based object detectors adopt Feature Pyramid Network (FPN) as a basic component for exploiting multi-scale features. However, for the recently proposed Transformer-based object detectors, directly incorporating multi-scale features leads to prohibitive computational overhead due to the high complexity of the attention mechanism for processing high-resolution features. This paper presents Iterative Multi-scale Feature Aggregation (IMFA) -- a generic paradigm that enables the efficient use of multi-scale features in Transformer-based object detectors. The core idea is to exploit sparse multi-scale features from just a few crucial locations, and it is achieved with two novel designs. First, IMFA rearranges the Transformer encoder-decoder pipeline so that the encoded features can be iteratively updated based on the detection predictions. Second, IMFA sparsely samples scale-adaptive features for refined detection from just a few keypoint locations under the guidance of prior detection predictions. As a result, the sampled multi-scale features are sparse yet still highly beneficial for object detection. Extensive experiments show that the proposed IMFA boosts the performance of multiple Transformer-based object detectors significantly yet with slight computational overhead. Project page: https://github.com/ZhangGongjie/IMFA.
Automating DBSCAN via Deep Reinforcement Learning
Aug 09, 2022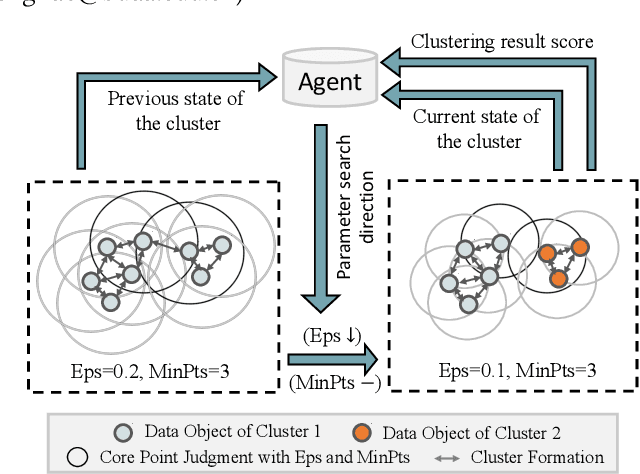
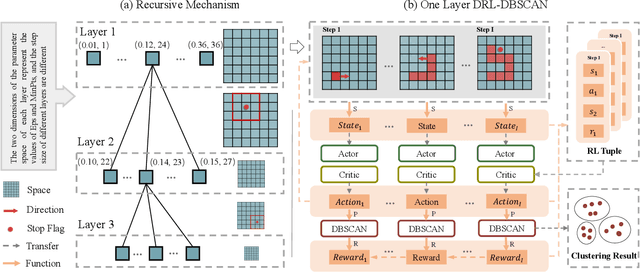
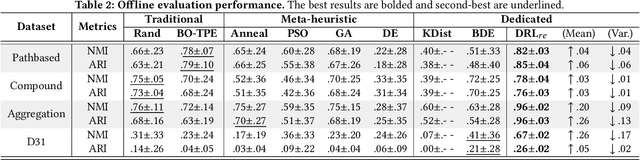
DBSCAN is widely used in many scientific and engineering fields because of its simplicity and practicality. However, due to its high sensitivity parameters, the accuracy of the clustering result depends heavily on practical experience. In this paper, we first propose a novel Deep Reinforcement Learning guided automatic DBSCAN parameters search framework, namely DRL-DBSCAN. The framework models the process of adjusting the parameter search direction by perceiving the clustering environment as a Markov decision process, which aims to find the best clustering parameters without manual assistance. DRL-DBSCAN learns the optimal clustering parameter search policy for different feature distributions via interacting with the clusters, using a weakly-supervised reward training policy network. In addition, we also present a recursive search mechanism driven by the scale of the data to efficiently and controllably process large parameter spaces. Extensive experiments are conducted on five artificial and real-world datasets based on the proposed four working modes. The results of offline and online tasks show that the DRL-DBSCAN not only consistently improves DBSCAN clustering accuracy by up to 26% and 25% respectively, but also can stably find the dominant parameters with high computational efficiency. The code is available at https://github.com/RingBDStack/DRL-DBSCAN.
Learning Series-Parallel Lookup Tables for Efficient Image Super-Resolution
Jul 26, 2022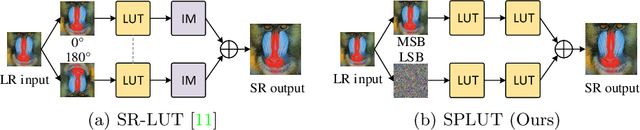
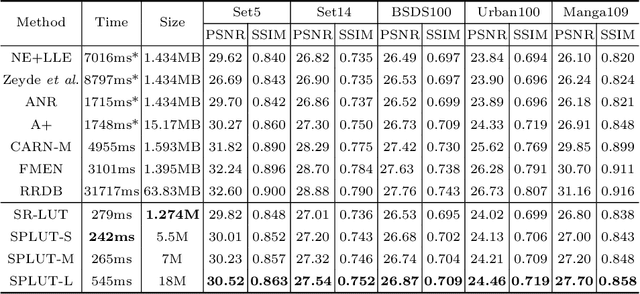
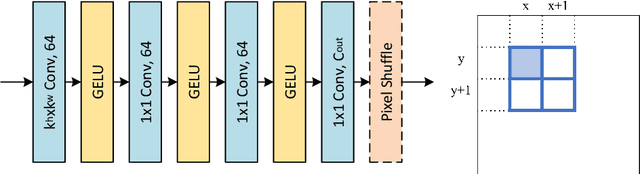
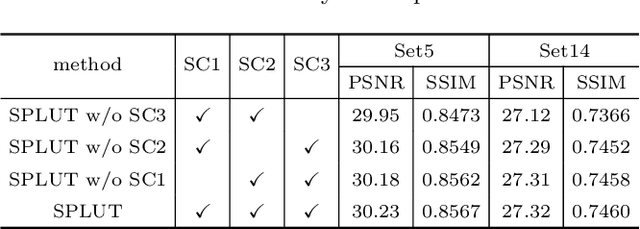
Lookup table (LUT) has shown its efficacy in low-level vision tasks due to the valuable characteristics of low computational cost and hardware independence. However, recent attempts to address the problem of single image super-resolution (SISR) with lookup tables are highly constrained by the small receptive field size. Besides, their frameworks of single-layer lookup tables limit the extension and generalization capacities of the model. In this paper, we propose a framework of series-parallel lookup tables (SPLUT) to alleviate the above issues and achieve efficient image super-resolution. On the one hand, we cascade multiple lookup tables to enlarge the receptive field of each extracted feature vector. On the other hand, we propose a parallel network which includes two branches of cascaded lookup tables which process different components of the input low-resolution images. By doing so, the two branches collaborate with each other and compensate for the precision loss of discretizing input pixels when establishing lookup tables. Compared to previous lookup table-based methods, our framework has stronger representation abilities with more flexible architectures. Furthermore, we no longer need interpolation methods which introduce redundant computations so that our method can achieve faster inference speed. Extensive experimental results on five popular benchmark datasets show that our method obtains superior SISR performance in a more efficient way. The code is available at https://github.com/zhjy2016/SPLUT.