 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing 3D Neural Hemodynamics using Sparse Ultrasound Localization Microscopy Data
May 26, 2026Ultrasound Localization Microscopy (ULM) has presented great potential in functional imaging, benefiting from its ability to reconstruct deep microvasculature. However, the hemodynamic reconstruction is compromised by sparsity in the ULM data, as a limited number of MB tracks cannot sample the complete speed profile in one vessel. Here, we propose to reconstruct hemodynamics using sparse ULM velocity maps by solving a laminar flow model through stochastic variational inference. In addition to vascular geometry and flow velocity maps, the proposed method generates two new ULM maps - a pressure gradient map and a map describing uncertainty of the estimation. By investigating the effect of sparsity in ULM maps on the quantification and visualization of hemodynamics, we demonstrate the effectiveness of the proposed method in dealing with sparse ULM maps via simulations and 3D rat brain imaging. Accurately reconstructing a broad range of hemodynamic parameters and associate uncertanties using sparse ULM data may help detect subtle and dynamic brain activity.
Is there a relationship between Mean Opinion Score (MOS) and Just Noticeable Difference (JND)?
Feb 19, 2026Evaluating perceived video quality is essential for ensuring high Quality of Experience (QoE) in modern streaming applications. While existing subjective datasets and Video Quality Metrics (VQMs) cover a broad quality range, many practical use cases especially for premium users focus on high quality scenarios requiring finer granularity. Just Noticeable Difference (JND) has emerged as a key concept for modeling perceptual thresholds in these high end regions and plays an important role in perceptual bitrate ladder construction. However, the relationship between JND and the more widely used Mean Opinion Score (MOS) remains unclear. In this paper, we conduct a Degradation Category Rating (DCR) subjective study based on an existing JND dataset to examine how MOS corresponds to the 75% Satisfied User Ratio (SUR) points of the 1st and 2nd JNDs. We find that while MOS values at JND points generally align with theoretical expectations (e.g., 4.75 for the 75% SUR of the 1st JND), the reverse mapping from MOS to JND is ambiguous due to overlapping confidence intervals across PVS indices. Statistical significance analysis further shows that DCR studies with limited participants may not detect meaningful differences between reference and JND videos.
Determining the utility of ultrafast nonlinear contrast enhanced and super resolution ultrasound for imaging microcirculation in the human small intestine
May 16, 2025The regulation of intestinal blood flow is critical to gastrointestinal function. Imaging the intestinal mucosal micro-circulation in vivo has the potential to provide new insight into the gut physiology and pathophysiology. We aimed to determine whether ultrafast contrast enhanced ultrasound (CEUS) and super-resolution ultrasound localisation microscopy (SRUS/ULM) could be a useful tool for imaging the small intestine microcirculation in vivo non-invasively and for detecting changes in blood flow in the duodenum. Ultrafast CEUS and SRUS/ULM were used to image the small intestinal microcirculation in a cohort of 20 healthy volunteers (BMI<25). Participants were imaged while conscious and either having been fasted, or following ingestion of a liquid meal or water control, or under acute stress. For the first time we have performed ultrafast CEUS and ULM on the human small intestine, providing unprecedented resolution images of the intestinal microcirculation. We evaluated flow speed inside small vessels in healthy volunteers (2.78 +/- 0.05 mm/s, mean +/- SEM) and quantified changes in the perfusion of this microcirculation in response to nutrient ingestion. Perfusion of the microvasculature of the intestinal mucosa significantly increased post-prandially (36.2% +/- 12.2%, mean +/- SEM, p<0.05). The feasibility of 3D SRUS/ULM was also demonstrated. This study demonstrates the potential utility of ultrafast CEUS for assessing perfusion and detecting changes in blood flow in the duodenum. SRUS/ULM also proved a useful tool to image the microvascular blood flow in vivo non-invasively and to evaluate blood speed inside the microvasculature of the human small intestine.
V2X-LLM: Enhancing V2X Integration and Understanding in Connected Vehicle Corridors
Mar 04, 2025



The advancement of Connected and Automated Vehicles (CAVs) and Vehicle-to-Everything (V2X) offers significant potential for enhancing transportation safety, mobility, and sustainability. However, the integration and analysis of the diverse and voluminous V2X data, including Basic Safety Messages (BSMs) and Signal Phase and Timing (SPaT) data, present substantial challenges, especially on Connected Vehicle Corridors. These challenges include managing large data volumes, ensuring real-time data integration, and understanding complex traffic scenarios. Although these projects have developed an advanced CAV data pipeline that enables real-time communication between vehicles, infrastructure, and other road users for managing connected vehicle and roadside unit (RSU) data, significant hurdles in data comprehension and real-time scenario analysis and reasoning persist. To address these issues, we introduce the V2X-LLM framework, a novel enhancement to the existing CV data pipeline. V2X-LLM leverages Large Language Models (LLMs) to improve the understanding and real-time analysis of V2X data. The framework includes four key tasks: Scenario Explanation, offering detailed narratives of traffic conditions; V2X Data Description, detailing vehicle and infrastructure statuses; State Prediction, forecasting future traffic states; and Navigation Advisory, providing optimized routing instructions. By integrating LLM-driven reasoning with V2X data within the data pipeline, the V2X-LLM framework offers real-time feedback and decision support for traffic management. This integration enhances the accuracy of traffic analysis, safety, and traffic optimization. Demonstrations in a real-world urban corridor highlight the framework's potential to advance intelligent transportation systems.
Online 4D Ultrasound-Guided Robotic Tracking Enables 3D Ultrasound Localisation Microscopy with Large Tissue Displacements
Sep 17, 2024



Super-Resolution Ultrasound (SRUS) imaging through localising and tracking microbubbles, also known as Ultrasound Localisation Microscopy (ULM), has demonstrated significant potential for reconstructing microvasculature and flows with sub-diffraction resolution in clinical diagnostics. However, imaging organs with large tissue movements, such as those caused by respiration, presents substantial challenges. Existing methods often require breath holding to maintain accumulation accuracy, which limits data acquisition time and ULM image saturation. To improve image quality in the presence of large tissue movements, this study introduces an approach integrating high-frame-rate ultrasound with online precise robotic probe control. Tested on a microvasculature phantom with translation motions up to 20 mm, twice the aperture size of the matrix array used, our method achieved real-time tracking of the moving phantom and imaging volume rate at 85 Hz, keeping majority of the target volume in the imaging field of view. ULM images of the moving cross channels in the phantom were successfully reconstructed in post-processing, demonstrating the feasibility of super-resolution imaging under large tissue motions. This represents a significant step towards ULM imaging of organs with large motion.
On the benefit of parameter-driven approaches for the modeling and the prediction of Satisfied User Ratio for compressed video
Jun 20, 2022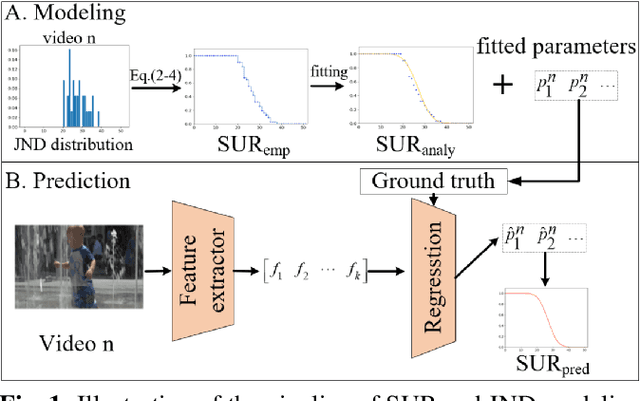

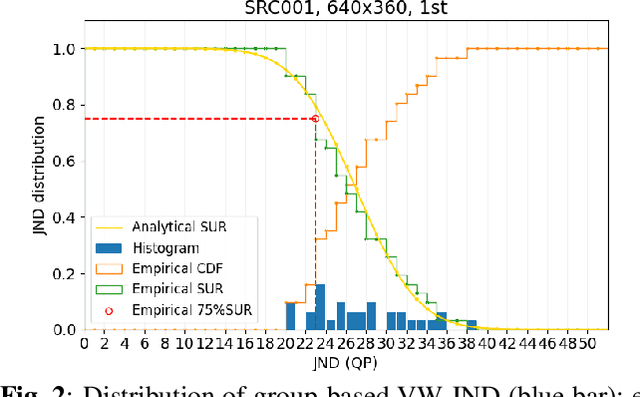
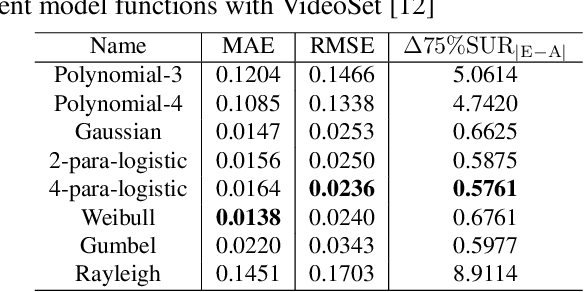
The human eye cannot perceive small pixel changes in images or videos until a certain threshold of distortion. In the context of video compression, Just Noticeable Difference (JND) is the smallest distortion level from which the human eye can perceive the difference between reference video and the distorted/compressed one. Satisfied-User-Ratio (SUR) curve is the complementary cumulative distribution function of the individual JNDs of a viewer group. However, most of the previous works predict each point in SUR curve by using features both from source video and from compressed videos with assumption that the group-based JND annotations follow Gaussian distribution, which is neither practical nor accurate. In this work, we firstly compared various common functions for SUR curve modeling. Afterwards, we proposed a novel parameter-driven method to predict the video-wise SUR from video features. Besides, we compared the prediction results of source-only features based (SRC-based) models and source plus compressed videos features (SRC+PVS-based) models.
A Framework to Map VMAF with the Probability of Just Noticeable Difference between Video Encoding Recipes
May 20, 2022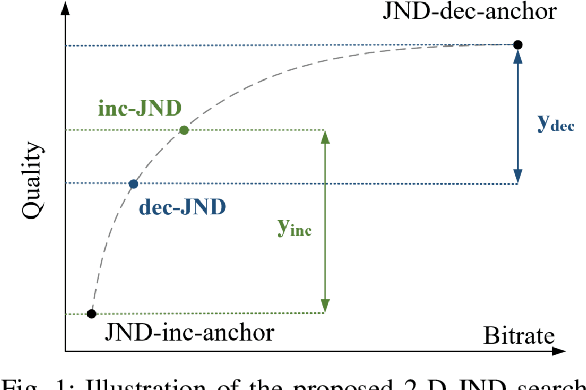
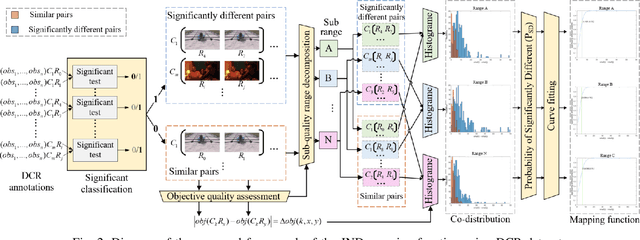
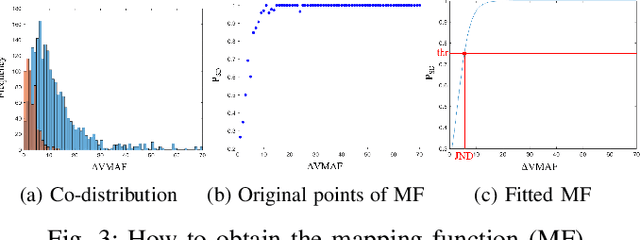
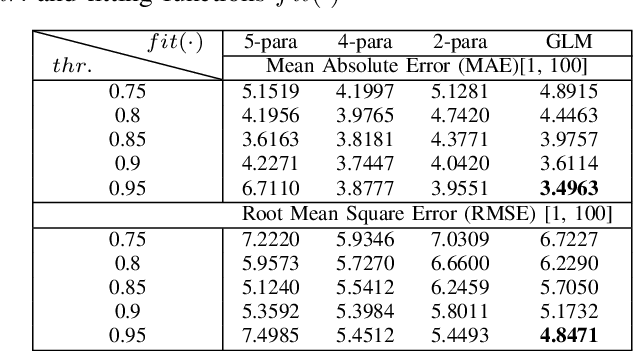
Just Noticeable Difference (JND) model developed based on Human Vision System (HVS) through subjective studies is valuable for many multimedia use cases. In the streaming industries, it is commonly applied to reach a good balance between compression efficiency and perceptual quality when selecting video encoding recipes. Nevertheless, recent state-of-the-art deep learning based JND prediction model relies on large-scale JND ground truth that is expensive and time consuming to collect. Most of the existing JND datasets contain limited number of contents and are limited to a certain codec (e.g., H264). As a result, JND prediction models that were trained on such datasets are normally not agnostic to the codecs. To this end, in order to decouple encoding recipes and JND estimation, we propose a novel framework to map the difference of objective Video Quality Assessment (VQA) scores, i.e., VMAF, between two given videos encoded with different encoding recipes from the same content to the probability of having just noticeable difference between them. The proposed probability mapping model learns from DCR test data, which is significantly cheaper compared to standard JND subjective test. As we utilize objective VQA metric (e.g., VMAF that trained with contents encoded with different codecs) as proxy to estimate JND, our model is agnostic to codecs and computationally efficient. Throughout extensive experiments, it is demonstrated that the proposed model is able to estimate JND values efficiently.
Few-Shot Object Detection in Real Life: Case Study on Auto-Harvest
Nov 05, 2020


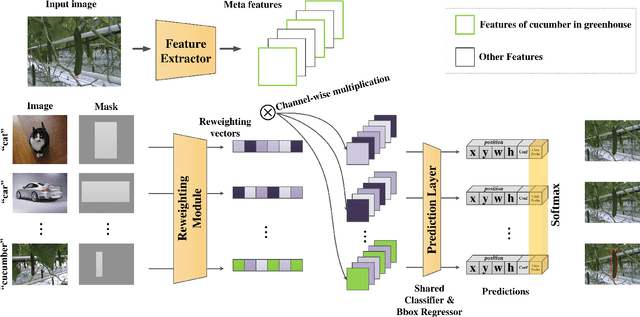
Confinement during COVID-19 has caused serious effects on agriculture all over the world. As one of the efficient solutions, mechanical harvest/auto-harvest that is based on object detection and robotic harvester becomes an urgent need. Within the auto-harvest system, robust few-shot object detection model is one of the bottlenecks, since the system is required to deal with new vegetable/fruit categories and the collection of large-scale annotated datasets for all the novel categories is expensive. There are many few-shot object detection models that were developed by the community. Yet whether they could be employed directly for real life agricultural applications is still questionable, as there is a context-gap between the commonly used training datasets and the images collected in real life agricultural scenarios. To this end, in this study, we present a novel cucumber dataset and propose two data augmentation strategies that help to bridge the context-gap. Experimental results show that 1) the state-of-the-art few-shot object detection model performs poorly on the novel `cucumber' category; and 2) the proposed augmentation strategies outperform the commonly used ones.
Accelerating Proposal Generation Network for \\Fast Face Detection on Mobile Devices
Apr 27, 2019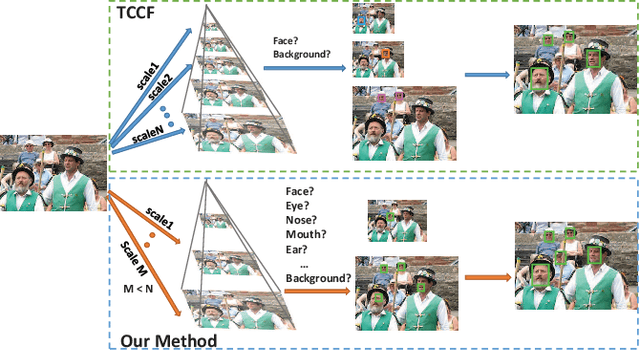

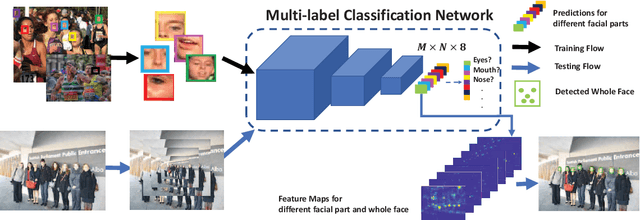
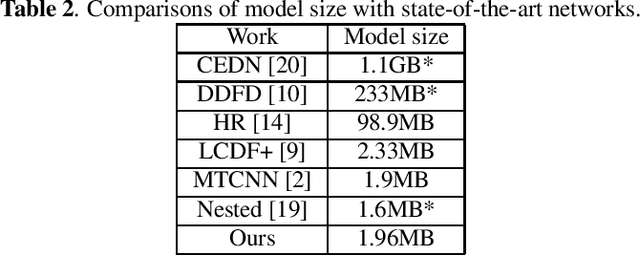
Face detection is a widely studied problem over the past few decades. Recently, significant improvements have been achieved via the deep neural network, however, it is still challenging to directly apply these techniques to mobile devices for its limited computational power and memory. In this work, we present a proposal generation acceleration framework for real-time face detection. More specifically, we adopt a popular cascaded convolutional neural network (CNN) as the basis, then apply our acceleration approach on the basic framework to speed up the model inference time. We are motivated by the observation that the computation bottleneck of this framework arises from the proposal generation stage, where each level of the dense image pyramid has to go through the network. In this work, we reduce the number of image pyramid levels by utilizing both global and local facial characteristics (i.e., global face and facial parts). Experimental results on public benchmarks WIDER-face and FDDB demonstrate the satisfactory performance and faster speed compared to the state-of-the-arts. %the comparable accuracy to state-of-the-arts with faster speed.
Efficient Incremental Learning for Mobile Object Detection
Mar 26, 2019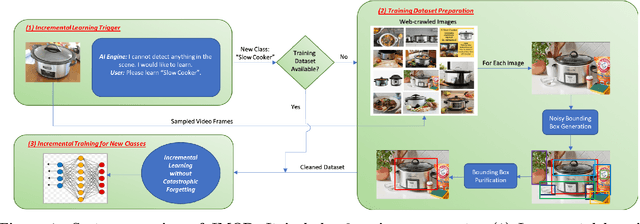
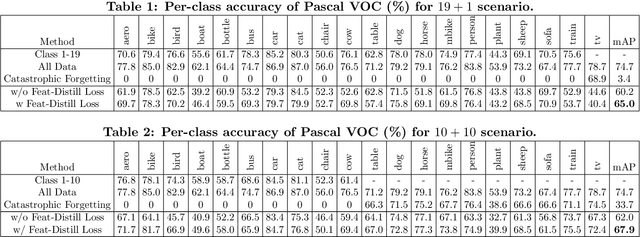
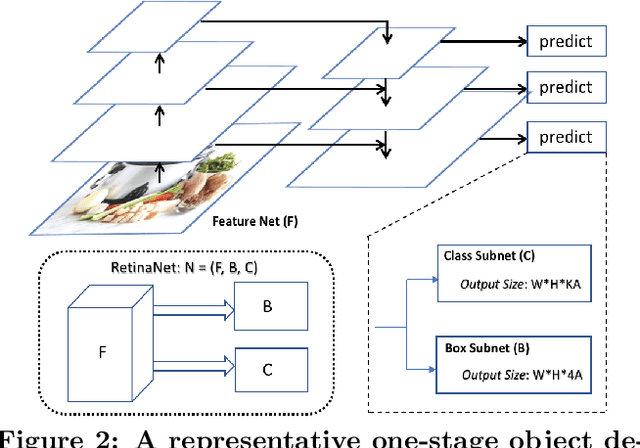
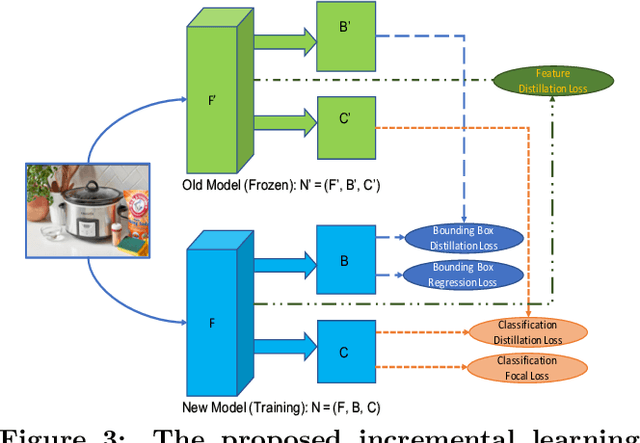
Object detection models shipped with camera-equipped mobile devices cannot cover the objects of interest for every user. Therefore, the incremental learning capability is a critical feature for a robust and personalized mobile object detection system that many applications would rely on. In this paper, we present an efficient yet practical system, IMOD, to incrementally train an existing object detection model such that it can detect new object classes without losing its capability to detect old classes. The key component of IMOD is a novel incremental learning algorithm that trains end-to-end for one-stage object detection deep models only using training data of new object classes. Specifically, to avoid catastrophic forgetting, the algorithm distills three types of knowledge from the old model to mimic the old model's behavior on object classification, bounding box regression and feature extraction. In addition, since the training data for the new classes may not be available, a real-time dataset construction pipeline is designed to collect training images on-the-fly and automatically label the images with both category and bounding box annotations. We have implemented IMOD under both mobile-cloud and mobile-only setups. Experiment results show that the proposed system can learn to detect a new object class in just a few minutes, including both dataset construction and model training. In comparison, traditional fine-tuning based method may take a few hours for training, and in most cases would also need a tedious and costly manual dataset labeling step.