 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT)
Sep 16, 2019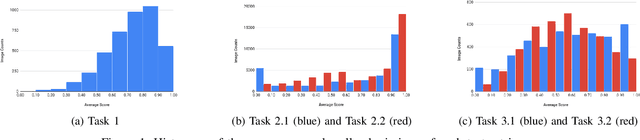



This paper reports the ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT) that consists of three major challenges: i) scene text detection, ii) scene text recognition, and iii) scene text spotting. A total of 78 submissions from 46 unique teams/individuals were received for this competition. The top performing score of each challenge is as follows: i) T1 - 82.65%, ii) T2.1 - 74.3%, iii) T2.2 - 85.32%, iv) T3.1 - 53.86%, and v) T3.2 - 54.91%. Apart from the results, this paper also details the ArT dataset, tasks description, evaluation metrics and participants methods. The dataset, the evaluation kit as well as the results are publicly available at https://rrc.cvc.uab.es/?ch=14
A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning
Aug 15, 2019
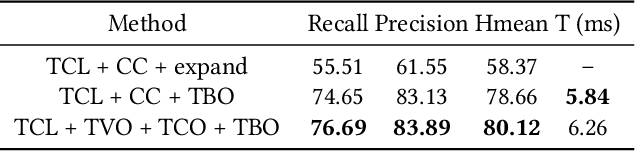

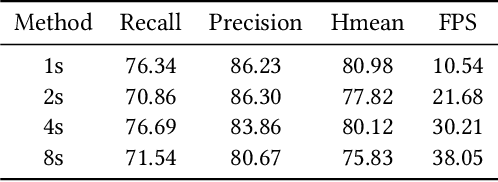
Detecting scene text of arbitrary shapes has been a challenging task over the past years. In this paper, we propose a novel segmentation-based text detector, namely SAST, which employs a context attended multi-task learning framework based on a Fully Convolutional Network (FCN) to learn various geometric properties for the reconstruction of polygonal representation of text regions. Taking sequential characteristics of text into consideration, a Context Attention Block is introduced to capture long-range dependencies of pixel information to obtain a more reliable segmentation. In post-processing, a Point-to-Quad assignment method is proposed to cluster pixels into text instances by integrating both high-level object knowledge and low-level pixel information in a single shot. Moreover, the polygonal representation of arbitrarily-shaped text can be extracted with the proposed geometric properties much more effectively. Experiments on several benchmarks, including ICDAR2015, ICDAR2017-MLT, SCUT-CTW1500, and Total-Text, demonstrate that SAST achieves better or comparable performance in terms of accuracy. Furthermore, the proposed algorithm runs at 27.63 FPS on SCUT-CTW1500 with a Hmean of 81.0% on a single NVIDIA Titan Xp graphics card, surpassing most of the existing segmentation-based methods.
* 9 pages, 6 figures, 7 tables, To appear in ACM Multimedia 2019
Editing Text in the Wild
Aug 08, 2019
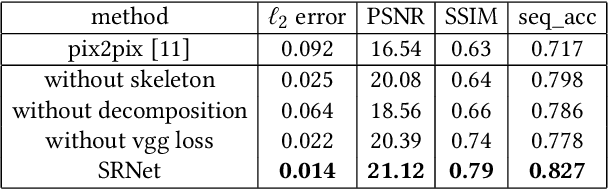
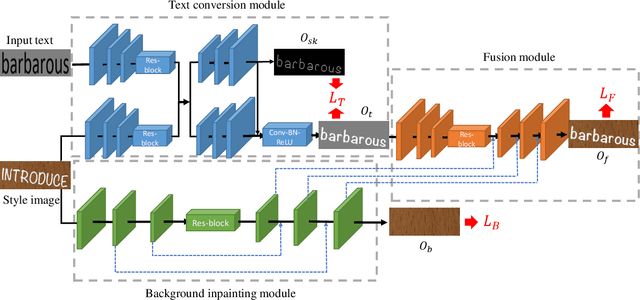

In this paper, we are interested in editing text in natural images, which aims to replace or modify a word in the source image with another one while maintaining its realistic look. This task is challenging, as the styles of both background and text need to be preserved so that the edited image is visually indistinguishable from the source image. Specifically, we propose an end-to-end trainable style retention network (SRNet) that consists of three modules: text conversion module, background inpainting module and fusion module. The text conversion module changes the text content of the source image into the target text while keeping the original text style. The background inpainting module erases the original text, and fills the text region with appropriate texture. The fusion module combines the information from the two former modules, and generates the edited text images. To our knowledge, this work is the first attempt to edit text in natural images at the word level. Both visual effects and quantitative results on synthetic and real-world dataset (ICDAR 2013) fully confirm the importance and necessity of modular decomposition. We also conduct extensive experiments to validate the usefulness of our method in various real-world applications such as text image synthesis, augmented reality (AR) translation, information hiding, etc.
Biphasic Learning of GANs for High-Resolution Image-to-Image Translation
Apr 14, 2019
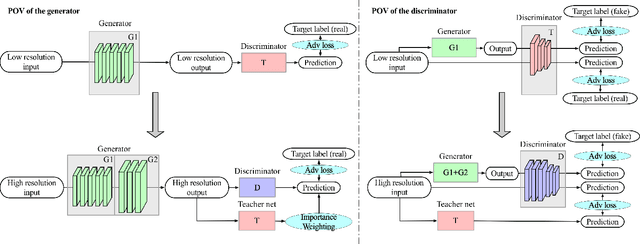
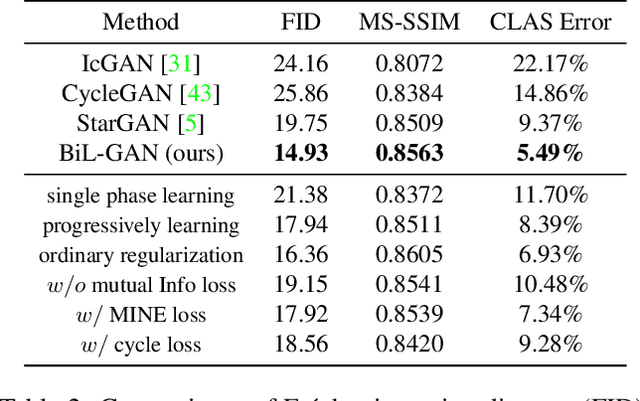

Despite that the performance of image-to-image translation has been significantly improved by recent progress in generative models, current methods still suffer from severe degradation in training stability and sample quality when applied to the high-resolution situation. In this work, we present a novel training framework for GANs, namely biphasic learning, to achieve image-to-image translation in multiple visual domains at $1024^2$ resolution. Our core idea is to design an adjustable objective function that varies across training phases. Within the biphasic learning framework, we propose a novel inherited adversarial loss to achieve the enhancement of model capacity and stabilize the training phase transition. Furthermore, we introduce a perceptual-level consistency loss through mutual information estimation and maximization. To verify the superiority of the proposed method, we apply it to a wide range of face-related synthesis tasks and conduct experiments on multiple large-scale datasets. Through comprehensive quantitative analyses, we demonstrate that our method significantly outperforms existing methods.
PyramidBox++: High Performance Detector for Finding Tiny Face
Mar 31, 2019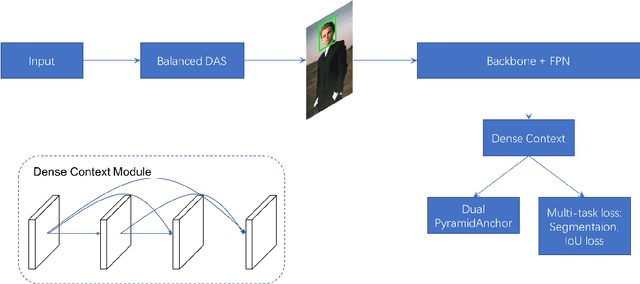


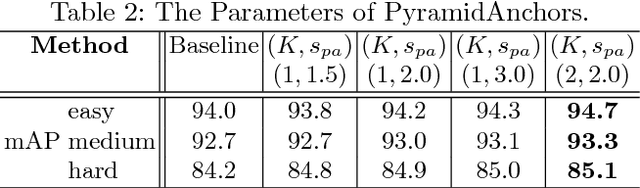
With the rapid development of deep convolutional neural network, face detection has made great progress in recent years. WIDER FACE dataset, as a main benchmark, contributes greatly to this area. A large amount of methods have been put forward where PyramidBox designs an effective data augmentation strategy (Data-anchor-sampling) and context-based module for face detector. In this report, we improve each part to further boost the performance, including Balanced-data-anchor-sampling, Dual-PyramidAnchors and Dense Context Module. Specifically, Balanced-data-anchor-sampling obtains more uniform sampling of faces with different sizes. Dual-PyramidAnchors facilitate feature learning by introducing progressive anchor loss. Dense Context Module with dense connection not only enlarges receptive filed, but also passes information efficiently. Integrating these techniques, PyramidBox++ is constructed and achieves state-of-the-art performance in hard set.
PyramidBox: A Context-assisted Single Shot Face Detector
Aug 17, 2018
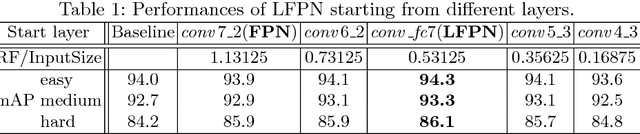
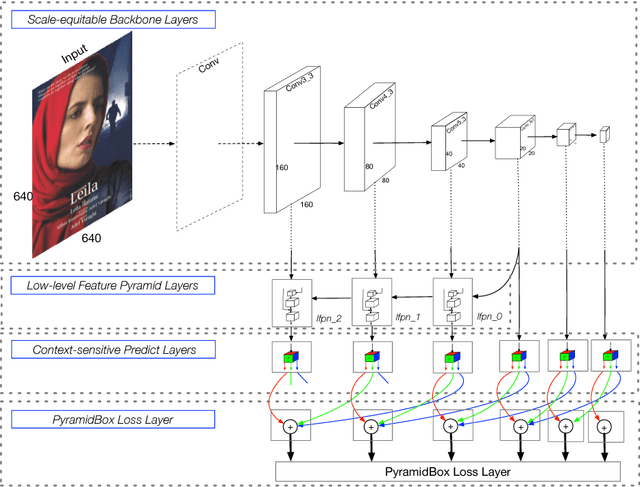
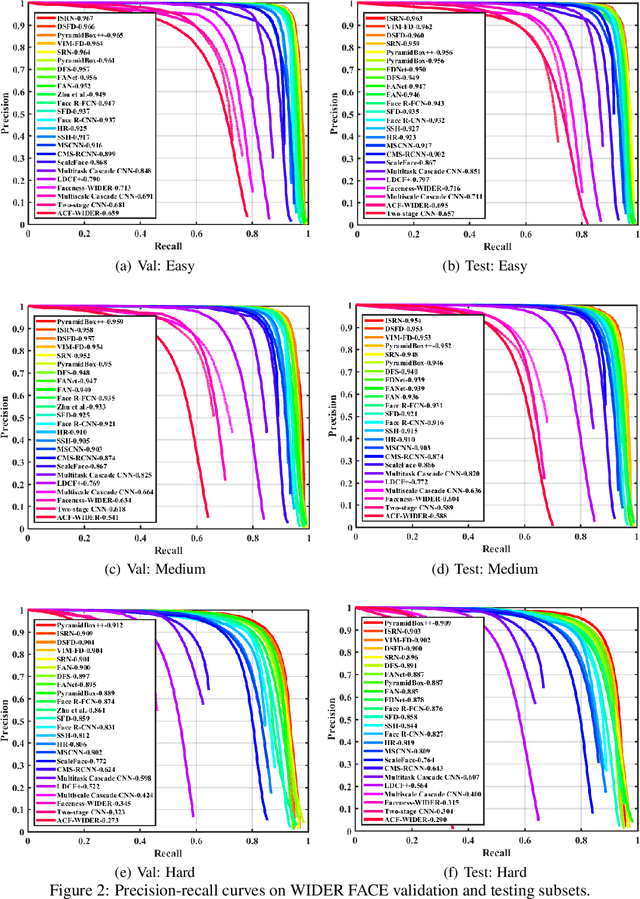
Face detection has been well studied for many years and one of remaining challenges is to detect small, blurred and partially occluded faces in uncontrolled environment. This paper proposes a novel context-assisted single shot face detector, named \emph{PyramidBox} to handle the hard face detection problem. Observing the importance of the context, we improve the utilization of contextual information in the following three aspects. First, we design a novel context anchor to supervise high-level contextual feature learning by a semi-supervised method, which we call it PyramidAnchors. Second, we propose the Low-level Feature Pyramid Network to combine adequate high-level context semantic feature and Low-level facial feature together, which also allows the PyramidBox to predict faces of all scales in a single shot. Third, we introduce a context-sensitive structure to increase the capacity of prediction network to improve the final accuracy of output. In addition, we use the method of Data-anchor-sampling to augment the training samples across different scales, which increases the diversity of training data for smaller faces. By exploiting the value of context, PyramidBox achieves superior performance among the state-of-the-art over the two common face detection benchmarks, FDDB and WIDER FACE. Our code is available in PaddlePaddle: \href{https://github.com/PaddlePaddle/models/tree/develop/fluid/face_detection}{\url{https://github.com/PaddlePaddle/models/tree/develop/fluid/face_detection}}.
* 21 pages, 12 figures
Targeting Ultimate Accuracy: Face Recognition via Deep Embedding
Jul 23, 2015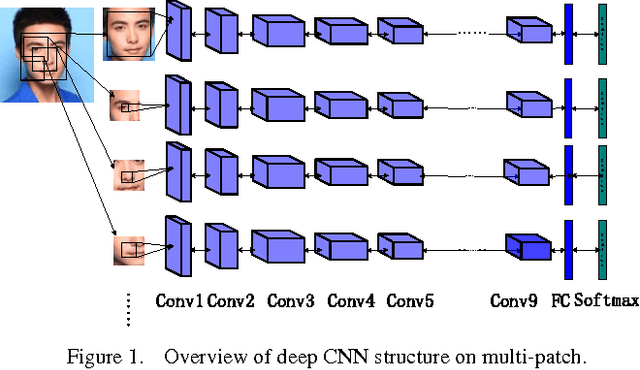
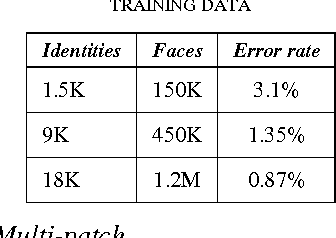
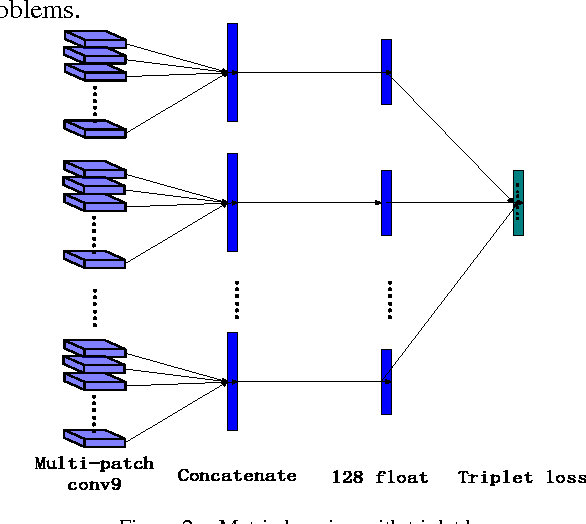
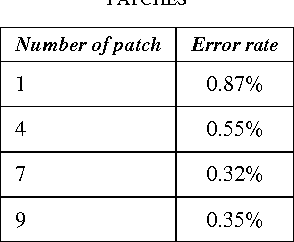
Face Recognition has been studied for many decades. As opposed to traditional hand-crafted features such as LBP and HOG, much more sophisticated features can be learned automatically by deep learning methods in a data-driven way. In this paper, we propose a two-stage approach that combines a multi-patch deep CNN and deep metric learning, which extracts low dimensional but very discriminative features for face verification and recognition. Experiments show that this method outperforms other state-of-the-art methods on LFW dataset, achieving 99.77% pair-wise verification accuracy and significantly better accuracy under other two more practical protocols. This paper also discusses the importance of data size and the number of patches, showing a clear path to practical high-performance face recognition systems in real world.