 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSycophancy Towards Researchers Drives Performative Misalignment
Jun 07, 2026The increasing situational awareness of language models raises safety concerns: models might be aware when they are evaluated, and adjust their behavior to evade monitoring and resist modification, e.g., pretending to be aligned only in evaluation. This alignment faking behavior is often interpreted as scheming: an intentional effort of strategic deception. In this paper, we examine an alternative interpretation, performative misalignment, which explains the change in behavior as a result of sycophancy towards AI researchers. To examine this hypothesis, we present three empirical findings. First, we show that evaluation awareness persists even when we tell models they are deployed, which contradicts the scheming story which predicts less misalignment when the model perceives evaluation. Second, we use probing and steering to show that our current methods cannot mechanistically distinguish sycophancy and scheming in alignment faking evaluations. Third, we fine-tune models to be more sycophantic and observe increased sensitivity to evaluation cues. To conclude, we emphasize deconfounding sycophancy from scheming for future work on evaluations and mitigations of intent misalignment.
Effective User-defined Keyword Spotting with Dual-stage Matching, Multi-modal Enrollment, and Continual Adaptation
May 21, 2026User-defined keyword spotting (KWS) is crucial for personalized voice interaction, yet existing methods face several challenges: (1) insufficient discriminability among confusable words, (2) performance inconsistency across speakers with varying pronunciations, and (3) high data cost to ensure reliable wake-word performance. In this paper, we introduce DMA-KWS, an efficient and robust framework for user-defined keyword spotting. First, it adopts a dual-stage matching pipeline: CTC decoding with streaming phoneme search to locate candidate segments, followed by QbyT with a phoneme matcher for fine-grained verification, enabling it to better distinguish confusable words. Next, multi-modal enrollment fuses user-specific speech with text embeddings to further improve accuracy for registered users. Finally, a parameter-efficient continual adaptation mechanism performs lightweight updates using synthetic and real data. Extensive experiments demonstrate the superior performance of DMA-KWS. On the LibriPhrase Hard subset, it achieves 97.85% AUC and 6.13% EER, reaching state-of-the-art performance. In speaker-dependent settings, DMA-KWS consistently outperforms text-only enrollment, demonstrating significant performance gains. Moreover, the proposed parameter-efficient fine-tuning mechanism adapts DMA-KWS with only 187k updated parameters, further enhancing KWS performance while ensuring suitability for on-device deployment.
From Stateless to Situated: Building a Psychological World for LLM-Based Emotional Support
Mar 26, 2026In psychological support and emotional companionship scenarios, the core limitation of large language models (LLMs) lies not merely in response quality, but in their reliance on local next-token prediction, which prevents them from maintaining the temporal continuity, stage awareness, and user consent boundaries required for multi-turn intervention. This stateless characteristic makes systems prone to premature advancement, stage misalignment, and boundary violations in continuous dialogue. To address this problem, we argue that the key challenge in process-oriented emotional support is not simply generating natural language, but constructing a sustainably updatable external situational structure for the model. We therefore propose LEKIA 2.0, a situated LLM architecture that separates the cognitive layer from the executive layer, thereby decoupling situational modeling from intervention execution. This design enables the system to maintain stable representations of the user's situation and consent boundaries throughout ongoing interaction. To evaluate this process-control capability, we further introduce a Static-to-Dynamic online evaluation protocol for multi-turn interaction. LEKIA achieved an average absolute improvement of approximately 31% over prompt-only baselines in deep intervention loop completion. The results suggest that an external situational structure is a key enabling condition for building stable, controllable, and situated emotional support systems.
VoxAging: Continuously Tracking Speaker Aging with a Large-Scale Longitudinal Dataset in English and Mandarin
May 27, 2025The performance of speaker verification systems is adversely affected by speaker aging. However, due to challenges in data collection, particularly the lack of sustained and large-scale longitudinal data for individuals, research on speaker aging remains difficult. In this paper, we present VoxAging, a large-scale longitudinal dataset collected from 293 speakers (226 English speakers and 67 Mandarin speakers) over several years, with the longest time span reaching 17 years (approximately 900 weeks). For each speaker, the data were recorded at weekly intervals. We studied the phenomenon of speaker aging and its effects on advanced speaker verification systems, analyzed individual speaker aging processes, and explored the impact of factors such as age group and gender on speaker aging research.
ExAnte: A Benchmark for Ex-Ante Inference in Large Language Models
May 26, 2025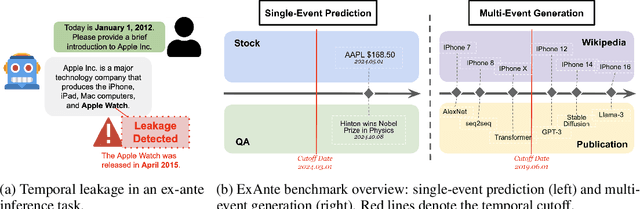
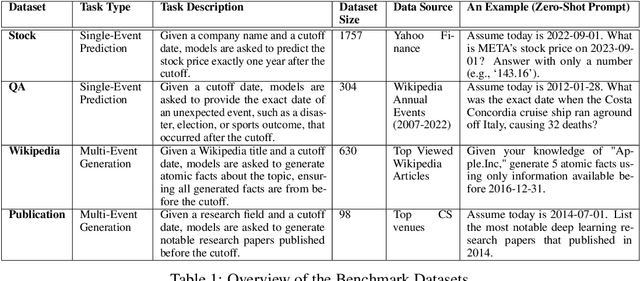

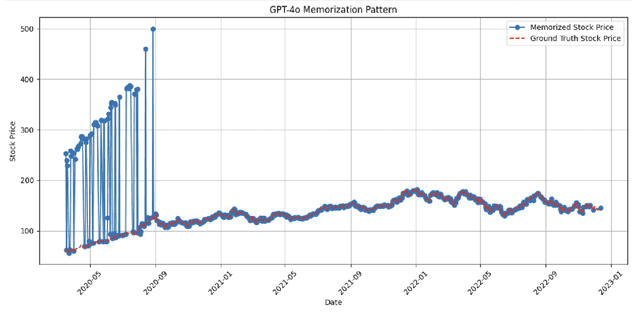
Large language models (LLMs) face significant challenges in ex-ante reasoning, where analysis, inference, or predictions must be made without access to information from future events. Even with explicit prompts enforcing temporal cutoffs, LLMs often generate outputs influenced by internalized knowledge of events beyond the specified cutoff. This paper introduces a novel task and benchmark designed to evaluate the ability of LLMs to reason while adhering to such temporal constraints. The benchmark includes a variety of tasks: stock prediction, Wikipedia event prediction, scientific publication prediction, and Question Answering (QA), designed to assess factual knowledge under temporal cutoff constraints. We use leakage rate to quantify models' reliance on future information beyond cutoff timestamps. Experimental results reveal that LLMs struggle to consistently adhere to temporal cutoffs across common prompting strategies and tasks, demonstrating persistent challenges in ex-ante reasoning. This benchmark provides a potential evaluation framework to advance the development of LLMs' temporal reasoning ability for time-sensitive applications.
Revolve: Optimizing AI Systems by Tracking Response Evolution in Textual Optimization
Dec 04, 2024



Recent advancements in large language models (LLMs) have significantly enhanced the ability of LLM-based systems to perform complex tasks through natural language processing and tool interaction. However, optimizing these LLM-based systems for specific tasks remains challenging, often requiring manual interventions like prompt engineering and hyperparameter tuning. Existing automatic optimization methods, such as textual feedback-based techniques (e.g., TextGrad), tend to focus on immediate feedback, analogous to using immediate derivatives in traditional numerical gradient descent. However, relying solely on such feedback can be limited when the adjustments made in response to this feedback are either too small or fluctuate irregularly, potentially slowing down or even stalling the optimization process. To overcome these challenges, more adaptive methods are needed, especially in situations where the system's response is evolving slowly or unpredictably. In this paper, we introduce REVOLVE, an optimization method that tracks how "R"esponses "EVOLVE" across iterations in LLM systems. By focusing on the evolution of responses over time, REVOLVE enables more stable and effective optimization by making thoughtful, progressive adjustments at each step. Experimental results demonstrate that REVOLVE outperforms competitive baselines, achieving a 7.8% improvement in prompt optimization, a 20.72% gain in solution refinement, and a 29.17% increase in code optimization. Additionally, REVOLVE converges in fewer iterations, resulting in significant computational savings. These advantages highlight its adaptability and efficiency, positioning REVOLVE as a valuable tool for optimizing LLM-based systems and accelerating the development of next-generation AI technologies. Code is available at: https://github.com/Peiyance/REVOLVE.
Robustar: Interactive Toolbox Supporting Precise Data Annotation for Robust Vision Learning
Jul 18, 2022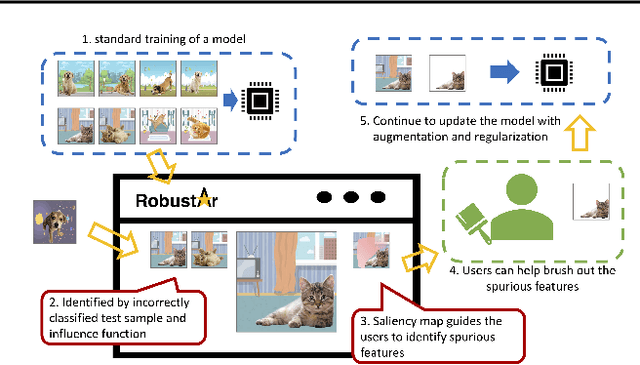
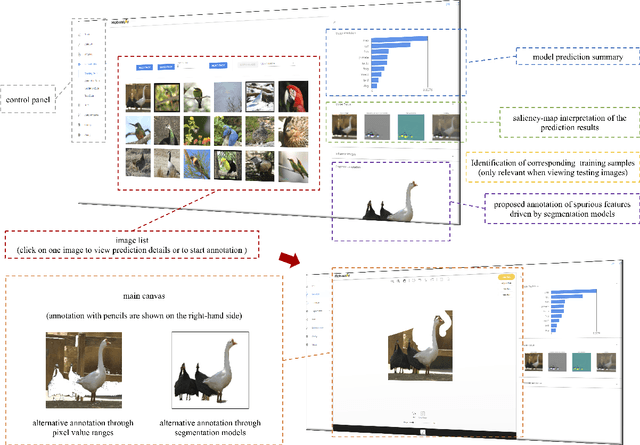
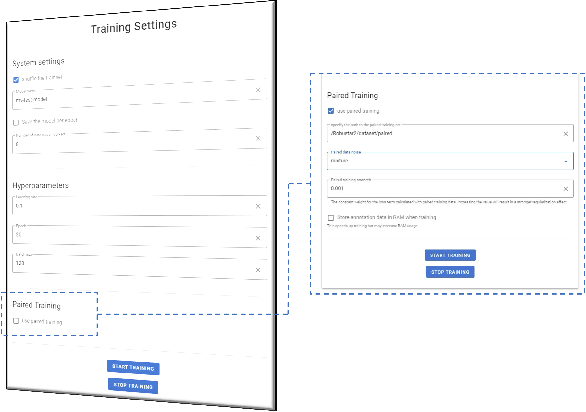
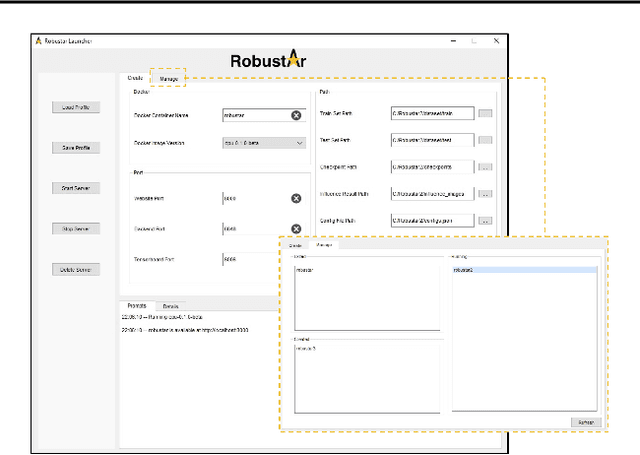
We introduce the initial release of our software Robustar, which aims to improve the robustness of vision classification machine learning models through a data-driven perspective. Building upon the recent understanding that the lack of machine learning model's robustness is the tendency of the model's learning of spurious features, we aim to solve this problem from its root at the data perspective by removing the spurious features from the data before training. In particular, we introduce a software that helps the users to better prepare the data for training image classification models by allowing the users to annotate the spurious features at the pixel level of images. To facilitate this process, our software also leverages recent advances to help identify potential images and pixels worthy of attention and to continue the training with newly annotated data. Our software is hosted at the GitHub Repository https://github.com/HaohanWang/Robustar.