 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReusStdFlow: A Standardized Reusability Framework for Dynamic Workflow Construction in Agentic AI
Feb 16, 2026To address the ``reusability dilemma'' and structural hallucinations in enterprise Agentic AI,this paper proposes ReusStdFlow, a framework centered on a novel ``Extraction-Storage-Construction'' paradigm. The framework deconstructs heterogeneous, platform-specific Domain Specific Languages (DSLs) into standardized, modular workflow segments. It employs a dual knowledge architecture-integrating graph and vector databases-to facilitate synergistic retrieval of both topological structures and functional semantics. Finally, workflows are intelligently assembled using a retrieval-augmented generation (RAG) strategy. Tested on 200 real-world n8n workflows, the system achieves over 90% accuracy in both extraction and construction. This framework provides a standardized solution for the automated reorganization and efficient reuse of enterprise digital assets.
Fault2Flow: An AlphaEvolve-Optimized Human-in-the-Loop Multi-Agent System for Fault-to-Workflow Automation
Nov 17, 2025Power grid fault diagnosis is a critical process hindered by its reliance on manual, error-prone methods. Technicians must manually extract reasoning logic from dense regulations and attempt to combine it with tacit expert knowledge, which is inefficient, error-prone, and lacks maintainability as ragulations are updated and experience evolves. While Large Language Models (LLMs) have shown promise in parsing unstructured text, no existing framework integrates these two disparate knowledge sources into a single, verified, and executable workflow. To bridge this gap, we propose Fault2Flow, an LLM-based multi-agent system. Fault2Flow systematically: (1) extracts and structures regulatory logic into PASTA-formatted fault trees; (2) integrates expert knowledge via a human-in-the-loop interface for verification; (3) optimizes the reasoning logic using a novel AlphaEvolve module; and (4) synthesizes the final, verified logic into an n8n-executable workflow. Experimental validation on transformer fault diagnosis datasets confirms 100\% topological consistency and high semantic fidelity. Fault2Flow establishes a reproducible path from fault analysis to operational automation, substantially reducing expert workload.
IntentDial: An Intent Graph based Multi-Turn Dialogue System with Reasoning Path Visualization
Oct 18, 2023



Intent detection and identification from multi-turn dialogue has become a widely explored technique in conversational agents, for example, voice assistants and intelligent customer services. The conventional approaches typically cast the intent mining process as a classification task. Although neural classifiers have proven adept at such classification tasks, the issue of neural network models often impedes their practical deployment in real-world settings. We present a novel graph-based multi-turn dialogue system called , which identifies a user's intent by identifying intent elements and a standard query from a dynamically constructed and extensible intent graph using reinforcement learning. In addition, we provide visualization components to monitor the immediate reasoning path for each turn of a dialogue, which greatly facilitates further improvement of the system.
R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Modeling
Jul 02, 2021
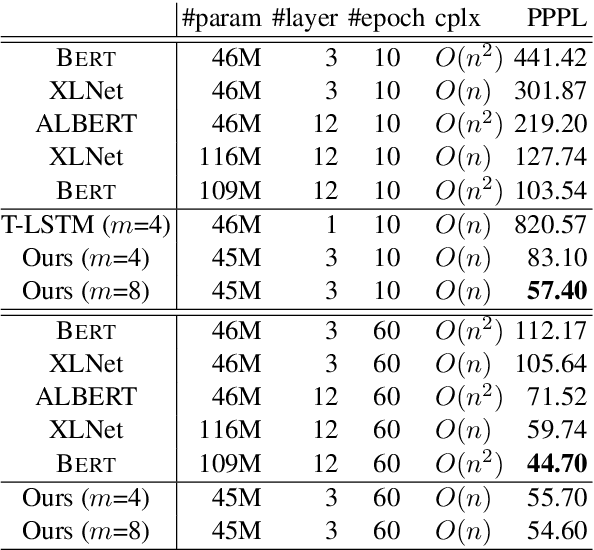
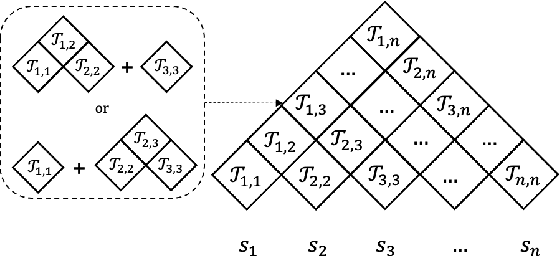
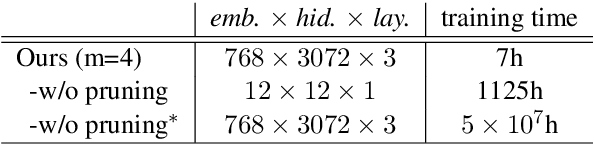
Human language understanding operates at multiple levels of granularity (e.g., words, phrases, and sentences) with increasing levels of abstraction that can be hierarchically combined. However, existing deep models with stacked layers do not explicitly model any sort of hierarchical process. This paper proposes a recursive Transformer model based on differentiable CKY style binary trees to emulate the composition process. We extend the bidirectional language model pre-training objective to this architecture, attempting to predict each word given its left and right abstraction nodes. To scale up our approach, we also introduce an efficient pruned tree induction algorithm to enable encoding in just a linear number of composition steps. Experimental results on language modeling and unsupervised parsing show the effectiveness of our approach.
Interactive Question Clarification in Dialogue via Reinforcement Learning
Dec 17, 2020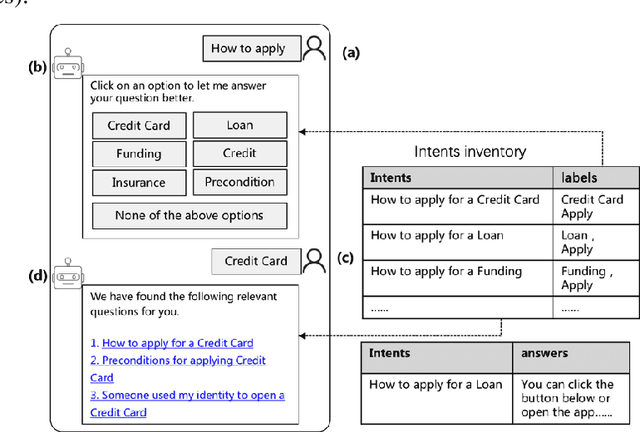

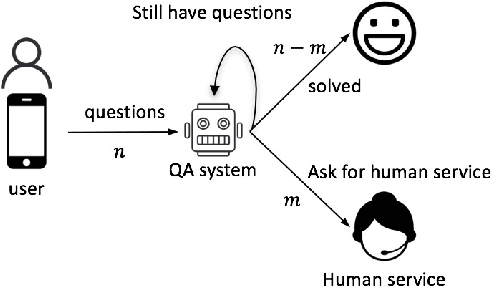
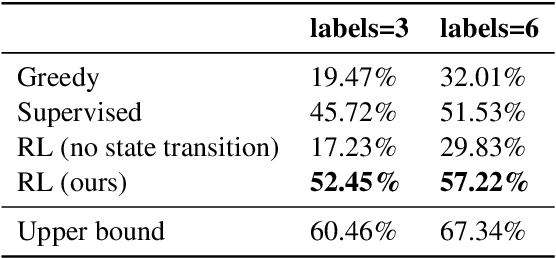
Coping with ambiguous questions has been a perennial problem in real-world dialogue systems. Although clarification by asking questions is a common form of human interaction, it is hard to define appropriate questions to elicit more specific intents from a user. In this work, we propose a reinforcement model to clarify ambiguous questions by suggesting refinements of the original query. We first formulate a collection partitioning problem to select a set of labels enabling us to distinguish potential unambiguous intents. We list the chosen labels as intent phrases to the user for further confirmation. The selected label along with the original user query then serves as a refined query, for which a suitable response can more easily be identified. The model is trained using reinforcement learning with a deep policy network. We evaluate our model based on real-world user clicks and demonstrate significant improvements across several different experiments.
DAN: Dual-View Representation Learning for Adapting Stance Classifiers to New Domains
Mar 13, 2020
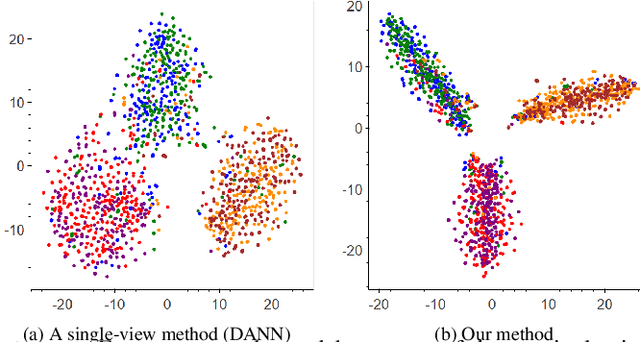
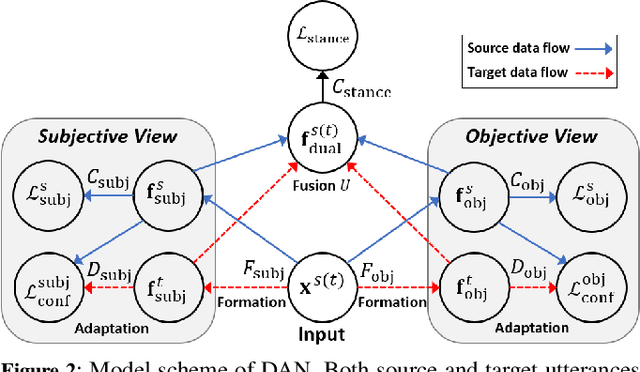
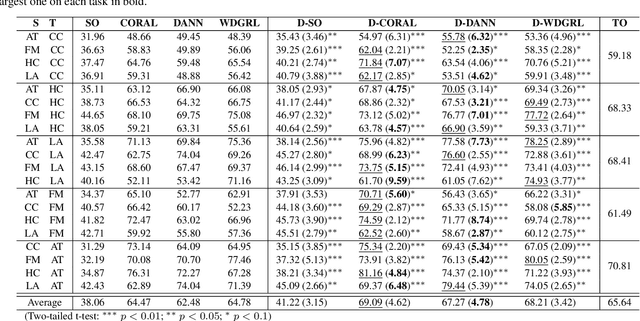
We address the issue of having a limited number of annotations for stance classification in a new domain, by adapting out-of-domain classifiers with domain adaptation. Existing approaches often align different domains in a single, global feature space (or view), which may fail to fully capture the richness of the languages used for expressing stances, leading to reduced adaptability on stance data. In this paper, we identify two major types of stance expressions that are linguistically distinct, and we propose a tailored dual-view adaptation network (DAN) to adapt these expressions across domains. The proposed model first learns a separate view for domain transfer in each expression channel and then selects the best adapted parts of both views for optimal transfer. We find that the learned view features can be more easily aligned and more stance-discriminative in either or both views, leading to more transferable overall features after combining the views. Results from extensive experiments show that our method can enhance the state-of-the-art single-view methods in matching stance data across different domains, and that it consistently improves those methods on various adaptation tasks.
Long Short-Term Sample Distillation
Mar 02, 2020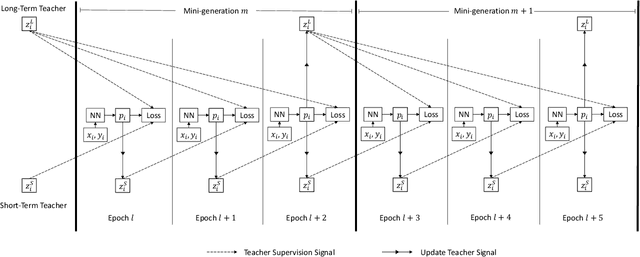
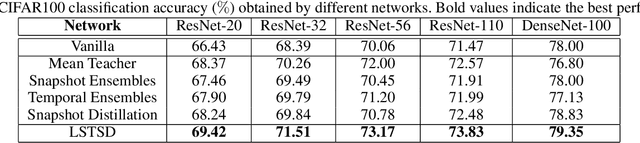
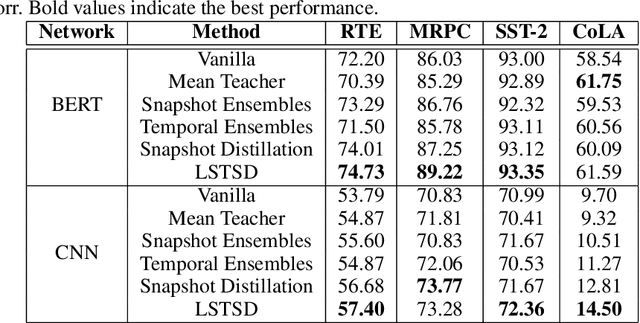
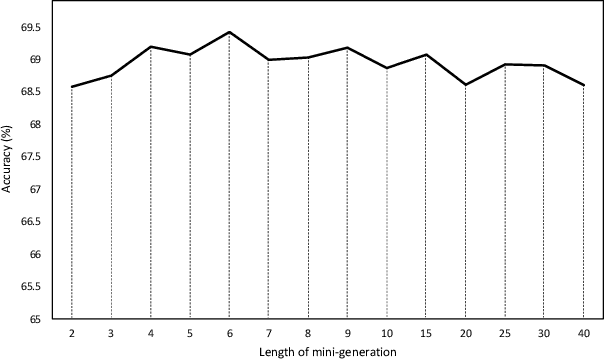
In the past decade, there has been substantial progress at training increasingly deep neural networks. Recent advances within the teacher--student training paradigm have established that information about past training updates show promise as a source of guidance during subsequent training steps. Based on this notion, in this paper, we propose Long Short-Term Sample Distillation, a novel training policy that simultaneously leverages multiple phases of the previous training process to guide the later training updates to a neural network, while efficiently proceeding in just one single generation pass. With Long Short-Term Sample Distillation, the supervision signal for each sample is decomposed into two parts: a long-term signal and a short-term one. The long-term teacher draws on snapshots from several epochs ago in order to provide steadfast guidance and to guarantee teacher--student differences, while the short-term one yields more up-to-date cues with the goal of enabling higher-quality updates. Moreover, the teachers for each sample are unique, such that, overall, the model learns from a very diverse set of teachers. Comprehensive experimental results across a range of vision and NLP tasks demonstrate the effectiveness of this new training method.
Which Channel to Ask My Question? Personalized Customer Service RequestStream Routing using DeepReinforcement Learning
Nov 24, 2019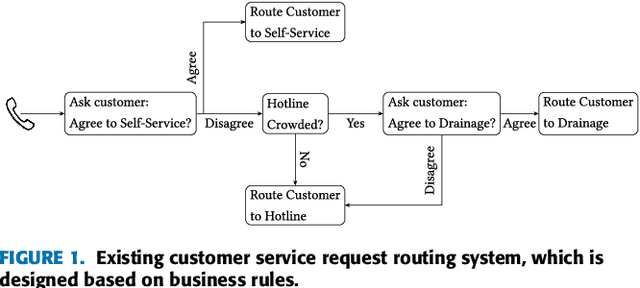
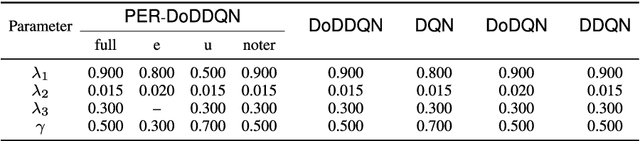
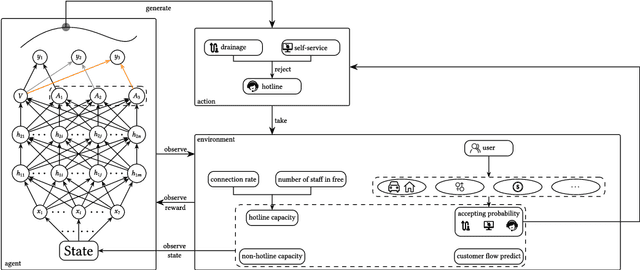
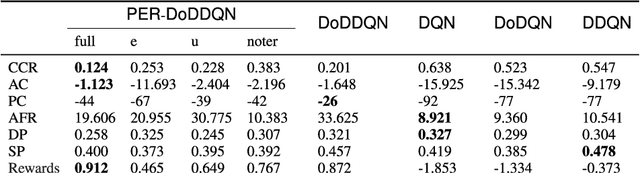
Customer services are critical to all companies, as they may directly connect to the brand reputation. Due to a great number of customers, e-commerce companies often employ multiple communication channels to answer customers' questions, for example, chatbot and hotline. On one hand, each channel has limited capacity to respond to customers' requests, on the other hand, customers have different preferences over these channels. The current production systems are mainly built based on business rules, which merely considers tradeoffs between resources and customers' satisfaction. To achieve the optimal tradeoff between resources and customers' satisfaction, we propose a new framework based on deep reinforcement learning, which directly takes both resources and user model into account. In addition to the framework, we also propose a new deep-reinforcement-learning based routing method-double dueling deep Q-learning with prioritized experience replay (PER-DoDDQN). We evaluate our proposed framework and method using both synthetic and a real customer service log data from a large financial technology company. We show that our proposed deep-reinforcement-learning based framework is superior to the existing production system. Moreover, we also show our proposed PER-DoDDQN is better than all other deep Q-learning variants in practice, which provides a more optimal routing plan. These observations suggest that our proposed method can seek the trade-off where both channel resources and customers' satisfaction are optimal.