 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Xiao
Deep Lesion Tracker: Monitoring Lesions in 4D Longitudinal Imaging Studies
Dec 09, 2020
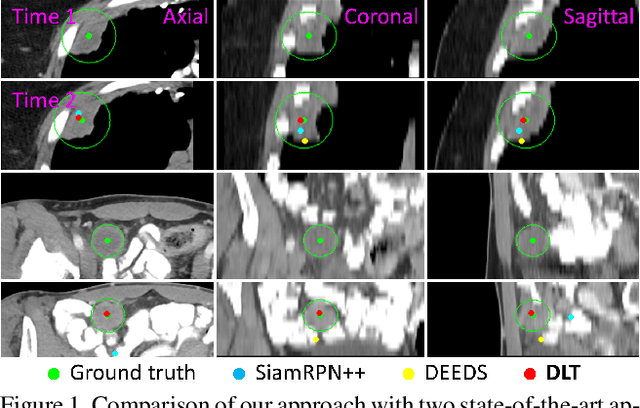
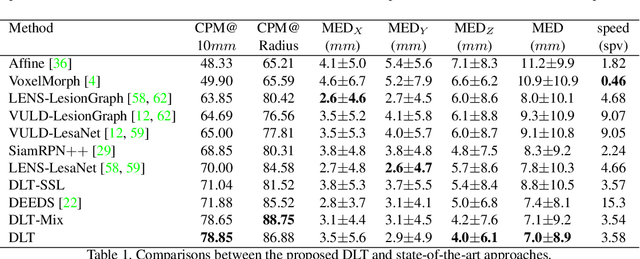
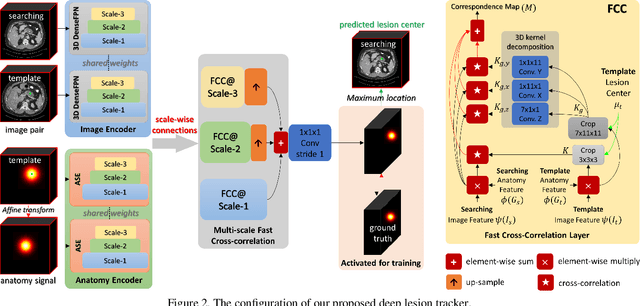
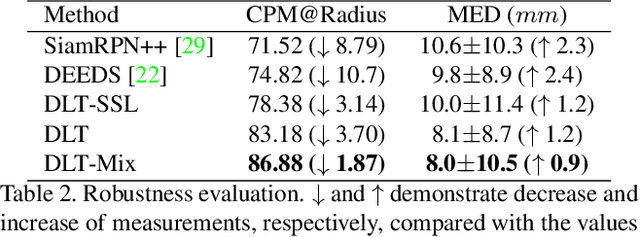
Monitoring treatment response in longitudinal studies plays an important role in clinical practice. Accurately identifying lesions across serial imaging follow-up is the core to the monitoring procedure. Typically this incorporates both image and anatomical considerations. However, matching lesions manually is labor-intensive and time-consuming. In this work, we present deep lesion tracker (DLT), a deep learning approach that uses both appearance- and anatomical-based signals. To incorporate anatomical constraints, we propose an anatomical signal encoder, which prevents lesions being matched with visually similar but spurious regions. In addition, we present a new formulation for Siamese networks that avoids the heavy computational loads of 3D cross-correlation. To present our network with greater varieties of images, we also propose a self-supervised learning (SSL) strategy to train trackers with unpaired images, overcoming barriers to data collection. To train and evaluate our tracker, we introduce and release the first lesion tracking benchmark, consisting of 3891 lesion pairs from the public DeepLesion database. The proposed method, DLT, locates lesion centers with a mean error distance of 7 mm. This is 5% better than a leading registration algorithm while running 14 times faster on whole CT volumes. We demonstrate even greater improvements over detector or similarity-learning alternatives. DLT also generalizes well on an external clinical test set of 100 longitudinal studies, achieving 88% accuracy. Finally, we plug DLT into an automatic tumor monitoring workflow where it leads to an accuracy of 85% in assessing lesion treatment responses, which is only 0.46% lower than the accuracy of manual inputs.
3D Graph Anatomy Geometry-Integrated Network for Pancreatic Mass Segmentation, Diagnosis, and Quantitative Patient Management
Dec 08, 2020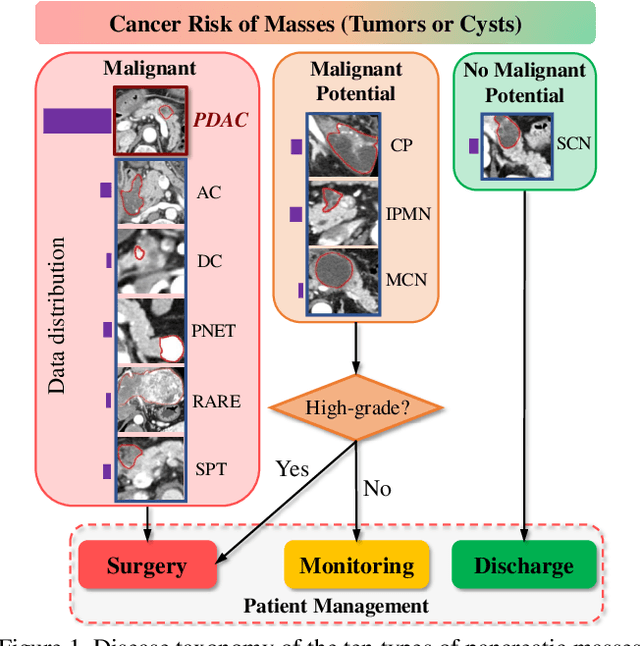

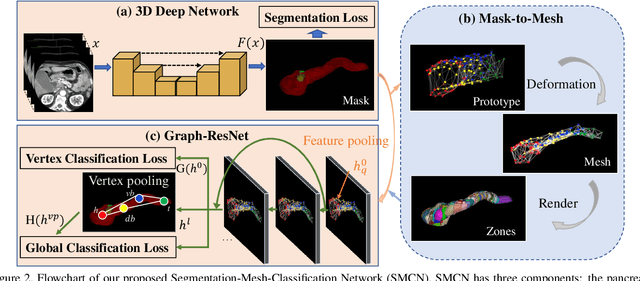

The pancreatic disease taxonomy includes ten types of masses (tumors or cysts)[20,8]. Previous work focuses on developing segmentation or classification methods only for certain mass types. Differential diagnosis of all mass types is clinically highly desirable [20] but has not been investigated using an automated image understanding approach. We exploit the feasibility to distinguish pancreatic ductal adenocarcinoma (PDAC) from the nine other nonPDAC masses using multi-phase CT imaging. Both image appearance and the 3D organ-mass geometry relationship are critical. We propose a holistic segmentation-mesh-classification network (SMCN) to provide patient-level diagnosis, by fully utilizing the geometry and location information, which is accomplished by combining the anatomical structure and the semantic detection-by-segmentation network. SMCN learns the pancreas and mass segmentation task and builds an anatomical correspondence-aware organ mesh model by progressively deforming a pancreas prototype on the raw segmentation mask (i.e., mask-to-mesh). A new graph-based residual convolutional network (Graph-ResNet), whose nodes fuse the information of the mesh model and feature vectors extracted from the segmentation network, is developed to produce the patient-level differential classification results. Extensive experiments on 661 patients' CT scans (five phases per patient) show that SMCN can improve the mass segmentation and detection accuracy compared to the strong baseline method nnUNet (e.g., for nonPDAC, Dice: 0.611 vs. 0.478; detection rate: 89% vs. 70%), achieve similar sensitivity and specificity in differentiating PDAC and nonPDAC as expert radiologists (i.e., 94% and 90%), and obtain results comparable to a multimodality test [20] that combines clinical, imaging, and molecular testing for clinical management of patients.
A New Window Loss Function for Bone Fracture Detection and Localization in X-ray Images with Point-based Annotation
Dec 07, 2020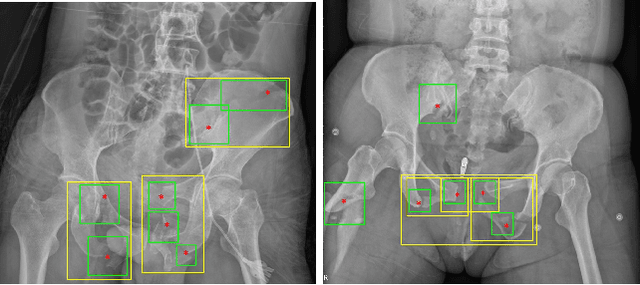
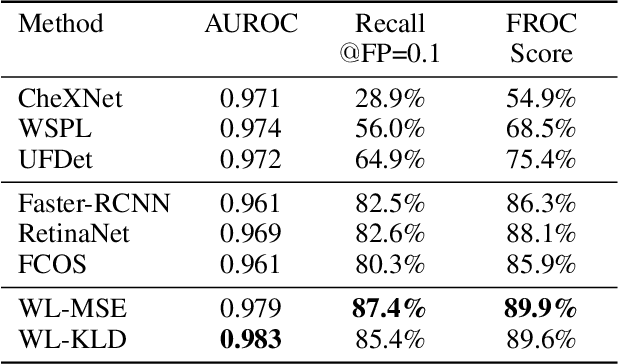
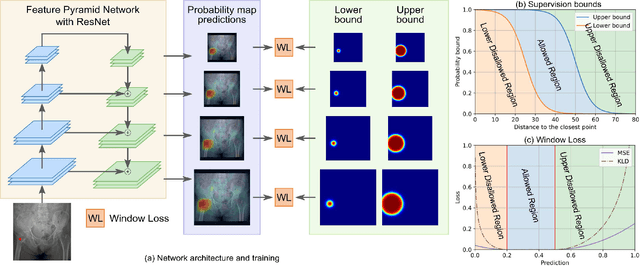
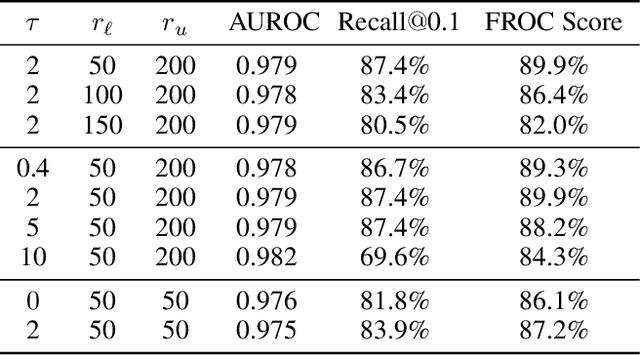
Object detection methods are widely adopted for computer-aided diagnosis using medical images. Anomalous findings are usually treated as objects that are described by bounding boxes. Yet, many pathological findings, e.g., bone fractures, cannot be clearly defined by bounding boxes, owing to considerable instance, shape and boundary ambiguities. This makes bounding box annotations, and their associated losses, highly ill-suited. In this work, we propose a new bone fracture detection method for X-ray images, based on a labor effective and flexible annotation scheme suitable for abnormal findings with no clear object-level spatial extents or boundaries. Our method employs a simple, intuitive, and informative point-based annotation protocol to mark localized pathology information. To address the uncertainty in the fracture scales annotated via point(s), we convert the annotations into pixel-wise supervision that uses lower and upper bounds with positive, negative, and uncertain regions. A novel Window Loss is subsequently proposed to only penalize the predictions outside of the uncertain regions. Our method has been extensively evaluated on 4410 pelvic X-ray images of unique patients. Experiments demonstrate that our method outperforms previous state-of-the-art image classification and object detection baselines by healthy margins, with an AUROC of 0.983 and FROC score of 89.6%.
Self-supervised Learning of Pixel-wise Anatomical Embeddings in Radiological Images
Dec 04, 2020
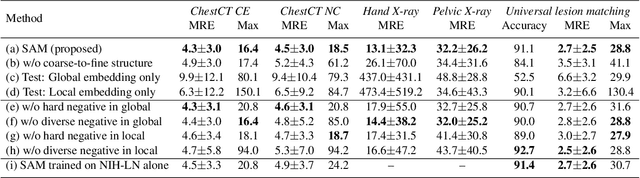
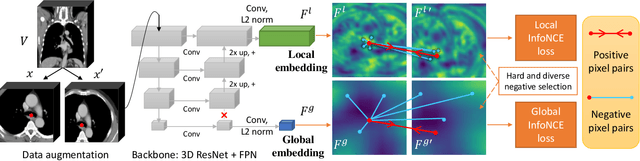
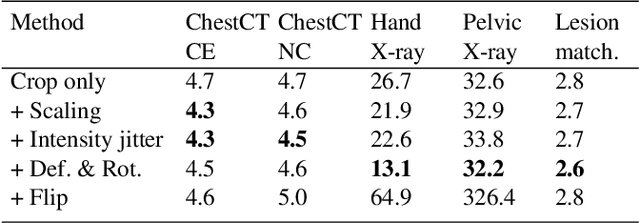
Radiological images such as computed tomography (CT) and X-rays render anatomy with intrinsic structures. Being able to reliably locate the same anatomical or semantic structure across varying images is a fundamental task in medical image analysis. In principle it is possible to use landmark detection or semantic segmentation for this task, but to work well these require large numbers of labeled data for each anatomical structure and sub-structure of interest. A more universal approach would discover the intrinsic structure from unlabeled images. We introduce such an approach, called Self-supervised Anatomical eMbedding (SAM). SAM generates semantic embeddings for each image pixel that describes its anatomical location or body part. To produce such embeddings, we propose a pixel-level contrastive learning framework. A coarse-to-fine strategy ensures both global and local anatomical information are encoded. Negative sample selection strategies are designed to enhance the discriminability among different body parts. Using SAM, one can label any point of interest on a template image, and then locate the same body part in other images by simple nearest neighbor searching. We demonstrate the effectiveness of SAM in multiple tasks with 2D and 3D image modalities. On a chest CT dataset with 19 landmarks, SAM outperforms widely-used registration algorithms while being 200 times faster. On two X-ray datasets, SAM, with only one labeled template image, outperforms supervised methods trained on 50 labeled images. We also apply SAM on whole-body follow-up lesion matching in CT and obtain an accuracy of 91%.
MelGlow: Efficient Waveform Generative Network Based on Location-Variable Convolution
Dec 03, 2020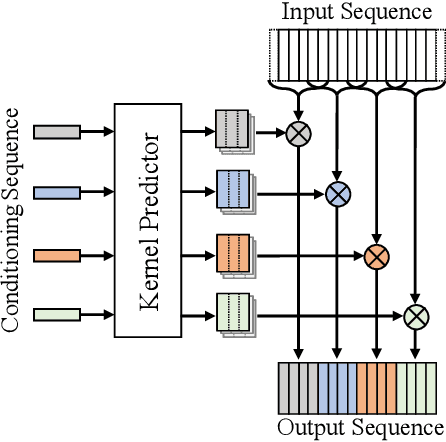
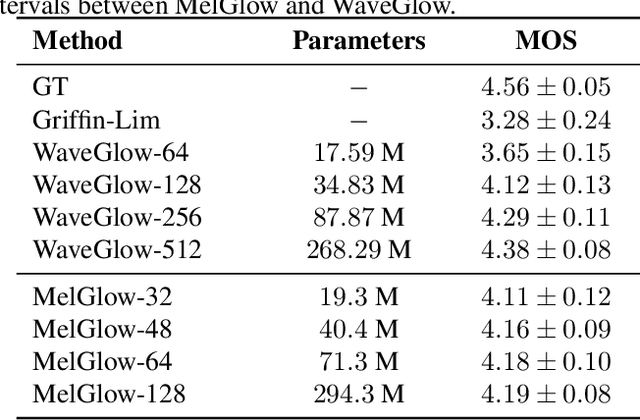
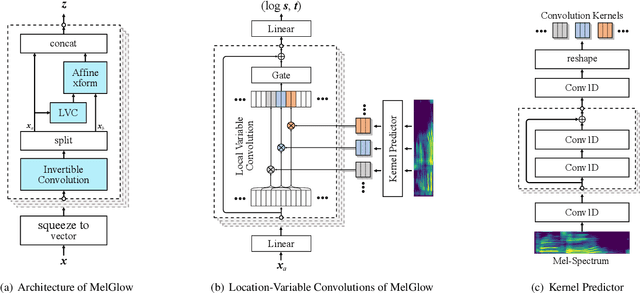
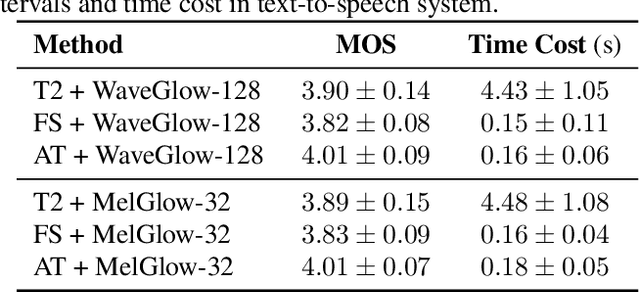
Recent neural vocoders usually use a WaveNet-like network to capture the long-term dependencies of the waveform, but a large number of parameters are required to obtain good modeling capabilities. In this paper, an efficient network, named location-variable convolution, is proposed to model the dependencies of waveforms. Different from the use of unified convolution kernels in WaveNet to capture the dependencies of arbitrary waveforms, location-variable convolutions utilizes a kernel predictor to generate multiple sets of convolution kernels based on the mel-spectrum, where each set of convolution kernels is used to perform convolution operations on the associated waveform intervals. Combining WaveGlow and location-variable convolutions, an efficient vocoder, named MelGlow, is designed. Experiments on the LJSpeech dataset show that MelGlow achieves better performance than WaveGlow at small model sizes, which verifies the effectiveness and potential optimization space of location-variable convolutions.
GraphPB: Graphical Representations of Prosody Boundary in Speech Synthesis
Dec 03, 2020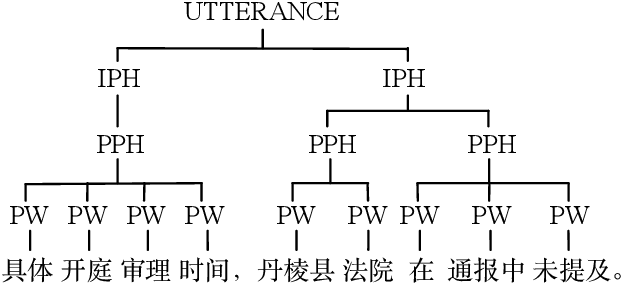

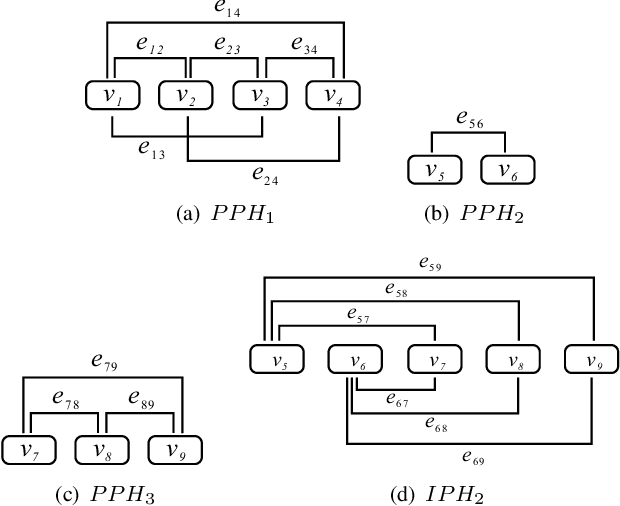

This paper introduces a graphical representation approach of prosody boundary (GraphPB) in the task of Chinese speech synthesis, intending to parse the semantic and syntactic relationship of input sequences in a graphical domain for improving the prosody performance. The nodes of the graph embedding are formed by prosodic words, and the edges are formed by the other prosodic boundaries, namely prosodic phrase boundary (PPH) and intonation phrase boundary (IPH). Different Graph Neural Networks (GNN) like Gated Graph Neural Network (GGNN) and Graph Long Short-term Memory (G-LSTM) are utilised as graph encoders to exploit the graphical prosody boundary information. Graph-to-sequence model is proposed and formed by a graph encoder and an attentional decoder. Two techniques are proposed to embed sequential information into the graph-to-sequence text-to-speech model. The experimental results show that this proposed approach can encode the phonetic and prosody rhythm of an utterance. The mean opinion score (MOS) of these GNN models shows comparative results with the state-of-the-art sequence-to-sequence models with better performance in the aspect of prosody. This provides an alternative approach for prosody modelling in end-to-end speech synthesis.
Contour Transformer Network for One-shot Segmentation of Anatomical Structures
Dec 02, 2020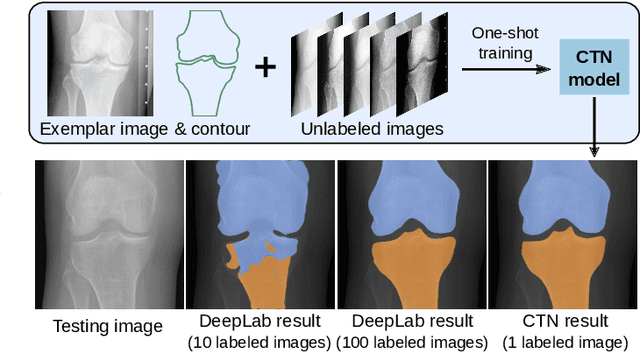
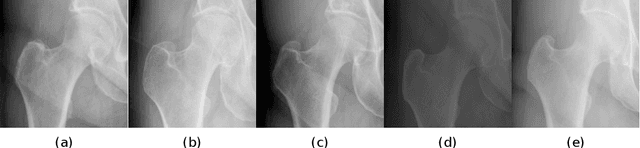
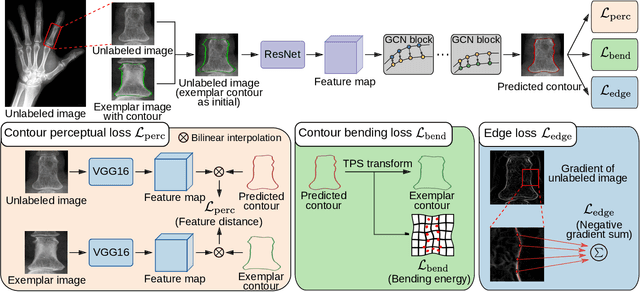
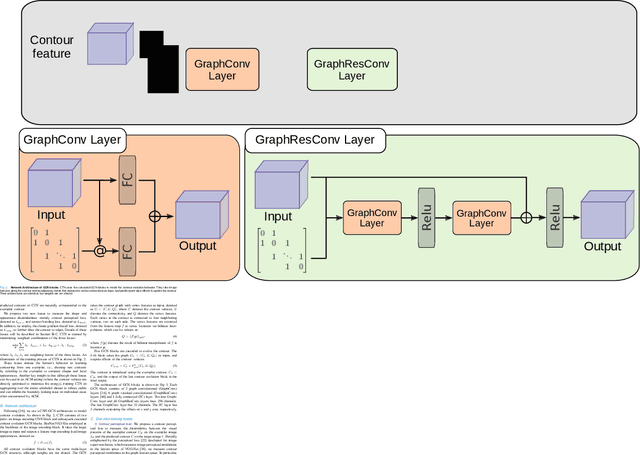
Accurate segmentation of anatomical structures is vital for medical image analysis. The state-of-the-art accuracy is typically achieved by supervised learning methods, where gathering the requisite expert-labeled image annotations in a scalable manner remains a main obstacle. Therefore, annotation-efficient methods that permit to produce accurate anatomical structure segmentation are highly desirable. In this work, we present Contour Transformer Network (CTN), a one-shot anatomy segmentation method with a naturally built-in human-in-the-loop mechanism. We formulate anatomy segmentation as a contour evolution process and model the evolution behavior by graph convolutional networks (GCNs). Training the CTN model requires only one labeled image exemplar and leverages additional unlabeled data through newly introduced loss functions that measure the global shape and appearance consistency of contours. On segmentation tasks of four different anatomies, we demonstrate that our one-shot learning method significantly outperforms non-learning-based methods and performs competitively to the state-of-the-art fully supervised deep learning methods. With minimal human-in-the-loop editing feedback, the segmentation performance can be further improved to surpass the fully supervised methods.
Semantic SLAM with Autonomous Object-Level Data Association
Nov 20, 2020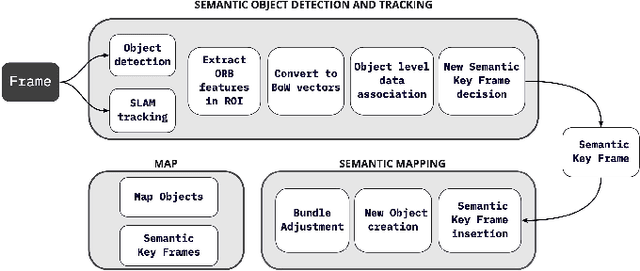



It is often desirable to capture and map semantic information of an environment during simultaneous localization and mapping (SLAM). Such semantic information can enable a robot to better distinguish places with similar low-level geometric and visual features and perform high-level tasks that use semantic information about objects to be manipulated and environments to be navigated. While semantic SLAM has gained increasing attention, there is little research on semanticlevel data association based on semantic objects, i.e., object-level data association. In this paper, we propose a novel object-level data association algorithm based on bag of words algorithm, formulated as a maximum weighted bipartite matching problem. With object-level data association solved, we develop a quadratic-programming-based semantic object initialization scheme using dual quadric and introduce additional constraints to improve the success rate of object initialization. The integrated semantic-level SLAM system can achieve high-accuracy object-level data association and real-time semantic mapping as demonstrated in the experiments. The online semantic map building and semantic-level localization capabilities facilitate semantic-level mapping and task planning in a priori unknown environment.
CASS-NAT: CTC Alignment-based Single Step Non-autoregressive Transformer for Speech Recognition
Oct 28, 2020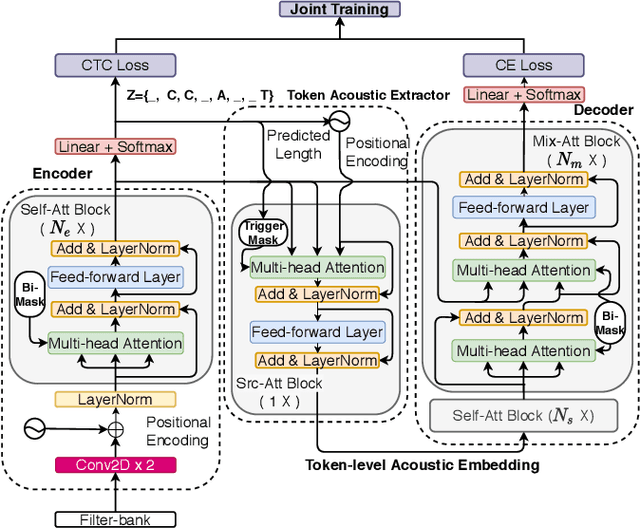
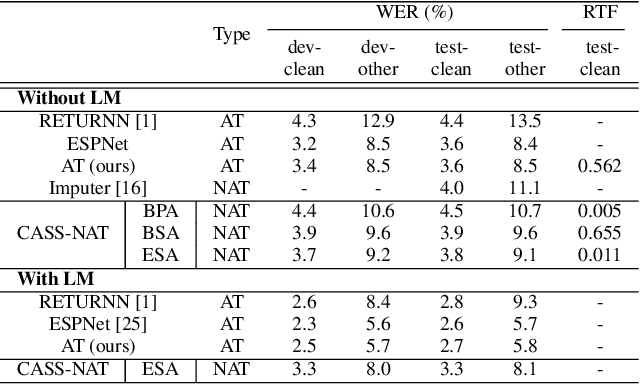


We propose a CTC alignment-based single step non-autoregressive transformer (CASS-NAT) for speech recognition. Specifically, the CTC alignment contains the information of (a) the number of tokens for decoder input, and (b) the time span of acoustics for each token. The information are used to extract acoustic representation for each token in parallel, referred to as token-level acoustic embedding which substitutes the word embedding in autoregressive transformer (AT) to achieve parallel generation in decoder. During inference, an error-based alignment sampling method is proposed to be applied to the CTC output space, reducing the WER and retaining the parallelism as well. Experimental results show that the proposed method achieves WERs of 3.8%/9.1% on Librispeech test clean/other dataset without an external LM, and a CER of 5.8% on Aishell1 Mandarin corpus, respectively1. Compared to the AT baseline, the CASS-NAT has a performance reduction on WER, but is 51.2x faster in terms of RTF. When decoding with an oracle CTC alignment, the lower bound of WER without LM reaches 2.3% on the test-clean set, indicating the potential of the proposed method.
Residual Recurrent CRNN for End-to-End Optical Music Recognition on Monophonic Scores
Oct 26, 2020
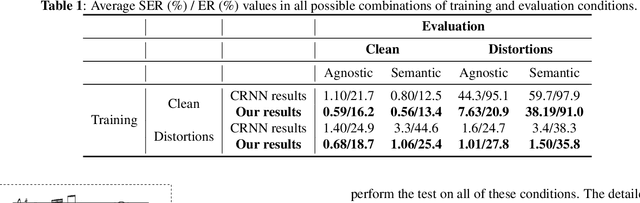

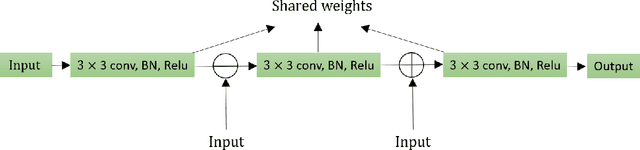
Optical Music Recognition is a field that attempts to extract digital information from images of either the printed music scores or the handwritten music scores. One of the challenges of the Optical Music Recognition task is to transcript the symbols of the camera-captured images into digital music notations. Previous end-to-end model, based on deep learning, was developed as a Convolutional Recurrent Neural Network. However, it does not explore sufficient contextual information from full scales and there is still a large room for improvement. In this paper, we propose an innovative end-to-end framework that combines a block of Residual Recurrent Convolutional Neural Network with a recurrent Encoder-Decoder network to map a sequence of monophonic music symbols corresponding to the notations present in the image. The Residual Recurrent Convolutional block can improve the ability of the model to enrich the context information while the number of parameter will not be increasing. The experiment results were benchmarked against a publicly available dataset called CAMERA-PRIMUS. We evaluate the performances of our model on both the images with ideal conditions and that with non-ideal conditions. The experiments show that our approach surpass the state-of-the-art end-to-end method using Convolutional Recurrent Neural Network.