 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphPB: Graphical Representations of Prosody Boundary in Speech Synthesis
Dec 03, 2020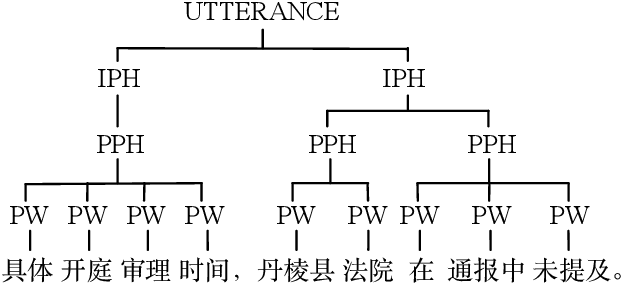

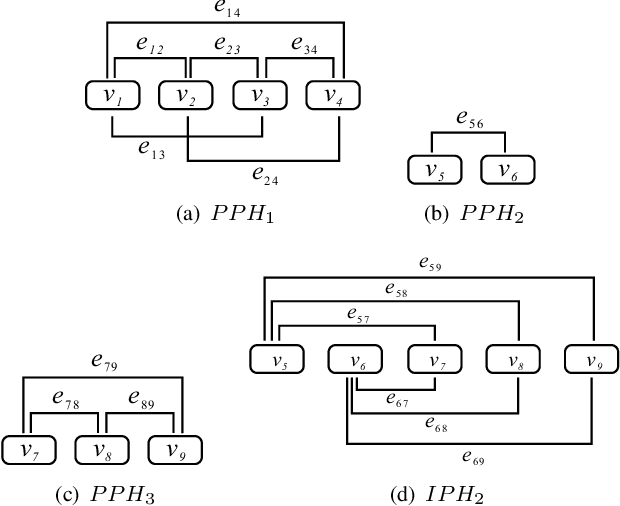

This paper introduces a graphical representation approach of prosody boundary (GraphPB) in the task of Chinese speech synthesis, intending to parse the semantic and syntactic relationship of input sequences in a graphical domain for improving the prosody performance. The nodes of the graph embedding are formed by prosodic words, and the edges are formed by the other prosodic boundaries, namely prosodic phrase boundary (PPH) and intonation phrase boundary (IPH). Different Graph Neural Networks (GNN) like Gated Graph Neural Network (GGNN) and Graph Long Short-term Memory (G-LSTM) are utilised as graph encoders to exploit the graphical prosody boundary information. Graph-to-sequence model is proposed and formed by a graph encoder and an attentional decoder. Two techniques are proposed to embed sequential information into the graph-to-sequence text-to-speech model. The experimental results show that this proposed approach can encode the phonetic and prosody rhythm of an utterance. The mean opinion score (MOS) of these GNN models shows comparative results with the state-of-the-art sequence-to-sequence models with better performance in the aspect of prosody. This provides an alternative approach for prosody modelling in end-to-end speech synthesis.
GraphTTS: graph-to-sequence modelling in neural text-to-speech
Mar 04, 2020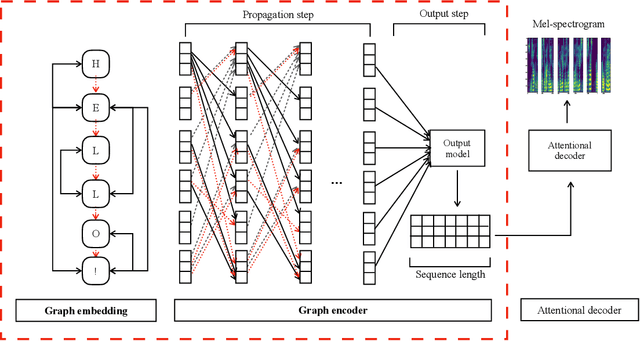

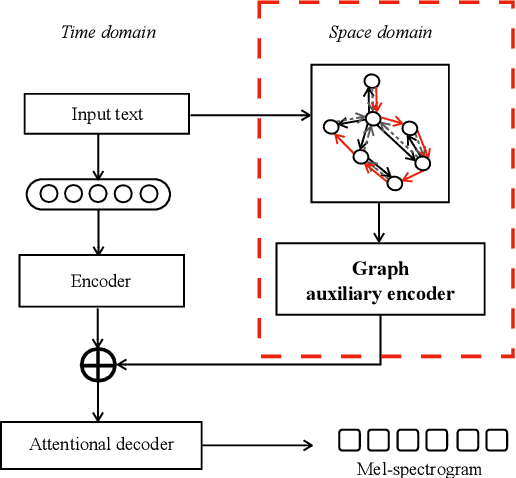
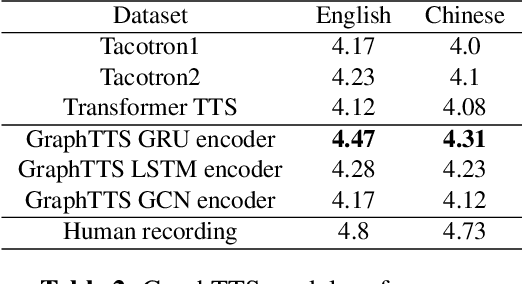
This paper leverages the graph-to-sequence method in neural text-to-speech (GraphTTS), which maps the graph embedding of the input sequence to spectrograms. The graphical inputs consist of node and edge representations constructed from input texts. The encoding of these graphical inputs incorporates syntax information by a GNN encoder module. Besides, applying the encoder of GraphTTS as a graph auxiliary encoder (GAE) can analyse prosody information from the semantic structure of texts. This can remove the manual selection of reference audios process and makes prosody modelling an end-to-end procedure. Experimental analysis shows that GraphTTS outperforms the state-of-the-art sequence-to-sequence models by 0.24 in Mean Opinion Score (MOS). GAE can adjust the pause, ventilation and tones of synthesised audios automatically. This experimental conclusion may give some inspiration to researchers working on improving speech synthesis prosody.