 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Self-Checkout System for Retail Based on Improved YOLOv10
Jul 31, 2024



With the rapid advancement of deep learning technologies, computer vision has shown immense potential in retail automation. This paper presents a novel self-checkout system for retail based on an improved YOLOv10 network, aimed at enhancing checkout efficiency and reducing labor costs. We propose targeted optimizations to the YOLOv10 model, by incorporating the detection head structure from YOLOv8, which significantly improves product recognition accuracy. Additionally, we develop a post-processing algorithm tailored for self-checkout scenarios, to further enhance the application of system. Experimental results demonstrate that our system outperforms existing methods in both product recognition accuracy and checkout speed. This research not only provides a new technical solution for retail automation but offers valuable insights into optimizing deep learning models for real-world applications.
FIARSE: Model-Heterogeneous Federated Learning via Importance-Aware Submodel Extraction
Jul 28, 2024



In federated learning (FL), accommodating clients' varied computational capacities poses a challenge, often limiting the participation of those with constrained resources in global model training. To address this issue, the concept of model heterogeneity through submodel extraction has emerged, offering a tailored solution that aligns the model's complexity with each client's computational capacity. In this work, we propose Federated Importance-Aware Submodel Extraction (FIARSE), a novel approach that dynamically adjusts submodels based on the importance of model parameters, thereby overcoming the limitations of previous static and dynamic submodel extraction methods. Compared to existing works, the proposed method offers a theoretical foundation for the submodel extraction and eliminates the need for additional information beyond the model parameters themselves to determine parameter importance, significantly reducing the overhead on clients. Extensive experiments are conducted on various datasets to showcase superior performance of the proposed FIARSE.
On the Client Preference of LLM Fine-tuning in Federated Learning
Jul 03, 2024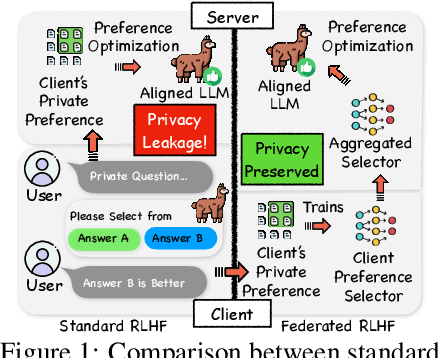
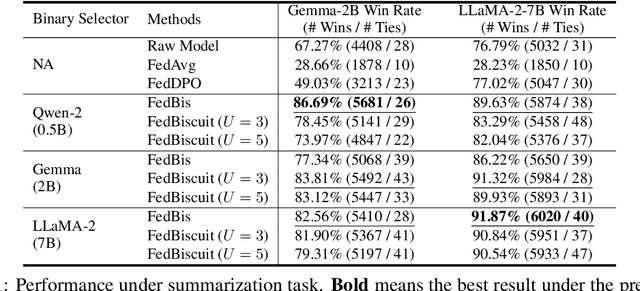
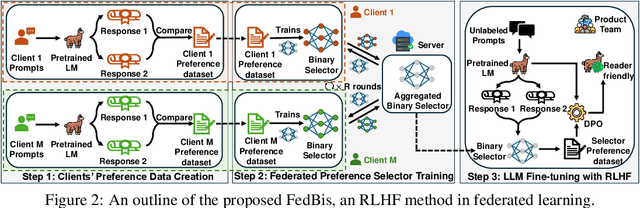
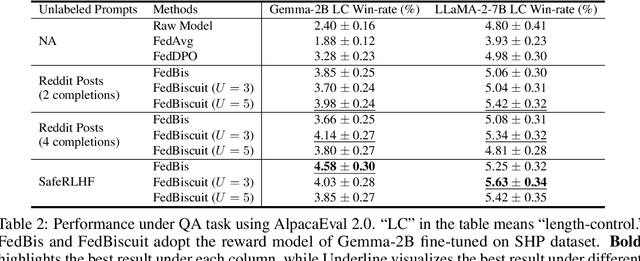
Reinforcement learning with human feedback (RLHF) fine-tunes a pretrained large language model (LLM) using preference datasets, enabling the LLM to generate outputs that align with human preferences. Given the sensitive nature of these preference datasets held by various clients, there is a need to implement RLHF within a federated learning (FL) framework, where clients are reluctant to share their data due to privacy concerns. To address this, we introduce a feasible framework in which clients collaboratively train a binary selector with their preference datasets using our proposed FedBis. With a well-trained selector, we can further enhance the LLM that generates human-preferred completions. Meanwhile, we propose a novel algorithm, FedBiscuit, that trains multiple selectors by organizing clients into balanced and disjoint clusters based on their preferences. Compared to the FedBis, FedBiscuit demonstrates superior performance in simulating human preferences for pairwise completions. Our extensive experiments on federated human preference datasets -- marking the first benchmark to address heterogeneous data partitioning among clients -- demonstrate that FedBiscuit outperforms FedBis and even surpasses traditional centralized training.
FedBiOT: LLM Local Fine-tuning in Federated Learning without Full Model
Jun 25, 2024Large language models (LLMs) show amazing performance on many domain-specific tasks after fine-tuning with some appropriate data. However, many domain-specific data are privately distributed across multiple owners. Thus, this dilemma raises the interest in how to perform LLM fine-tuning in federated learning (FL). However, confronted with limited computation and communication capacities, FL clients struggle to fine-tune an LLM effectively. To this end, we introduce FedBiOT, a resource-efficient LLM fine-tuning approach to FL. Specifically, our method involves the server generating a compressed LLM and aligning its performance with the full model. Subsequently, the clients fine-tune a lightweight yet important part of the compressed model, referred to as an adapter. Notice that as the server has no access to the private data owned by the clients, the data used for alignment by the server has a different distribution from the one used for fine-tuning by clients. We formulate the problem into a bi-level optimization problem to minimize the negative effect of data discrepancy and derive the updating rules for the server and clients. We conduct extensive experiments on LLaMA-2, empirically showing that the adapter has exceptional performance when reintegrated into the global LLM. The results also indicate that the proposed FedBiOT significantly reduces resource consumption compared to existing benchmarks, all while achieving comparable performance levels.
SHIELD: Evaluation and Defense Strategies for Copyright Compliance in LLM Text Generation
Jun 18, 2024



Large Language Models (LLMs) have transformed machine learning but raised significant legal concerns due to their potential to produce text that infringes on copyrights, resulting in several high-profile lawsuits. The legal landscape is struggling to keep pace with these rapid advancements, with ongoing debates about whether generated text might plagiarize copyrighted materials. Current LLMs may infringe on copyrights or overly restrict non-copyrighted texts, leading to these challenges: (i) the need for a comprehensive evaluation benchmark to assess copyright compliance from multiple aspects; (ii) evaluating robustness against safeguard bypassing attacks; and (iii) developing effective defenses targeted against the generation of copyrighted text. To tackle these challenges, we introduce a curated dataset to evaluate methods, test attack strategies, and propose lightweight, real-time defenses to prevent the generation of copyrighted text, ensuring the safe and lawful use of LLMs. Our experiments demonstrate that current LLMs frequently output copyrighted text, and that jailbreaking attacks can significantly increase the volume of copyrighted output. Our proposed defense mechanisms significantly reduce the volume of copyrighted text generated by LLMs by effectively refusing malicious requests. Code is publicly available at https://github.com/xz-liu/SHIELD
RoseLoRA: Row and Column-wise Sparse Low-rank Adaptation of Pre-trained Language Model for Knowledge Editing and Fine-tuning
Jun 16, 2024



Pre-trained language models, trained on large-scale corpora, demonstrate strong generalizability across various NLP tasks. Fine-tuning these models for specific tasks typically involves updating all parameters, which is resource-intensive. Parameter-efficient fine-tuning (PEFT) methods, such as the popular LoRA family, introduce low-rank matrices to learn only a few parameters efficiently. However, during inference, the product of these matrices updates all pre-trained parameters, complicating tasks like knowledge editing that require selective updates. We propose a novel PEFT method, which conducts \textbf{r}ow and c\textbf{o}lumn-wise spar\textbf{se} \textbf{lo}w-\textbf{r}ank \textbf{a}daptation (RoseLoRA), to address this challenge. RoseLoRA identifies and updates only the most important parameters for a specific task, maintaining efficiency while preserving other model knowledge. By adding a sparsity constraint on the product of low-rank matrices and converting it to row and column-wise sparsity, we ensure efficient and precise model updates. Our theoretical analysis guarantees the lower bound of the sparsity with respective to the matrix product. Extensive experiments on five benchmarks across twenty datasets demonstrate that RoseLoRA outperforms baselines in both general fine-tuning and knowledge editing tasks.
Touch100k: A Large-Scale Touch-Language-Vision Dataset for Touch-Centric Multimodal Representation
Jun 06, 2024



Touch holds a pivotal position in enhancing the perceptual and interactive capabilities of both humans and robots. Despite its significance, current tactile research mainly focuses on visual and tactile modalities, overlooking the language domain. Inspired by this, we construct Touch100k, a paired touch-language-vision dataset at the scale of 100k, featuring tactile sensation descriptions in multiple granularities (i.e., sentence-level natural expressions with rich semantics, including contextual and dynamic relationships, and phrase-level descriptions capturing the key features of tactile sensations). Based on the dataset, we propose a pre-training method, Touch-Language-Vision Representation Learning through Curriculum Linking (TLV-Link, for short), inspired by the concept of curriculum learning. TLV-Link aims to learn a tactile representation for the GelSight sensor and capture the relationship between tactile, language, and visual modalities. We evaluate our representation's performance across two task categories (namely, material property identification and robot grasping prediction), focusing on tactile representation and zero-shot touch understanding. The experimental evaluation showcases the effectiveness of our representation. By enabling TLV-Link to achieve substantial improvements and establish a new state-of-the-art in touch-centric multimodal representation learning, Touch100k demonstrates its value as a valuable resource for research. Project page: https://cocacola-lab.github.io/Touch100k/.
LIDAO: Towards Limited Interventions for Debiasing (Large) Language Models
Jun 01, 2024



Large language models (LLMs) have achieved impressive performance on various natural language generation tasks. Nonetheless, they suffer from generating negative and harmful contents that are biased against certain demographic groups (e.g., female), raising severe fairness concerns. As remedies, prior works intervened the generation by removing attitude or demographic information, inevitably degrading the generation quality and resulting in notable \textit{fairness-fluency} trade-offs. However, it is still under-explored to what extent the fluency \textit{has to} be affected in order to achieve a desired level of fairness. In this work, we conduct the first formal study from an information-theoretic perspective. We show that previous approaches are excessive for debiasing and propose LIDAO, a general framework to debias a (L)LM at a better fluency provably. We further robustify LIDAO in adversarial scenarios, where a carefully-crafted prompt may stimulate LLMs exhibiting instruction-following abilities to generate texts with fairness issue appears only when the prompt is also taken into account. Experiments on three LMs ranging from 0.7B to 7B parameters demonstrate the superiority of our method.
SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales
May 31, 2024



Large language models (LLMs) often generate inaccurate or fabricated information and generally fail to indicate their confidence, which limits their broader applications. Previous work elicits confidence from LLMs by direct or self-consistency prompting, or constructing specific datasets for supervised finetuning. The prompting-based approaches have inferior performance, and the training-based approaches are limited to binary or inaccurate group-level confidence estimates. In this work, we present the advanced SaySelf, a training framework that teaches LLMs to express more accurate fine-grained confidence estimates. In addition, beyond the confidence scores, SaySelf initiates the process of directing LLMs to produce self-reflective rationales that clearly identify gaps in their parametric knowledge and explain their uncertainty. This is achieved by using an LLM to automatically summarize the uncertainties in specific knowledge via natural language. The summarization is based on the analysis of the inconsistency in multiple sampled reasoning chains, and the resulting data is utilized for supervised fine-tuning. Moreover, we utilize reinforcement learning with a meticulously crafted reward function to calibrate the confidence estimates, motivating LLMs to deliver accurate, high-confidence predictions and to penalize overconfidence in erroneous outputs. Experimental results in both in-distribution and out-of-distribution datasets demonstrate the effectiveness of SaySelf in reducing the confidence calibration error and maintaining the task performance. We show that the generated self-reflective rationales are reasonable and can further contribute to the calibration. The code is made public at \url{https://github.com/xu1868/SaySelf}.
Optimizing Search Advertising Strategies: Integrating Reinforcement Learning with Generalized Second-Price Auctions for Enhanced Ad Ranking and Bidding
May 22, 2024



This paper explores the integration of strategic optimization methods in search advertising, focusing on ad ranking and bidding mechanisms within E-commerce platforms. By employing a combination of reinforcement learning and evolutionary strategies, we propose a dynamic model that adjusts to varying user interactions and optimizes the balance between advertiser cost, user relevance, and platform revenue. Our results suggest significant improvements in ad placement accuracy and cost efficiency, demonstrating the model's applicability in real-world scenarios.